
LLaMA模型的开源复现,在RedPajama数据集上训练,使用了与LLaMA相同的预处理步骤和超参数,模型结构,上下文长度,训练步骤,学习率调度和优化器。OpenLLaMA的PyTorch和Jax权重可以在Huggingface Hub上获得。OpenLLaMA在各种任务中展现出与LLaMA和GPT-J相似的表现,部分任务表现优异。
这是UC Berkeley的博士生Hao Liu发起的一个开源LLaMA复刻项目。
OpenLLaMA: An Open Reproduction of LLaMA
「我们发布了Meta AI的LLaMA大型语言模型的许可开源复制。在这个版本中,我们将发布7B OpenLLaMA模型的公开预览,该模型已经用2000亿个令牌进行了训练。我们提供预训练OpenLLaMA模型的PyTorch和Jax权重,以及评估结果和与原始LLaMA模型的比较。」
5月3日,OpenLLaMA发布第一个训练结果,即OpenLLaMA 7B模型,70亿参数版本的模型,基于2000亿tokens的RedPajama数据集训练。使用Google的TPU-v4s和EasyLM进行训练。模型提供JAX和PyTorch两个版本的预训练结果。训练过程中的损失函数如下:
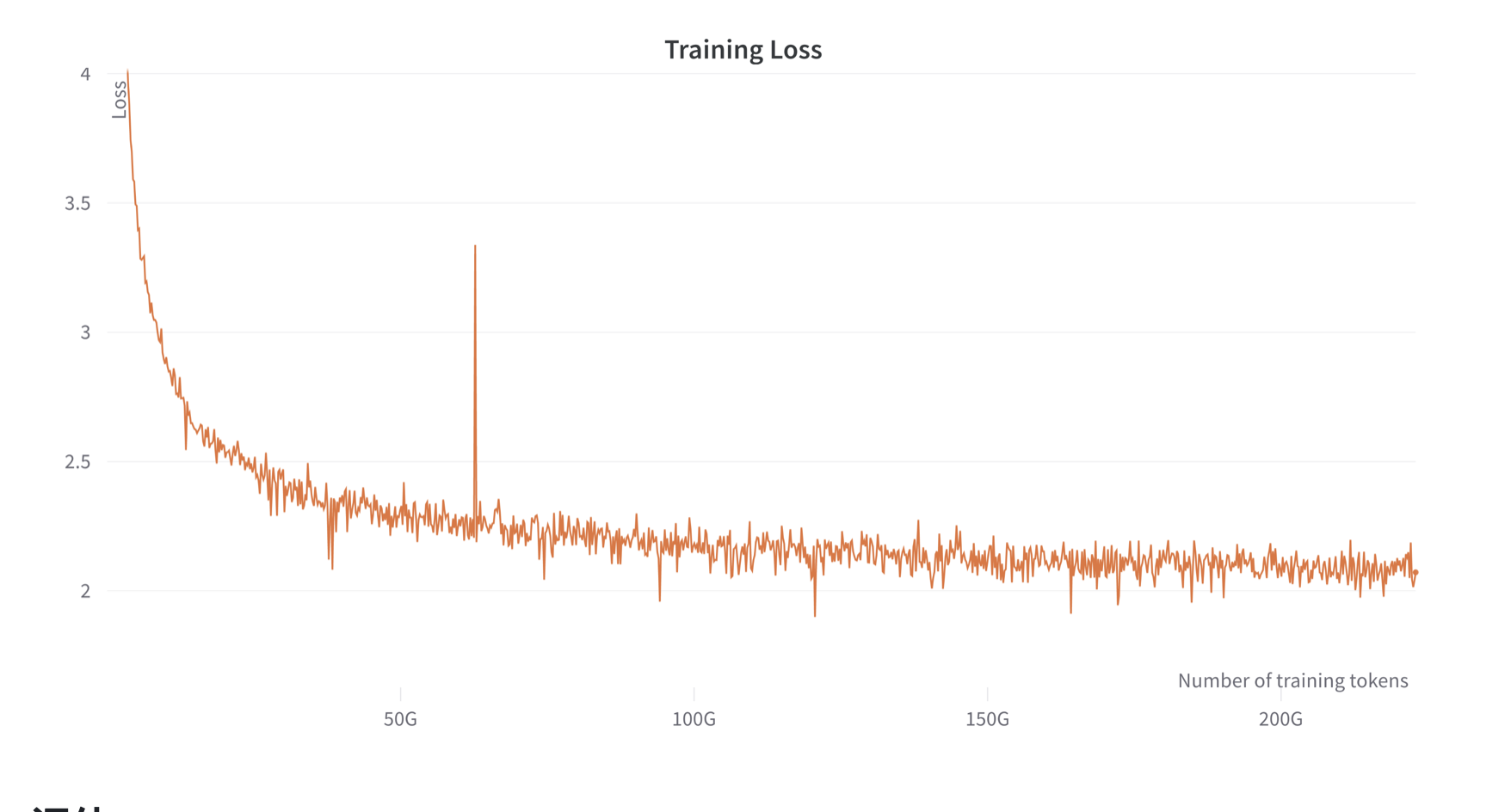
评估
我们使用lm-evaluation-harness评估了OpenLLaMA的各种任务。LLaMA结果是通过在相同的评估指标上运行原始LLaMA模型生成的。我们注意到,我们关于LLaMA模型的结果与最初的LLaMA论文略有不同,我们认为这是不同评估协议的结果。在lm-evaluation-harness这个问题上也报告了类似的差异。此外,我们介绍了GPT-J的结果,这是一个由EleutherAI在Pile数据集上训练的6B参数模型。
最初的LLaMA模型接受了1万亿个代币的训练,GPT-J接受了5000亿个代币的训练,而OpenLLaMA接受了2000亿个代币的训练。我们在下表中列出了结果。OpenLLaMA在大多数任务中表现出与原始LLaMA和GPT-J相当的性能,并且在某些任务中表现优于它们。我们预计,在完成1万亿代币的培训后,OpenLLaMA的性能将进一步提高。
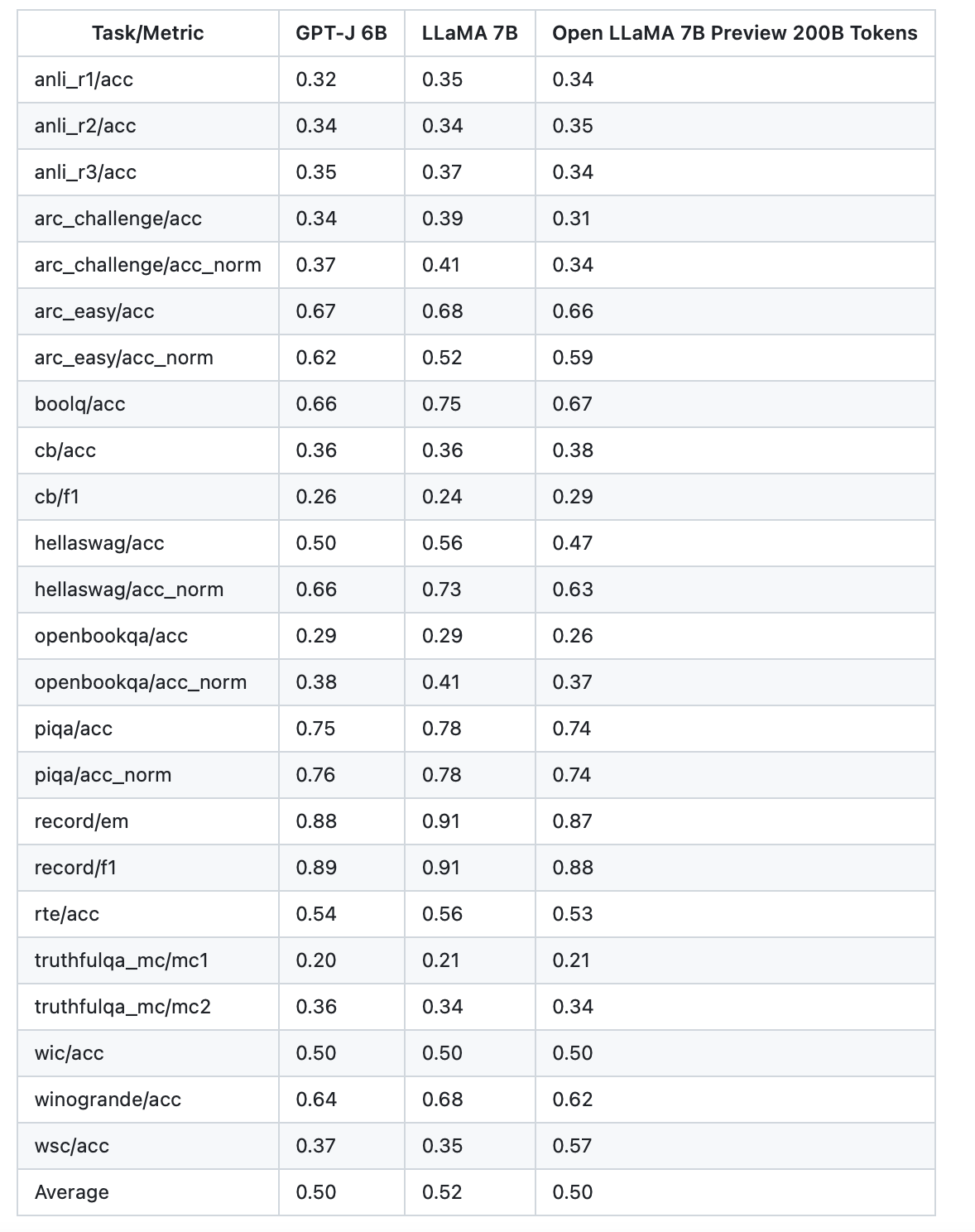
其中GPT-J 6B是EleutherAI研究小组创建的开源自回归语言模型。它是OpenAI的GPT-3的最先进替代品之一,在各种自然语言任务(如聊天、摘要和问答等)方面表现良好。"GPT-J"指的是模型类别,而"6B"表示可训练参数的数量为60亿。在5000亿tokens的Pile数据集上训练,而原始的LLaMA则是在1万亿tokens数据集训练,此次发布的OpenLLaMA 7B预览版则是基于2000亿tokens数据的RedPajama数据集训练。从上面的结果看,这三个模型效果似乎差不多。但是,OpenLLaMA模型将会继续训练,直到完成在1万亿tokens上的训练,预期最终结果会更好。
OpenLLaMA的开源协议
由于OpenLLaMA 7B完全从头开始训练,因此无需获取原始的LLaMA权重,也不需要遵从LLaMA相关的协议。目前官方说法是这个预览版的预训练结果和训练框架都是基于Apache 2.0协议开源。因此商用友好。不过需要注意的是,未来正式版本是否有变更还不确定。
OpenLLaMA 7B最终将完成基于1万亿的RedPajama数据集上的训练,并且同时进行的还有一个3B的模型。
由于OpenLLaMA 7B完全从头开始训练,因此无需获取原始的LLaMA权重,也不需要遵从LLaMA相关的协议。目前官方说法是这个预览版的预训练结果和训练框架都是基于Apache 2.0协议开源。因此商用友好。不过需要注意的是,未来正式版本是否有变更还不确定。
关于伯克利人工智能研究实验室(Berkeley Artificial Intelligence Research,简称BAIR)是加州大学伯克利分校(UC Berkeley)下属的一家领先的人工智能研究组织。
成立于2016年,BAIR致力于推进人工智能领域的基础研究和应用发展,旨在通过自主创新和跨学科合作,解决AI领域面临的核心挑战。BAIR的研究方向非常广泛,涵盖了机器学习、计算机视觉、自然语言处理、机器人学等多个子领域。
代表成果
Caffe:Caffe是一个由BAIR开发的开源深度学习框架,它提供了高性能的计算效率和易用性。Caffe在计算机视觉和图像处理领域尤为受欢迎,广泛应用于图像分类、目标检测等任务。Caffe框架的出现为研究人员和工程师提供了一个便利的工具,使得深度学习技术的实现和应用变得更加简单高效。
RLLab:RLLab是一个开源的强化学习研究平台,旨在为研究人员提供一个方便、可扩展的环境,以进行强化学习算法的实验和研究。RLLab的出现极大地推动了强化学习领域的发展,为研究人员提供了一个实验和验证算法的重要平台。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢