
CodeGen2: Lessons for Training LLMs on Programming and Natural Languages
解决问题:这篇论文试图解决如何更加高效地训练大型语言模型(LLMs)以进行程序合成和理解任务的问题。同时,论文还探索了编程语言和自然语言混合数据集对模型性能的影响。
旨在通过统一四个关键组件(模型架构、学习方法、填充采样和数据分布),使大型语言模型(LLM)在代码合成方面的训练更加高效。提出了一个简单且统一的学习算法,探索了多种数据分布对模型性能的影响。最终,提供了一个完整的训练方案和一系列开源的LLM模型。
-
动机:为了使大型语言模型(LLM)在代码合成方面的训练更加高效,试图通过统一四个关键组件来实现。 -
方法:提出一个简单且统一的学习算法,探索了多种数据分布对模型性能的影响。 -
优势:提供了一个完整的训练方案和一系列开源的LLM模型,以更好地支持相关研究。
关键思路:论文提出了一种将编码器和解码器模型统一为单一前缀-LM的模型架构,并将因果语言建模、跨度损坏和填充等学习方法统一为一个简单的学习算法。此外,论文还探讨了“免费午餐”假设下的填充采样的效果,以及编程语言和自然语言混合数据集对模型性能的影响。
其他亮点:论文通过对1B LLMs进行全面的实验,总结出了四个经验教训,并提供了训练框架和开源Codegen2模型,包括1B、3.7B、7B和16B参数大小的模型。
E Nijkamp, H Hayashi, C Xiong, S Savarese, Y Zhou
[Salesforce Research]
相关研究:近期的相关研究包括:《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》(Yin et al.,Google Research)、《Turing Natural Language Generation Benchmark: Evaluating Language Generation in Generative Dialog Systems with Human Evaluation》(Dusek et al.,Charles University)、《Reformer: The Efficient Transformer》(Kitaev et al.,Google Research)等。
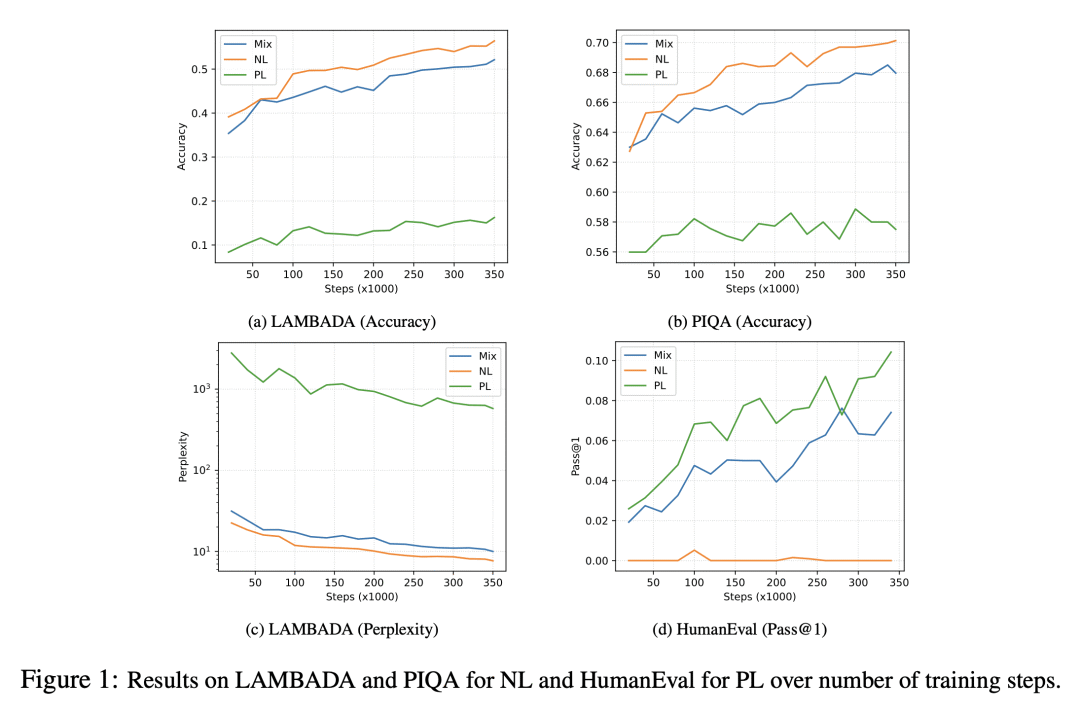
论文摘要:本研究旨在通过统一四个关键组成部分:(1)模型架构,(2)学习方法,(3)插值采样和(4)数据分布,使LLMs的程序合成训练更加高效。具体而言,对于模型架构,我们尝试将编码器和解码器模型统一为单个前缀LM。对于学习方法,我们将因果语言建模、跨度损坏和插值统一为一个简单的学习算法。对于插值采样,我们探讨了“免费午餐”假设的影响。关于数据分布,我们研究了编程语言和自然语言混合分布对模型性能的影响。我们在1B LLMs上进行了全面的实证实验,将探索中的失败和成功总结为四个教训。我们将提供最终的训练配方,并发布1B、3.7B、7B和16B参数的CodeGen2模型,以及训练框架作为开源:https://github.com/salesforce/CodeGen2。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢