
【Facebook人工智能 & 斯坦福大学】使用自训练提高自然语言理解的预训练 【论文标题】Self-training Improves Pre-training for Natural Language Understanding 【作者团队】Jingfei Du, Edouard Grave, Beliz Gunel, Vishrav Chaudhary, Onur Celebi, Michael Auli, Ves Stoyanov, Alexis Conneau 【发表时间】2020/10/05 【论文链接】https://arxiv.org/abs/2010.02194
【推荐理由】
本文第一个提出并证明“自训练是对自然语言理解预训练的强有力的补充”。
近年来自然语言理解的研究主要集中在无监督的预训练上。本文作者证明了自训练是另一种有效的利用未标记数据的方法。作者提供了一种新的数据扩充方法sentagment,它从一个大型的web数据语料库中检索相关句子。自训练是对一系列自然语言任务的无监督预训练的补充,它们的结合可以在强大的RoBERTa基线的基础上进一步提高。本文的增强方法带来了可伸缩和有效的自训练,在标准文本分类基准上提高了2.6%,仅需要较小样本的学习,就能获得更多的知识蒸馏。
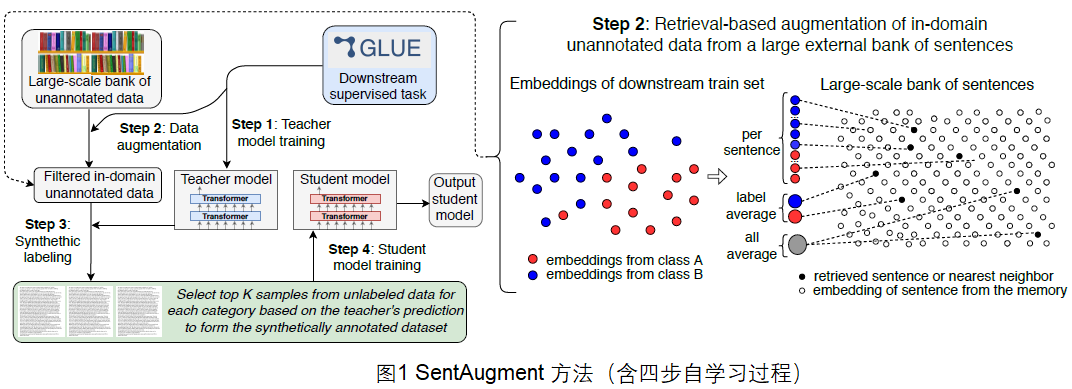
具体而言,本文的贡献如下: •本文介绍了一种用于半监督学习的数据扩充方法SentAugment,它从大量的web语句库中检索特定任务的领域内数据。 •本文表明,自训练在无监督的预训练基础上有所提高:在六个标准分类基准上将RoBERTa-Large平均提高了1.2%的准确率。 •本文表明,自训练在小样本学习上平均提高3.5%的准确率。 •对于知识提炼,本文的方法将蒸馏的RoBERTa-Large平均提高了2.9%的准确率,缩小了师生模型之间的差距。 •作者将发布代码和模型,供研究人员在其基础上工作。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢