
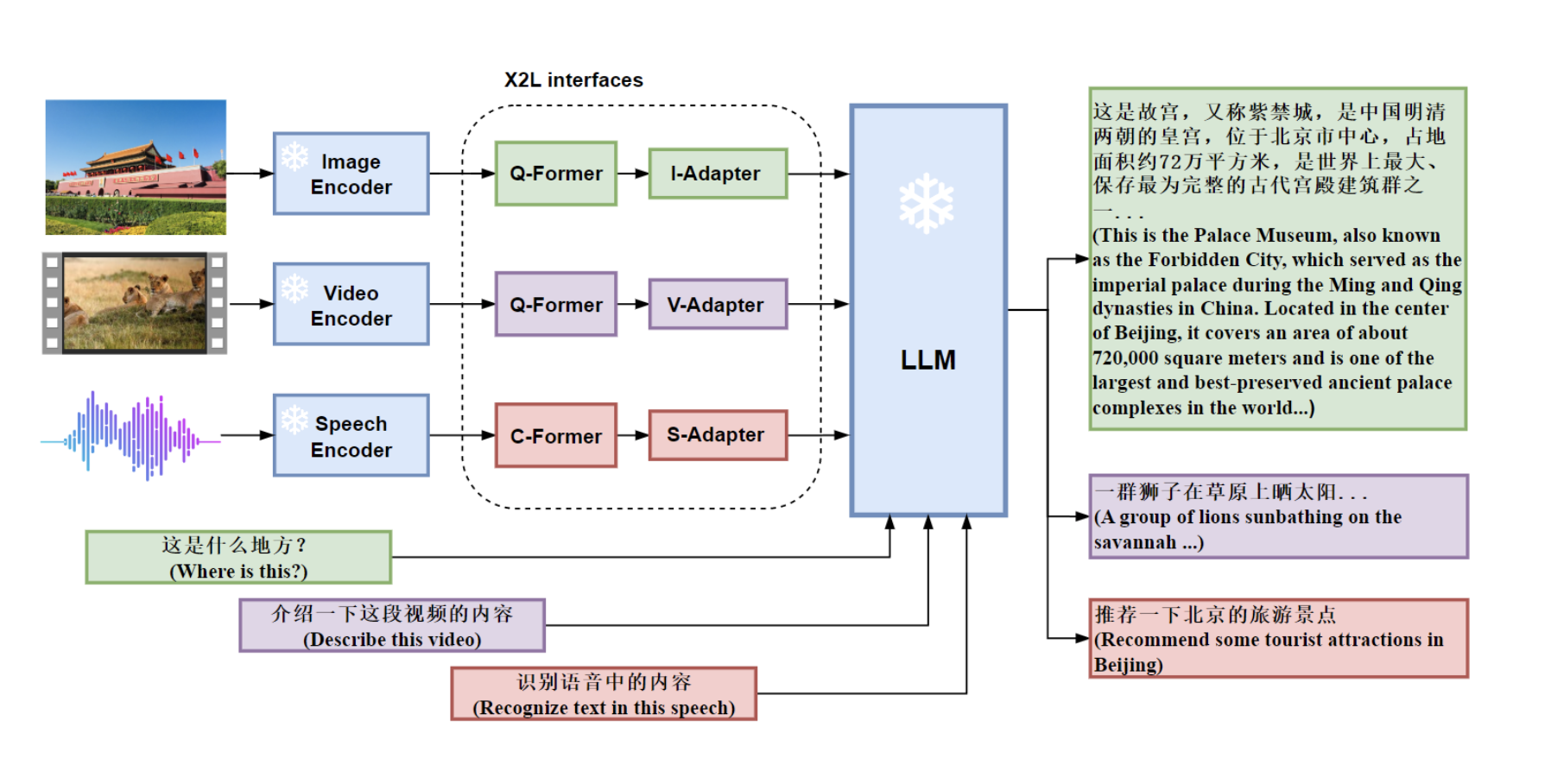
大型语言模型(LLM)表现出了非凡的语言能力。GPT-4基于高级LLM,在以前的视觉语言模型之外展示了非凡的多模态能力。与以前的多式联运模型相比,我们归因于使用更先进的LLM。不幸的是,GPT-4的模型架构和训练策略还不得而知。为了赋予LLM多模态功能,我们提出X-LLM,它使用X2L接口将多模态(图像、语音、视频)转换为外语,并将其输入到大型语言模型(ChatGLM)中。
Feilong Chen, Minglun Han, Haozhi Zhao, Qingyang Zhang, Jing Shi, Shuang Xu, Bo Xu
论文地址:https://arxiv.org/abs/2305.04160
- 多式联运大模型框架。我们提出X-LLM,一种多模态LLM,通过X2L接口向LLM注入多种模式(如图像、语音和视频),使LLM能够处理多模态数据。这种方法具有良好的可扩展性,可以扩展到更多模式。
- 英语图像-文本对齐模块中参数的可转移性。我们发现,受过英语图像文本数据训练的Q-former模块可以传输到其他语言。在我们的实验中,我们成功地将模型参数从印欧英语转移到了汉藏汉语。语言的可转移性大大提高了使用英语图像文本数据及其训练模型参数的可能性,并提高了其他语言的多模态法学硕士培训效率。
- 表演。我们将X-LLM与LLaVA和MiniGPT-4进行了比较,以处理中国元素的视觉输入的能力,并发现X-LLM的表现明显优于它们。我们还对将LLM用于ASR和多模式ASR进行了定量测试,希望促进基于LLM的语音识别时代。
- 开源。我们将很快公开多模态指令调优数据、我们的模型和代码库。
X-LLM使用X2L接口将多模式(图像、语音、视频)转换为外语,并将其输入大型语言模型(ChatGLM),以完成多模式LLM,实现令人印象深刻的多模式聊天功能。
具体来说,X-LLM使用X2L接口对齐多个冻结单模态编码器和冻结LLM,其中“X”表示图像、语音和视频等多模式,“L”表示语言。
X-LLM预训练包括三个阶段:
(1)转换多模态信息:第一阶段训练每个X2L接口与各自的单模态编码器单独对齐,以将多模态信息转换为语言。
(2)将X2L表示与LLM对齐:单模态编码器通过X2L接口独立与LLM对齐。
(3)集成多种模式:所有单模态编码器都通过X2L接口与LLM对齐,以将多模态功能集成到LLM中。我们的实验表明,X-LLM展示了令人印象深刻的多模型聊天能力,有时在看不见的图像/指令上表现出多模态GPT-4的行为,并且与GPT-4相比,在合成多模态指令跟踪数据集上产生了84.5\%的相对分数。我们还对将LLM用于ASR和多模式ASR进行了定量测试,希望促进基于LLM的语音识别时代。
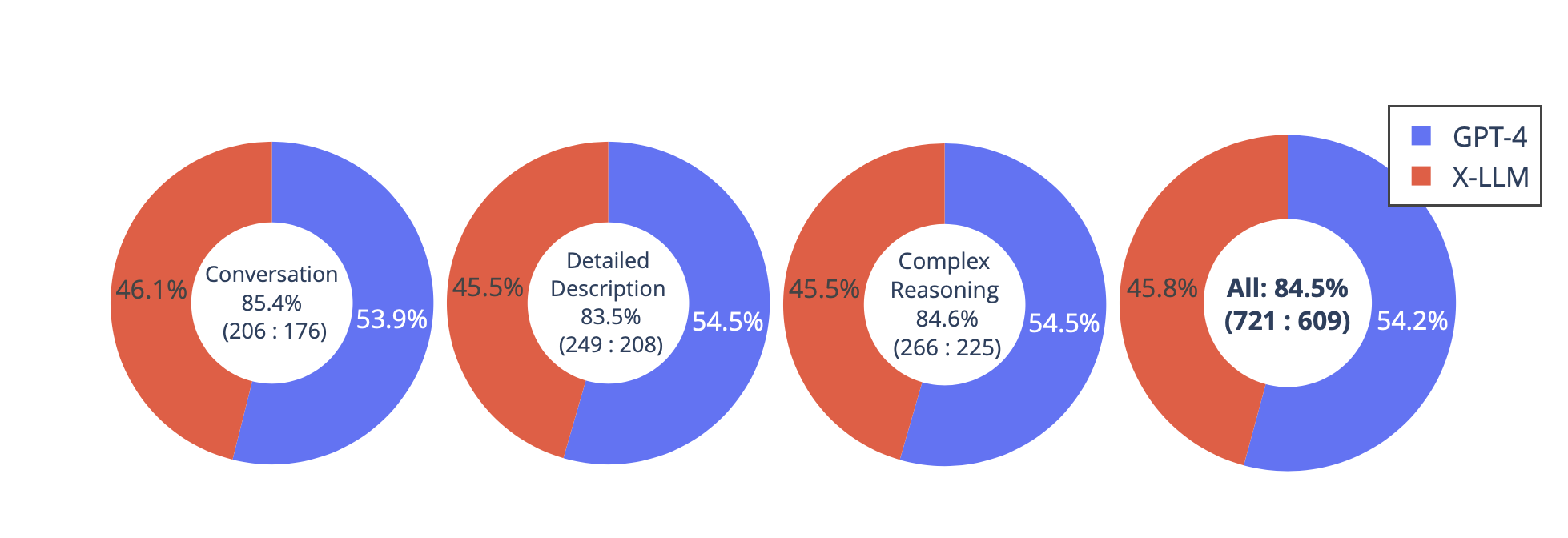
构建了一个包含30个看不见图像的评估数据集:每个图像都附有三种类型的指令:对话、详细描述和复杂的推理。这导致了90个新的语言图像指令,我们在上面测试X-LLM和GPT-4,并使用ChatGPT从1分到10分对他们的回复进行评分。报告了每种类型的总分和和相对分数。总体而言,与GPT-4相比,X-LLM的相对得分为84.5%,这表明了拟议方法在多式联运设置中的效果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢