
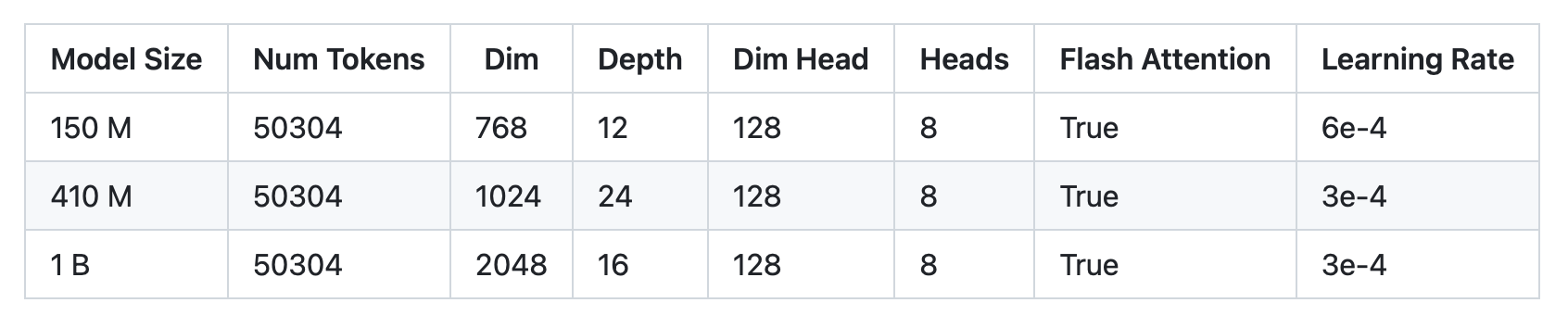
谷歌未开源的PaLM,一位开发者在GitHub上开源了三种微缩版的PaLM模型:参数分别为1.5亿(PalM-150m),4.1亿(PalM-410m)和10亿(PalM-1b)。
项目地址:https://github.com/conceptofmind/PaLM

这三种模型在谷歌C4数据集进行了训练,上下文长度为8k。未来,还有20亿参数的模型正在训练中。
开源的PaLM模型通过Flash Attention、 Xpos Rotary Embeddings进行训练,从而实现了更好的长度外推,并使用多查询单键值注意力机制进行更高效的解码。
在优化算法方面,采用的则是解耦权重衰减Adam W,但也可以选择使用Mitchell Wortsman的Stable Adam W。
如果模型无法从Torch hub正确下载,请务必清除 .cache/torch/hub/ 中的检查点和模型文件夹。如果问题仍未解决,那么你可以从Huggingface的仓库下载文件。目前,Huggingface 的整合工作正在进行中。
所有的训练数据都已经用GPTNEOX标记器进行了预标记,并且序列长度被截止到8192。这将有助于节省预处理数据的大量成本。
这些数据集已经以parquet格式存储在Huggingface上,你可以在这里找到各个数据块:C4 Chunk 1,C4 Chunk 2,C4 Chunk 3,C4 Chunk 4,以及C4 Chunk 5。
在分布式训练脚本中还有另一个选项,不使用提供的预标记C4数据集,而是加载和处理另一个数据集,如 openwebtext。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢