
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
研究了使用大型语言模型(LLM)的成本问题,提出三种实用策略来降低使用LLM的推理成本,并通过FrugalGPT例子说明了一种可行的策略——LLM级联,可以在保证性能的同时将成本降低高达98%或提高4%的准确性。
-
动机:使用大型语言模型的成本问题是限制其广泛使用的重要障碍。 -
方法:研究了三种降低LLM推理成本的实用策略,提出了FrugalGPT作为LLM级联策略的例子。 -
优势:FrugalGPT可以在保持性能的同时将成本降低高达98%或提高4%的准确性。
解决问题:该论文旨在解决使用大型语言模型(LLMs)进行查询和文本处理时的高昂成本问题,并提出了三种策略来降低推理成本。
关键思路:论文中提出了三种策略来降低LLMs的推理成本,包括提示适应、LLM近似和LLM级联。论文还提出了FrugalGPT,它是LLM级联的一种简单而灵活的实例,可以学习在不同查询中使用哪些LLMs的组合以降低成本并提高准确性。与当前领域的研究相比,该论文提出了一种新的使用LLMs的可持续和高效方法。
其他亮点:
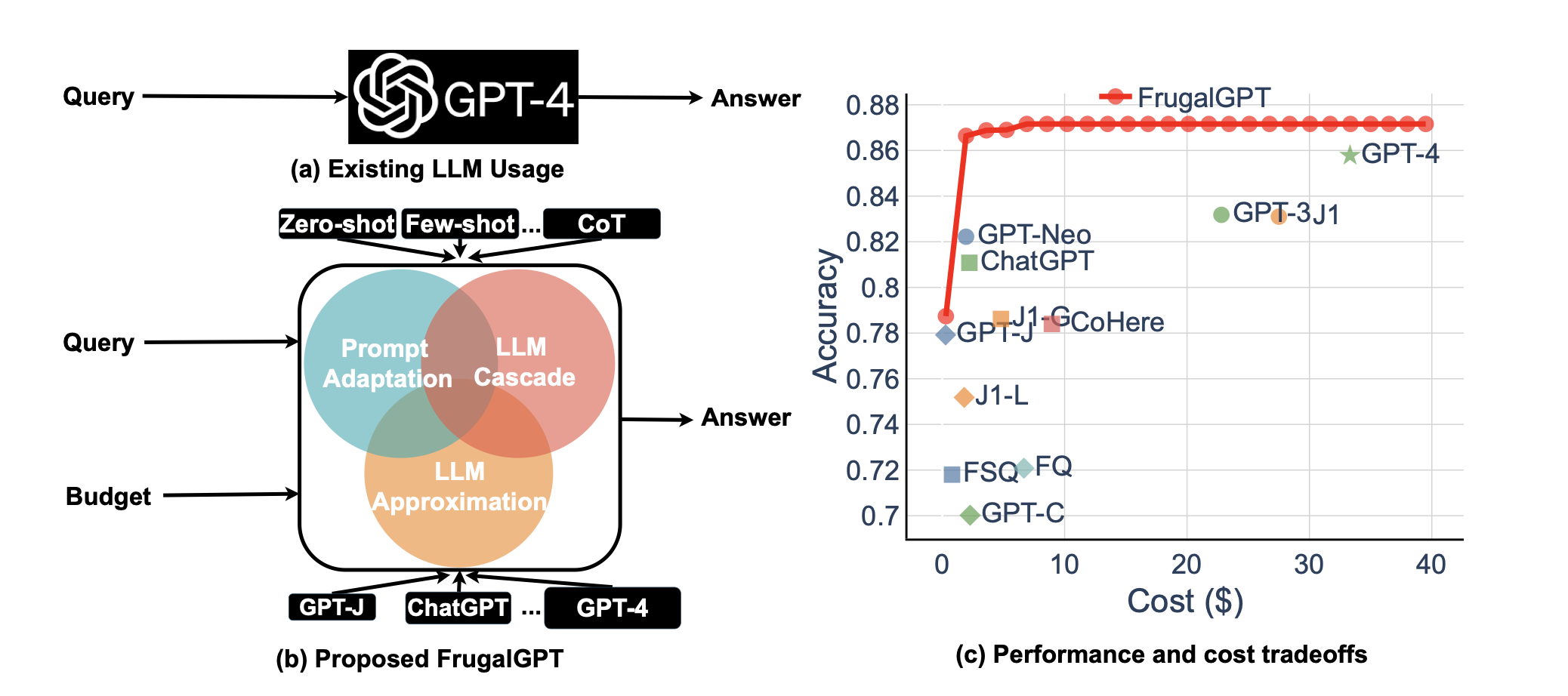
该论文的实验表明,FrugalGPT可以在减少成本的同时与最佳单个LLM(例如GPT-4)的性能相匹配,或者在相同成本下比GPT-4的准确性提高4%。
该论文还提供了一种新的使用LLMs的方法,为该领域的进一步研究提供了基础。
关于作者:Lingjiao Chen、Matei Zaharia和James Zou是该论文的主要作者。
Lingjiao Chen是斯坦福大学计算机科学系的助理教授,其代表作包括“Neural Program Synthesis with Priority Queue Training”;Matei Zaharia是斯坦福大学计算机科学系和Databricks的助理教授,其代表作包括“Apache Spark: A Unified Engine for Big Data Processing”;James Zou是斯坦福大学生物医学工程和计算机科学系的助理教授,其代表作包括“Probabilistic Modeling in Genomics”。
相关研究:近期其他相关的研究包括:“Optimizing Cost and Performance of Transformer Models for Large-Scale Neural Machine Translation”(作者:Rui Wang、Derek F. Wong、Lidia S. Chao,机构:University of Macau)和“Efficient Large-Scale Language Model Training on GPUs with Megatron-LM”(作者:Sho Takase、Naruya Saitou、Makoto Morishita,机构:The University of Tokyo)。
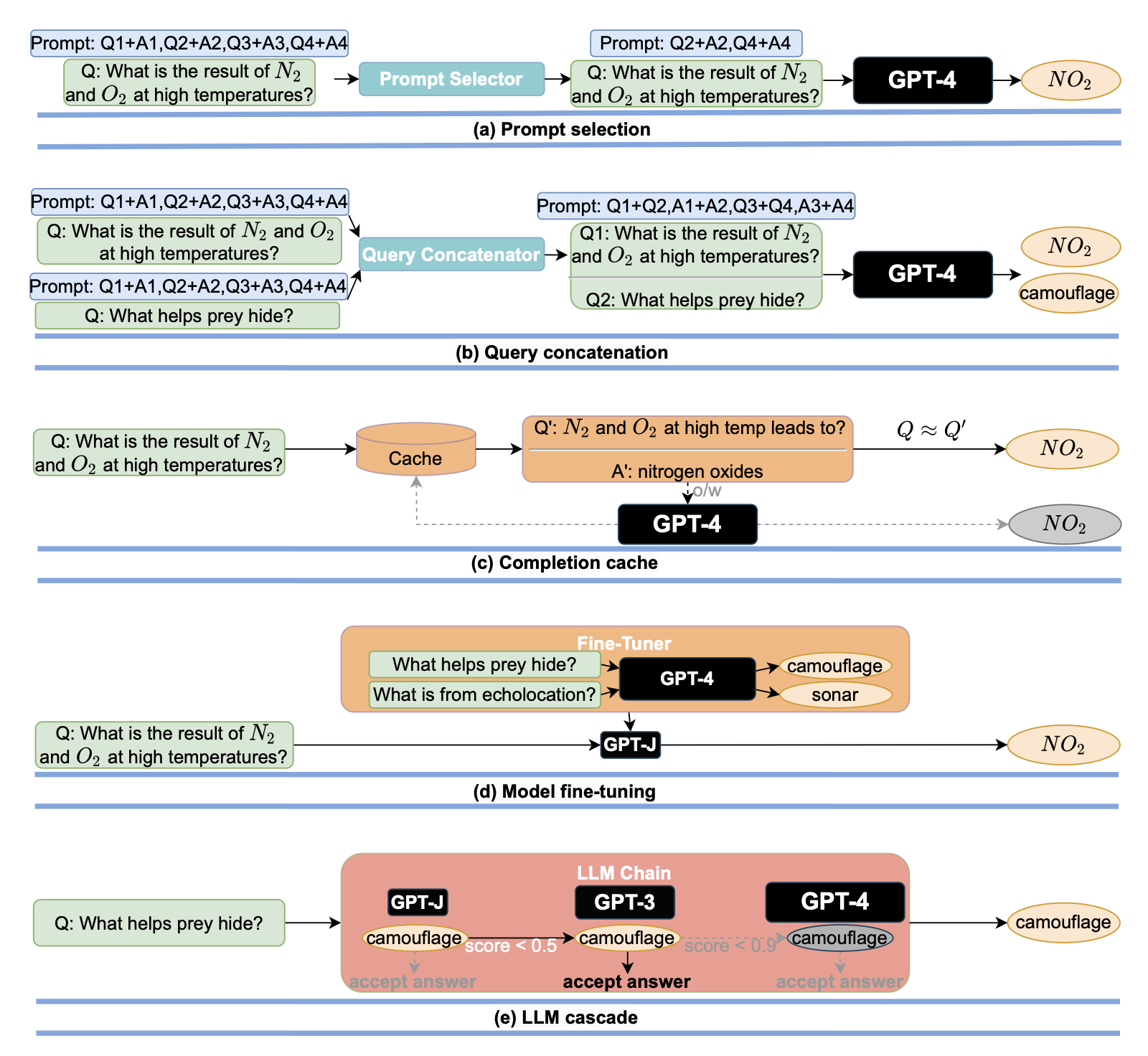
论文摘要:本文讨论了使用大型语言模型(LLMs)的成本和性能问题。作者回顾了查询流行LLM API(如GPT-4、ChatGPT、J1-Jumbo)所需的成本,发现这些模型的定价结构各异,费用相差两个数量级。特别是,在大量查询和文本上使用LLMs可能会很昂贵。出于这个原因,作者提出了三种策略来降低使用LLMs的推理成本:1)提示适应,2)LLM近似,3)LLM级联。作者举例说明了FrugalGPT,这是一种简单而灵活的LLM级联实例,它学习了在不同查询中使用哪些LLMs的组合,以降低成本并提高准确性。实验结果表明,FrugalGPT可以在减少98%的成本或与GPT-4相同成本的情况下,达到最佳单个LLM(例如GPT-4)的性能,或者比GPT-4的准确性提高4%。本文的思路和发现为可持续和高效地使用LLMs奠定了基础。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢