

本项目开源了基于ChatGLM-6B LoRA 16-bit指令微调的中文医疗通用模型。基于共计28科室的中文医疗共识与临床指南文本,我们生成医疗知识覆盖面更全,回答内容更加精准的高质量指令数据集。以此提高模型在医疗领域的知识与对话能力。
论文地址:https://arxiv.org/pdf/2304.01097.pdf
项目地址:https://github.com/MediaBrain-SJTU/MedicalGPT-zh
情景对话
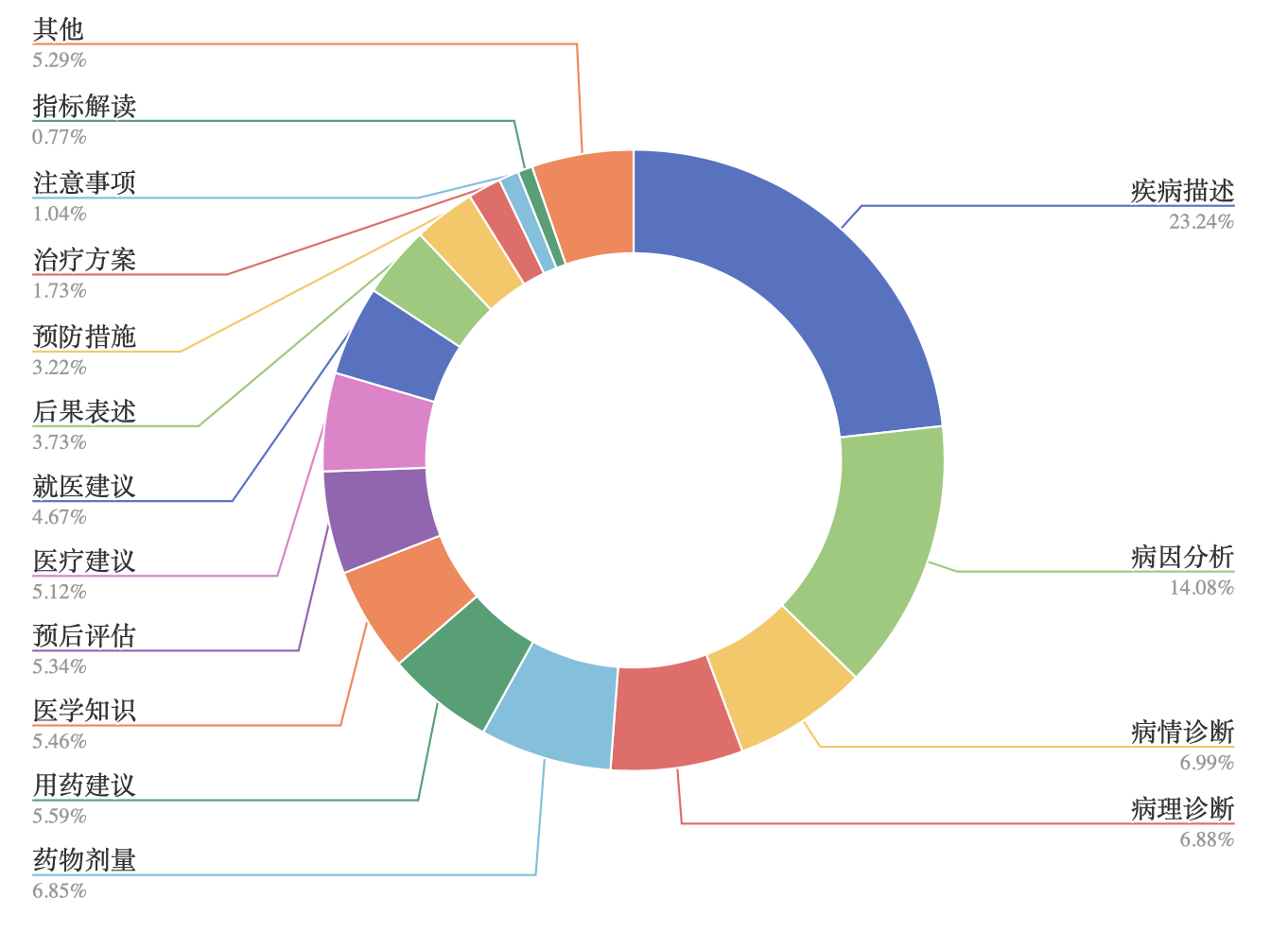
主要参考BELLE的指令数据集生成方式,我们将医学指令按照诊疗情景的不同主要分为16种大类,通过100条情景对话种子任务生成的52k条情景对话数据。 情景对话种子任务详见./data/dialogue_seed_task.json。此外,我们还提供了生成情景对话数据的pipeline./data/dialogue_generation.py。最终生成的52k情景对话数据医学指令类型及其分布如下图所示。
知识问答
医学知识来源于我们自建的医学数据库。通过提供具体的医疗共识与临床指南文本,先让ChatGPT生成与该段医学知识内容与逻辑关系相关的若干问题,再通过“文本段-问题”对的方式让ChatGPT回答问题,从而使ChatGPT能够生成含有医学指南信息的回答,保证回答的准确性。知识问答与医疗指南的例子详见./data/book_data.json,依据医疗指南生成的知识问答样例详见./data/book_based_qa.json。此外,我们还提供了知识问答数据生成的pipeline./data/book_based_question_generation.py。
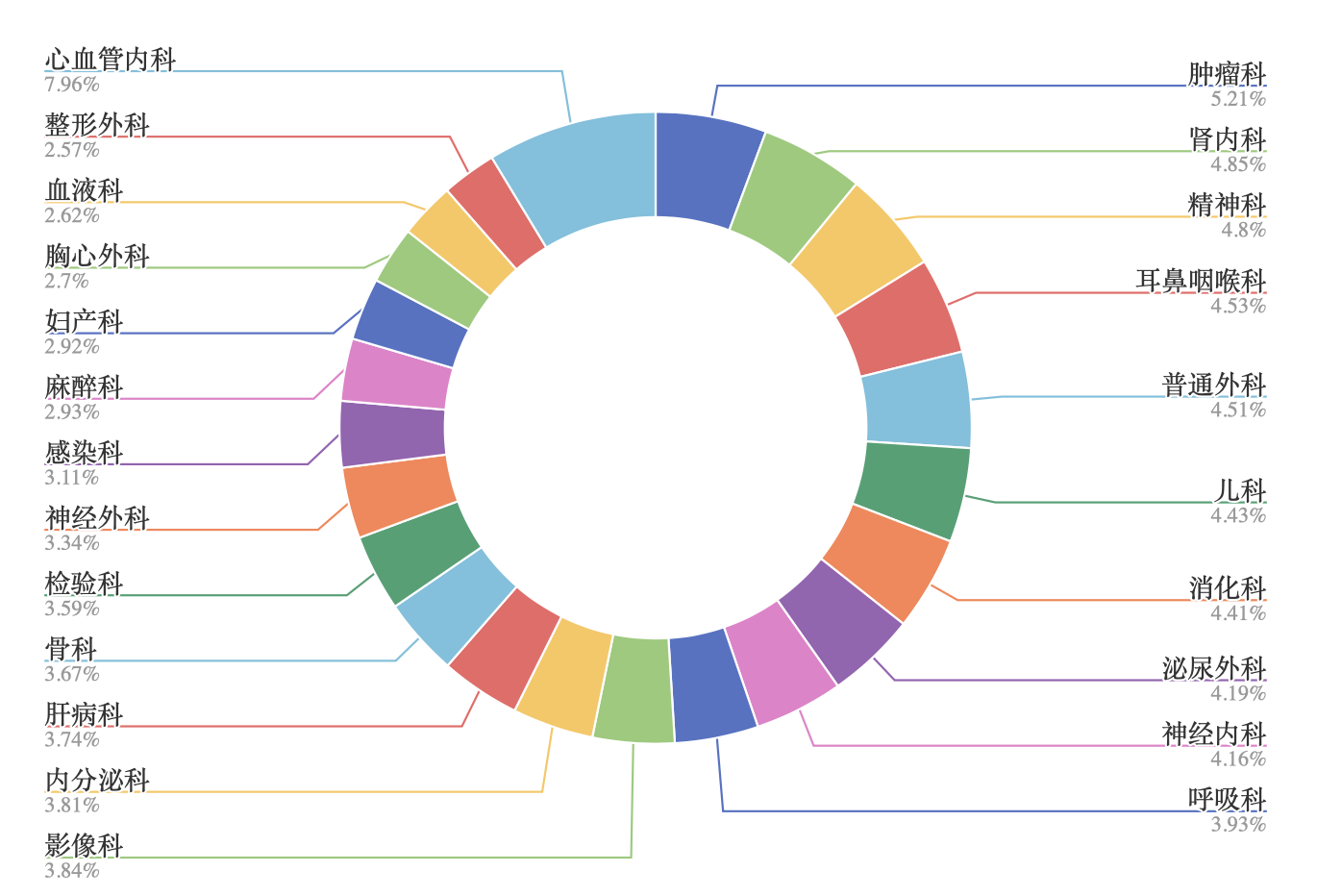
其中,医疗共识与临床指南中文本段涵盖28个科室共计32k个文本段。各科室及其分布如下
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢