
主动检索增强生成
https://arxiv.org/abs/2305.06983
解决问题:该论文试图解决语言模型在生成文本时会产生错误信息的问题,提出了一种从外部知识资源检索信息的方法。同时,该论文还提出了一种新的检索增强模型,能够在生成长文本时持续检索信息,提高生成文本的准确性。
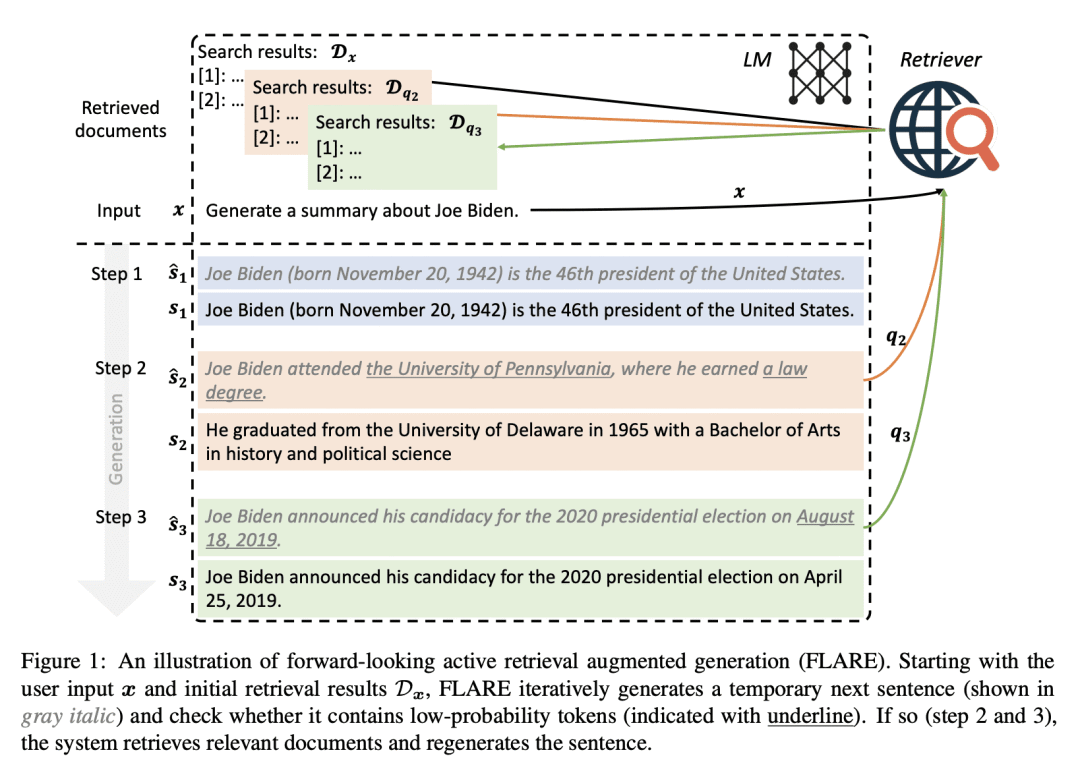
关键思路:该论文提出了一种主动检索增强生成方法,能够根据生成的上下文预测未来内容,进而检索相关文档,提高生成文本的准确性。相比于现有的检索增强模型,该方法具有更好的泛化性和适用性。
其他亮点:该论文的实验设计充分,使用了四个长文本生成任务/数据集进行测试,并提供了数据集和代码。该方法在所有任务上均取得了优异的表现,证明了其有效性。此外,该论文的主要作者来自多个知名机构,具有丰富的研究经验和成果。
关于作者:
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, Graham Neubig
[CMU]
Language Technologies Institute, Carnegie Mellon University
Sea AI Lab 、Meta AI Research
论文摘要:本文提出了一种新的语言模型增强方法——主动检索增强生成(Active Retrieval Augmented Generation)。虽然大型语言模型在理解和生成语言方面具有显著能力,但它们往往会产生虚构和事实不准确的输出。从外部知识资源中检索信息是一种很有前途的解决方案。然而,大多数现有的检索增强语言模型只在输入时检索一次信息,这在生成长文本等更一般的场景中具有局限性,因为在生成过程中不断收集信息是必要的。过去有一些尝试在生成输出时多次检索信息,但大多数都是使用上下文作为查询,以固定间隔检索文档。本文提出了一种主动检索增强生成的通用视角,即在生成过程中主动决定何时以及如何检索信息。我们提出了一种名为FLARE的通用检索增强生成方法,它使用即将生成的句子的预测来预测未来的内容,并将其用作查询来检索相关文档,以重新生成句子。我们在四个长形式知识密集型生成任务/数据集上对FLARE进行了全面测试,并与基线进行了比较。FLARE在所有任务上都取得了优越或有竞争力的表现,证明了我们的方法的有效性。代码和数据集可在https://github.com/jzbjyb/FLARE上获得。
Active Retrieval Augmented Generation
提出一种主动检索增强生成的框架,通过预测即将生成的句子来检索相关信息,以提高生成结果的准确性和可靠性。
-
动机:大型语言模型(LLM)在理解和生成语言方面具有显著能力,但它们倾向于产生虚构和事实不准确的输出。通过从外部知识资源中检索信息来增强LLM是一个有希望的解决方案。 -
方法:提出一种主动检索增强生成的框架,决定在生成过程中何时以及何种信息进行检索。采用前瞻性主动检索,通过预测即将生成的句子,检索相关信息来重新生成包含低置信度Token的句子。 -
优势:在4个长文本知识密集型生成任务/数据集上,FLARE在所有任务上实现了优越或具有竞争力的性能,证明了该方法的有效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢