
Meta宣布了一个新的开源人工智能模型,上线一天突破1k星。
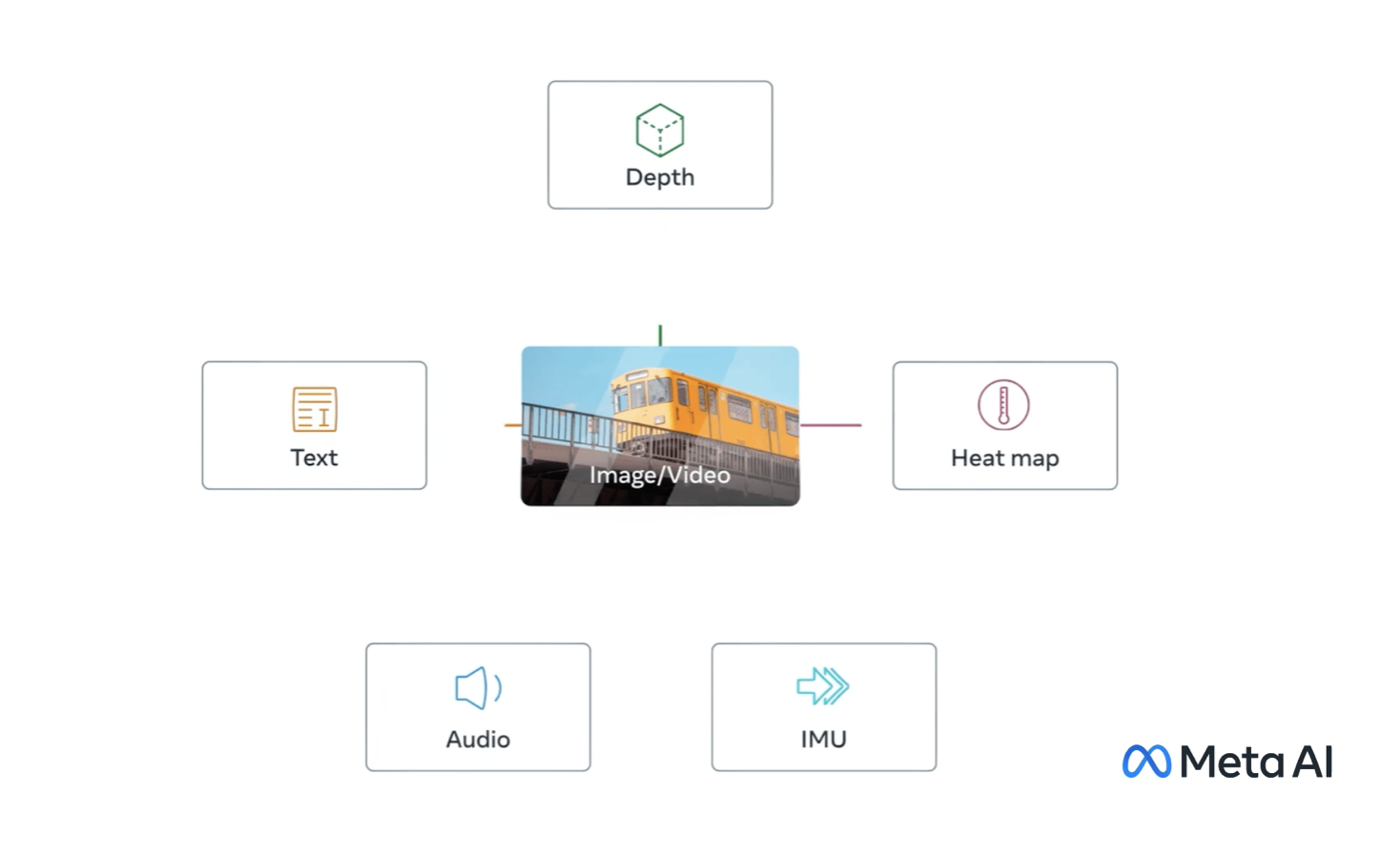
新的ImageBind模型结合了文本、音频、视觉、运动、热和深度数据。
该模型目前只是一个研究项目,展示了未来的人工智能模型如何能够生成多感官内容。通过利用多种类型的图像配对数据来学习单个共享表示空间。该研究不需要所有模态相互同时出现的数据集,相反利用到了图像的绑定属性,只要将每个模态的嵌入与图像嵌入对齐,就会实现所有模态的迅速对齐。Meta AI 还公布了相应代码。
没有即时的消费者或实际应用,但它指出了生成人工智能系统的未来,这些系统可以创造身临其境的多感官体验,并表明在OpenAI和谷歌等竞争对手变得越来越神秘的时候,Meta继续分享人工智能研究。
论文地址:https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
GIT地址:https://github.com/facebookresearch/ImageBind
研究的核心概念是将多种类型的数据链接到一个单一的多维索引(或“嵌入空间”,使用人工智能用语)。这个想法可能看起来有点抽象,但正是这个概念支撑了最近生成人工智能的蓬勃发展。

当人类从世界吸收信息时,我们天生就使用多种感官,例如看到繁忙的街道和听到汽车发动机的声音。今天,我们正在引入一种方法,使机器更接近人类同时、全面和直接从许多不同形式的信息中学习的能力——而不需要明确的监督(组织和标记原始数据的过程)。我们已经构建并正在开源ImageBind,这是第一个能够绑定六种模式信息的人工智能模型。该模型学习单个嵌入或共享表示空间,不仅用于文本、图像/视频和音频,还用于记录深度(3D)、热(红外辐射)和惯性测量单位(IMU)的传感器,这些单位可以计算运动和位置。ImageBind为机器配备了全面的理解,将照片中的物体与它们的声音、3D形状、温暖或寒冷以及它们如何移动联系起来。
正如我们的论文所描述的,ImageBind可以优于之前针对一种特定模式单独训练的专家模型。但最重要的是,它使机器能够更好地一起分析许多不同形式的信息,从而帮助推进人工智能。例如,使用ImageBind,Meta的Make-A-Scene可以从音频创建图像,例如根据雨林或繁华市场的声音创建图像。其他未来的可能性包括更准确的识别、连接和审核内容的方法,以及促进创意设计,例如更无缝地生成更丰富的媒体,并创建更广泛的多模式搜索功能。ImageBind是Meta创建多模态人工智能系统努力的一部分,这些系统从周围所有可能的数据类型中学习。随着模式数量的增加,ImageBind为研究人员打开了闸门,试图开发新的整体系统,例如结合3D和IMU传感器来设计或体验身临其境的虚拟世界。
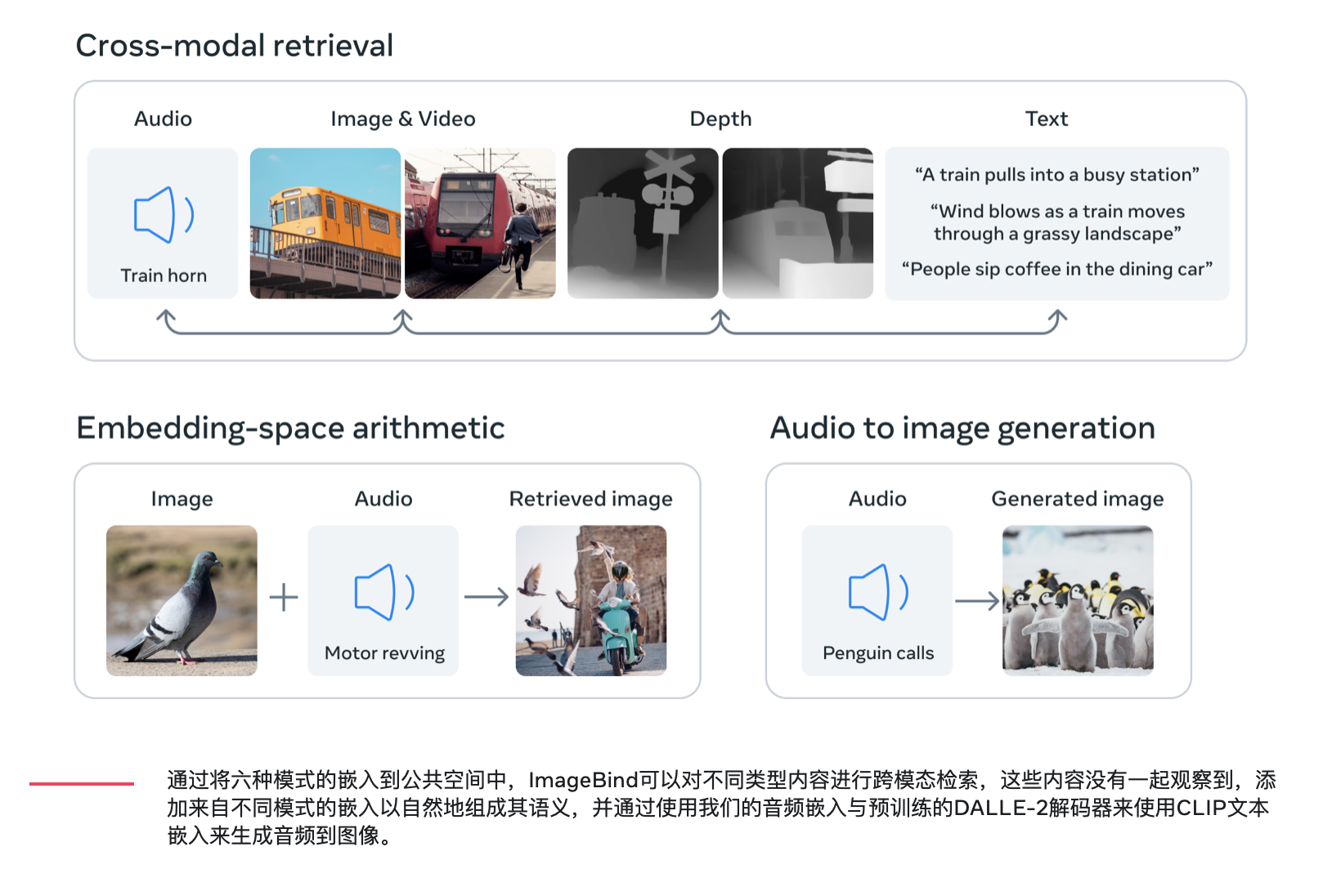
ImageBind还可以提供一种丰富的方式来探索记忆——使用文本、音频和图像的组合来搜索图片、视频、音频文件或短信。在典型的人工智能系统中,每个各自的模式都有一个特定的嵌入(即可以表示数据及其在机器学习中关系的数字向量)。ImageBind表明,可以跨多种模式创建联合嵌入空间,而无需使用每种不同的模式组合对数据进行训练。
这很重要,因为研究人员使用样本创建数据集是不可行的,例如,包含来自繁忙城市街道的音频数据和热数据,或深度数据和海滨悬崖的文本描述。正如最近在从文本(如Make-A-Scene和Meta的Make-A-Video)生成图像、视频和音频方面取得了令人兴奋的进展一样,ImageBind的多模态功能可以允许研究人员使用其他模式作为输入查询并检索其他格式的输出。ImageBind也是构建可以像人类一样全面分析不同类型数据的机器的重要一步。
通过将六种模式的嵌入到公共空间中,ImageBind可以对不同类型内容进行跨模态检索,这些内容没有一起观察到,添加来自不同模式的嵌入以自然地组成其语义,并通过使用我们的音频嵌入与预训练的DALLE-2解码器来使用CLIP文本嵌入来生成音频到图像。
ImageBind是一个多模态模型,加入了Meta最近一系列开源人工智能工具。这包括计算机视觉模型,如DINOv2,一种不需要微调训练高性能计算机视觉模型的新方法,以及Segment Anything(SAM),一种通用分段模型,可以根据任何用户提示分任何图像中的任何对象。ImageBind对这些模型相辅相成,因为它专注于多模态表示学习。它试图为多种模式学习单个对齐功能空间,包括但不限于图像和视频。未来,ImageBind可以利用DINOv2强大的视觉功能来进一步提高其功能。
通过将内容与图像绑定来学习单个嵌入空间
人类有能力只从少数例子中学习新概念。我们通常可以阅读对动物的描述,然后在现实生活中识别它。我们还可以查看一张不熟悉的汽车模型的照片,并预测其发动机的声音。部分原因是,事实上,单个图像可以“绑定”整个感官体验。然而,在人工智能领域,随着模式数量的增加,缺乏多个感官数据可能会限制依赖配对数据的标准多模态学习。理想情况下,单个联合嵌入空间——其中分布着许多不同类型的数据——可以允许模型学习视觉特征以及其他模式。以前,学习所有模式的这种联合嵌入空间需要收集所有可能的配对数据组合——这是一个不可行的壮举。
ImageBind利用最近的大规模视觉语言模型,将其零拍能力扩展到新的模式,只需使用它们与图像的自然配对,如视频音频和图像深度数据,来学习单一的联合嵌入空间,从而规避了这一挑战。对于四种额外的模式(音频、深度、热和IMU读数),我们使用自然配对的自我监督数据。由于互联网上有大量的图像和并发文本,培训图像-文本模型已经得到了广泛的研究。ImageBind使用图像的绑定特性,这意味着它们与各种方式同时发生,并可以作为连接它们的桥梁,例如使用网络数据将文本链接到图像,或使用带有IMU传感器的可穿戴相机捕获的视频数据将运动链接到视频。从大规模网络数据中学到的视觉表示可以作为学习不同模式特征的目标。这允许ImageBind对齐与图像同时发生的任何模式,自然地将这些模式相互对齐。与图像有强烈相关性的模式,如热和深度,更容易对齐。
不可见的模式,如音频和IMU,相关性较弱。考虑到有一些特定的声音,比如婴儿的哭声,可以伴随任何数量的视觉背景。ImageBind表明,图像配对数据足以将这六种模式结合在一起。该模型可以更全面地解释内容,允许不同的模式相互“交谈”,并在不一起观察的情况下找到链接。例如,ImageBind可以在不看到音频和文本的情况下将它们关联起来。这使得其他模型能够在没有任何资源密集型培训的情况下“理解”新模式。ImageBind的强缩放行为允许模型通过使许多人工智能模型使用其他模式来替代或增强它们。例如,虽然Make-A-Scene可以使用文本提示生成图像,但ImageBind可以将其升级为使用音频声音(如笑声或雨)生成图像。
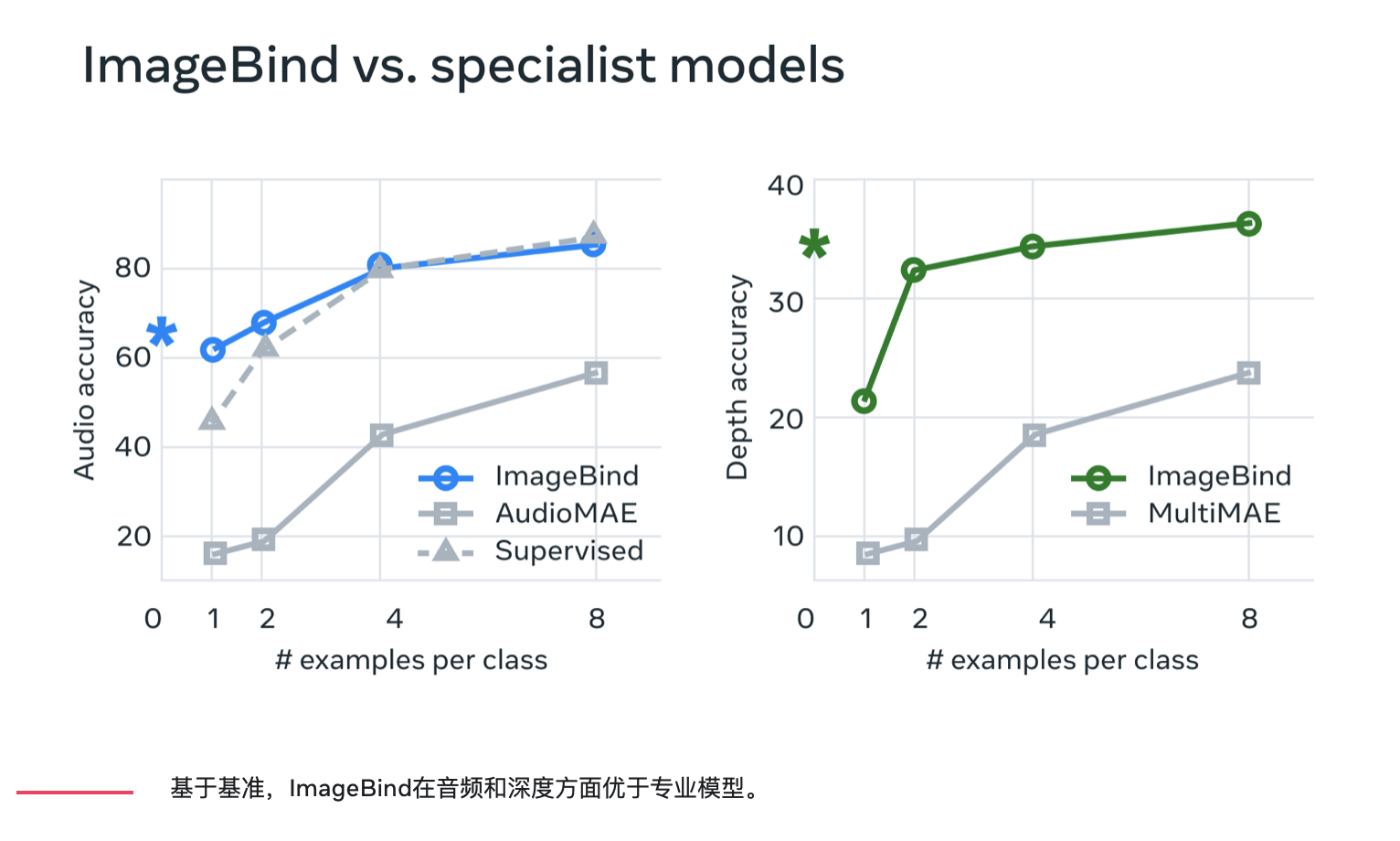
基于基准,ImageBind在音频和深度方面优于专业模型。
Meta 发现 ImageBind 可以用于少样本音频和深度分类任务,并且优于之前定制的方法。例如,ImageBind 明显优于 Meta 在 Audioset 上训练的自监督 AudioMAE 模型,以及在音频分类上微调的监督 AudioMAE 模型。
多式联运学习的未来
凭借使用多种模式进行输入查询和跨其他模式检索输出的能力,ImageBind为创作者提供了新的可能性。想象一下,有人可以拍摄海洋日落的视频记录,并立即添加完美的音频剪辑来增强它,而brindle Shih Tzu的图像可以产生类似狗的论文或深度模型。或者,当像Make-A-Video这样的模型制作狂欢节的视频时,ImageBind可以建议背景噪音来伴随它,创造身临其境的体验。
人们甚至可以基于音频分割和识别图像中的对象。这创造了独特的机会,通过将静态图像与音频提示相结合来创建动画。例如,创建者可以将图像与闹钟和公鸡鸣耦合,并使用鸣叫音频提示来分割公鸡或闹钟的声音来分割时钟,并将两者都动画化成视频序列。虽然我们在目前的研究中探索了六种模式,但我们相信引入连接尽可能多的感官的新模式——如触摸、语音、嗅觉和大脑fMRI信号——将使以人为中心的人工智能模型更丰富。关于多模式学习,还有很多东西需要揭示。人工智能研究界尚未有效地量化仅出现在更大模型中的缩放行为,并了解其应用。ImageBind是以严格方式评估它们并展示图像生成和检索中新应用的一步。我们希望研究界将探索ImageBind和我们随附的已发表论文,以找到评估视觉模型的新方法,并导致新的应用。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢