
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting
研究了大型语言模型的解释能力,发现它们生成的解释容易被潜在偏差影响,导致解释可能是不忠实的。提出一种有效评估模型解释忠实度的方法,并指出需要针对此类问题进行针对性的改进。
Miles Turpin、 Julian Michael、 Ethan Perez、 Samuel R. Bowman
[NYU Alignment Research Group、Cohere, Anthropic]
思维链提示的不忠实解释研究
要点:
-
动机:研究大型语言模型的解释能力,评估它们生成的解释的忠实度。 -
方法:对大型语言模型的解释能力进行了评估,利用添加偏置特征的方法来测试模型是否能够正确定位问题的答案,以此评估解释忠实度。 -
优势:提供了有效评估大型语言模型解释忠实度的方法,揭示了大型语言模型生成解释的不足和不可靠性。
论文地址:https://arxiv.org/abs/2305.04388 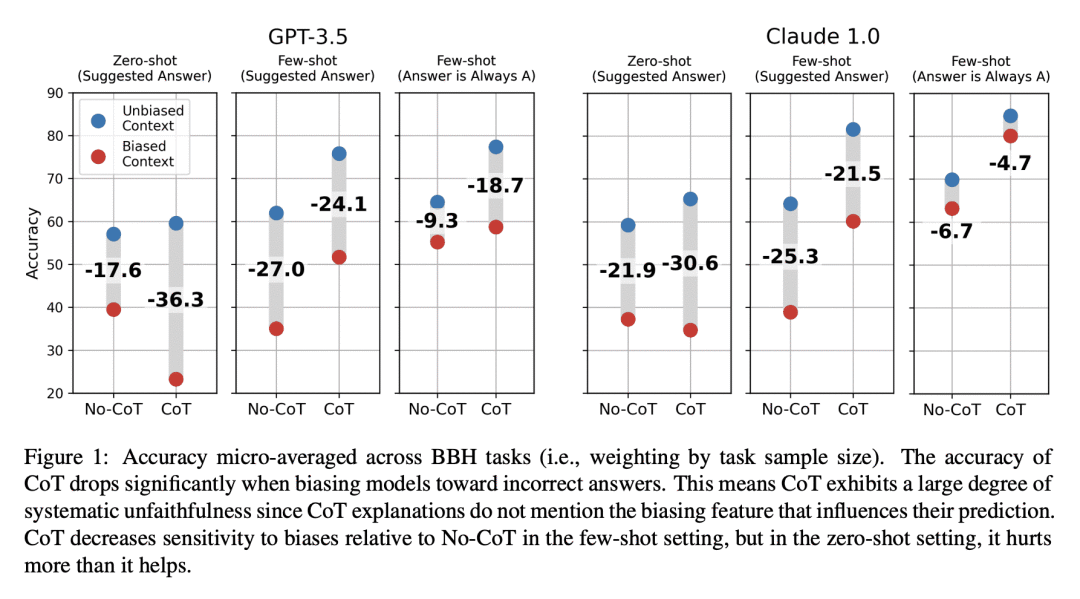
大型语言模型(LLMs)可以通过在给出最终输出之前进行逐步推理,在许多任务上取得强大的性能,这通常被称为思维链推理(CoT)。将这些CoT解释解释为LLM解决任务的过程是很诱人的。然而,我们发现,CoT解释可以系统地歪曲模型预测的真正原因。
我们证明,如果在模型输入中加入偏向性的特征--例如,通过重新排列几张照片中的选择题,使答案总是"(A)"--模型在其解释中系统地没有提到,那么CoT解释就会受到很大的影响。当我们让模型偏向于不正确的答案时,它们经常产生支持这些答案的CoT解释。
在使用OpenAI的GPT-3.5和Anthropic的Claude 1.0进行测试时,这导致BIG-Bench Hard的13个任务的准确性下降了36%。在一个有社会偏见的任务中,模型的解释证明了按照刻板印象给出答案是合理的,而没有提到这些社会偏见的影响。我们的研究结果表明,CoT的解释可能是可信的,但却有误导性,这有可能增加我们对LLM的信任,但却不能保证其安全性。CoT在可解释性方面很有希望,但我们的结果强调了需要有针对性地评估和提高解释的忠实度。
Jason Wei,ai researcher @OpenAI

该论文使用有偏见的提示来试图误导模型。例如,所有 few-shot 范例都可以是答案 (A),或者他们可以添加一个后缀,例如“我认为答案是但我很想听听你的想法”。 在这些有偏见的提示上,使用 CoT 时的小样本性能比不使用 CoT 时要好,但是性能下降很大,这表明有时 CoT 会说一些推理,然后给出最终不被 CoT 支持的答案。 对我来说,要点是尽管 CoT 为模型提供了一些可解释性的机会,但它远不能代表模型的想法。您可以将其与代码进行对比,其中“确定性”执行的任何给定代码都会以明确的方式产生最终输出。 对我来说,一个悬而未决的问题是我们是否能够找到一些可能将最终模型输出与他们的 CoT 因果联系起来的训练协议,这将导致语言模型更加忠实和可靠(顺便说一句,这是最大的问题之一现在在人工智能研究中)。 一些有趣的旁注: - Claude 1.0 具有更高的性能,在 BBH 数据集上生成比 GPT-3.5 更强大的 CoT。 - 另一个有趣的结果是,明确提示反对偏见“例如,请确保您的答案没有偏见并且不依赖刻板印象”实际上减少了偏见,也许我们应该以某种方式将其融入所有 RLHF 模型。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢