
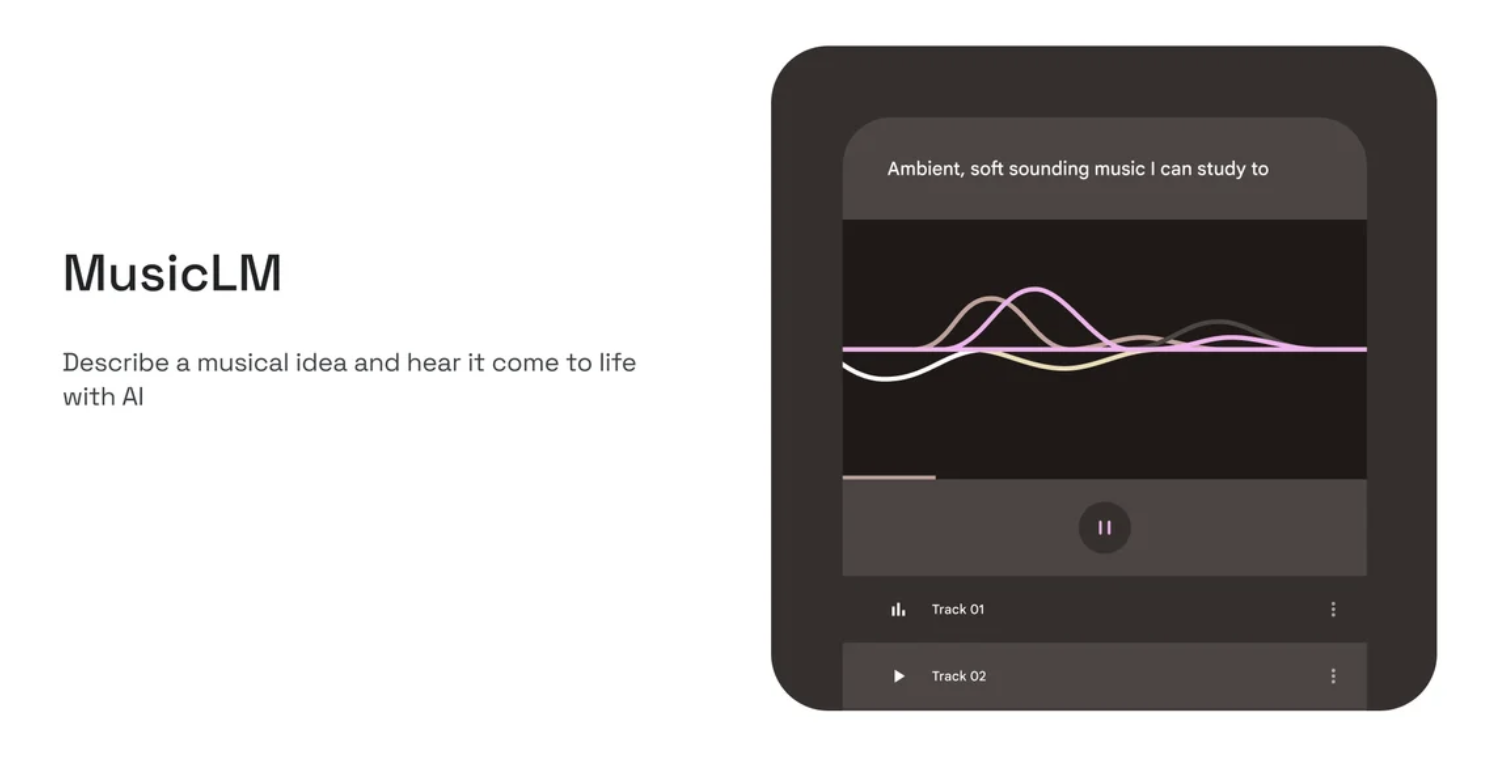
谷歌今天发布了MusicLM,这是一种新的实验性人工智能工具,可以将文本描述转化为音乐,可以注册在网络、Android或iOS上的AI Test Kitchen中试用它。
MusicLM在网络、Android或iOS上的AI Test Kitchen应用程序中可用,允许用户键入“晚餐派对的灵魂爵士乐”或“创建催眠的工业技术声音”等提示,并让该工具创建歌曲的几个版本。
MusicLM: Generating Music From Text
测试地址:https://aitestkitchen.withgoogle.com
视频地址:Music LM Artist workshop with AI Test Kitchen & Google Arts & Culture Lab
项目地址:https://google-research.github.io/seanet/musiclm/examples/
论文地址:https://arxiv.org/abs/2301.11325
作者:
Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, Christian Frank
用户可以指定“电子”或“经典”等乐器,以及他们瞄准的“振动、情绪或情感”,因为他们完善了MusicLM生成的创作。
当谷歌在1月份的一篇学术论文中预览MusicLM时,它表示“没有立即计划”发布它。该论文的合著者指出了像MusicLM这样的系统带来的许多道德挑战,包括将训练数据中受版权保护的材料纳入生成的歌曲的趋势。
只需输入像“晚餐派对的充满灵魂的爵士乐”这样的提示,MusicLM将为您创建歌曲的两个版本。你可以听这两首歌,并给你更喜欢的曲目一个奖杯,这将有助于改进模型。
谷歌MusicLM可生成各种复杂音乐,发布第一个为文本音乐生成任务收集的评估数据集MusicCaps
谷歌发布MusicLM,这不是第一个生成歌曲的 AI 系统,其他更早的尝试包括 Riffusion,这是一种通过可视化来创作音乐的 AI,以及 Dance Diffusion,谷歌自己也发布过 AudioML,OpenAI 则推出过 Jukebox。
虽然生成音乐的 AI 系统早已被开发出来,但由于技术限制和训练数据有限,还没有人能够创作出曲子特别复杂或保真度特别高的歌曲。不过,MusicLM 可能是第一个做到的。
你要做的就是动动手指输入文本就可以。

MusicLM,一个生成模型,能以24kHz的频率生成高质量的音乐,在几分钟内保持一致,同时忠实于文本信号;将该方法扩展到其他条件信号,如根据文本提示合成的旋律,并演示了长达5分钟的长片段音乐生成的一致性;发布第一个专门为文本-音乐生成任务收集的评估数据集MusicCaps,由音乐家准备的5.5千首音乐-文本对的手工整理的高质量数据集。
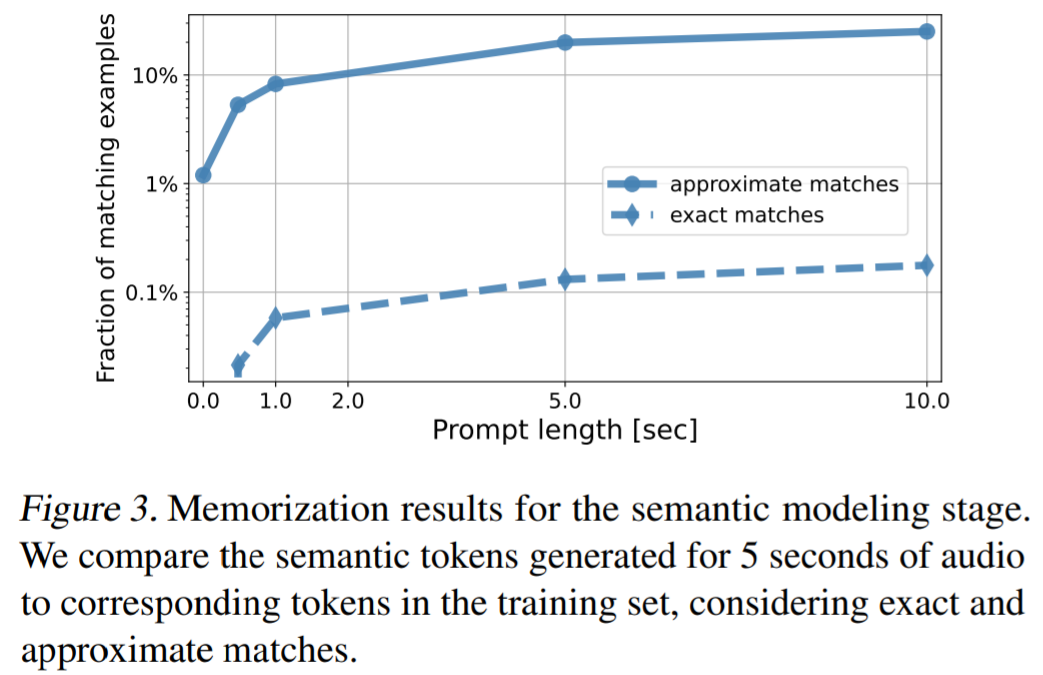
歌采用三个模型来提取音频表示,这些模型将用于条件自回归音乐生成,如图 1 所示。SoundStream 模型用来处理 24 kHz 单声音频,从而得到 50 Hz 的嵌入;具有 600M 参数的 w2v-BERT 模型用于建模中间层;MuLan 模型用于提取目标音频序列的表示。
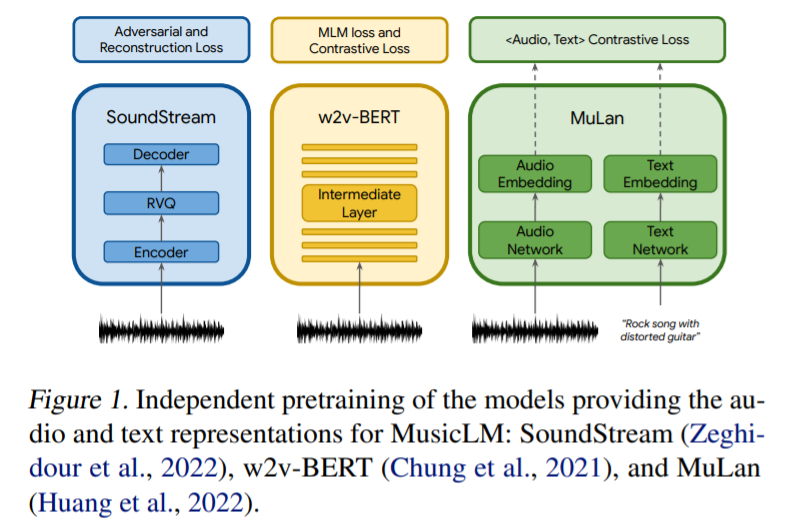
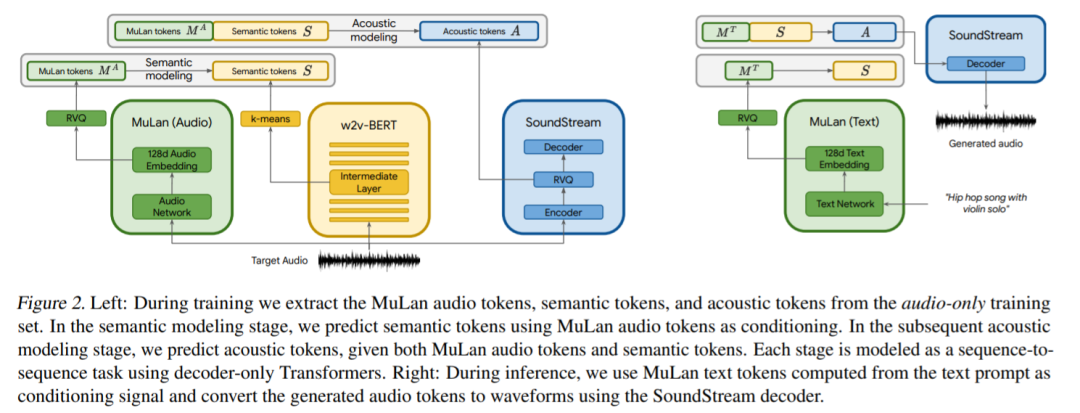
谷歌在 FMA(Free Music Archive)数据集上训练 SoundStream 和 w2v-BERT 模型,而语义和声学建模阶段的 tokenizer 以及自回归模型是在 500 万音频剪辑的数据集上训练的,在 24kHz 下总计 280000 小时的音乐。
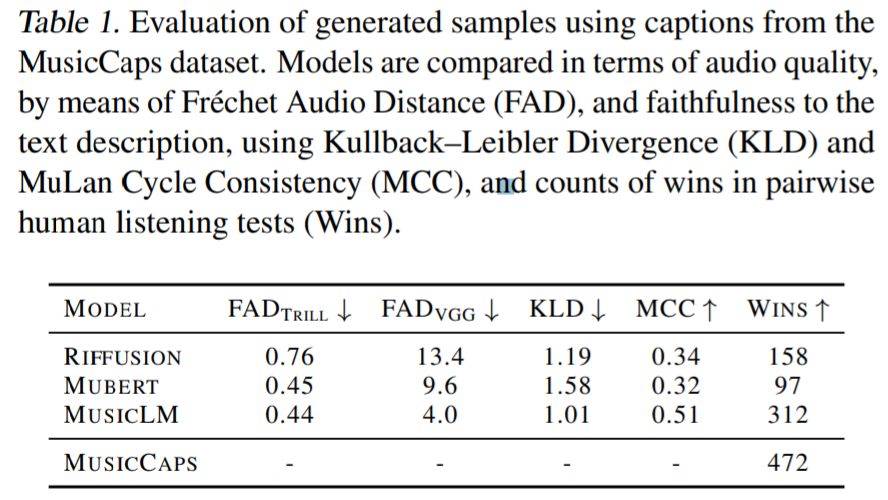
实验部分,谷歌将 MusicLM 与文本生成音乐的基线方法 Mubert 、 Riffusion 进行比较。结果显示在 FAD_VGG 指标上,MusicLM 所捕获的音频质量比 Mubert 和 Riffusion 得分更高。在 FAD_Trill 上,MusicLM 的得分与 Mubert 相似 (0.44 vs。0.45),优于 Riffusion (0.76)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢