

Nature上发表了一篇评论文章,作者团队讨论了ChatGPT在科学编程领域的三个潜在能力,包括头脑风暴、分解复杂任务、以及处理简单但耗时的任务。

文章链接:https://www.nature.com/articles/s41559-023-02063-3
研究人员通过使用ChatGPT将自然语言翻译成计算机可读代码,探索了使用生成式AI来增强科学编码的能力和局限性。
实验中的例子主要探索了可能与生态学、进化及其他领域相关的通用任务,研究人员发现,使用ChatGPT可以完成80%-90%的代码编写任务。
如果任务被分解成小的、可管理的代码块,并带有精确的提示作为查询,ChatGPT可以生成非常有用的代码。
值得注意的是,用Google的Bard进行同样的实验通常会得到类似的结果,但代码中的错误更多,所以这篇文章主要使用ChatGPT进行实验。
第一作者Cory Merow是一位定量生态学家,主要研究方向是建立机制模型来预测人口和社区对环境变化的反应。即使是最好的数据集在预测全球变化反应方面也是不完善的,所以需要开发一些工具来结合数据源和探索数据集,以深入了解生物系统可能发生的变化。
ChatGPT助力科学编码
ChatGPT以回归模型GPT-3为基础,在海量的网页、书籍等文本上进行拟合训练,不需要搜索即可生成文本。所以ChatGPT更擅长内插(interpolating,即预测与训练数据相似的文本),而不擅长外推(extrapolating,即预测与训练样本不同的新文本)。
训练集的庞大规模是一个优势,意味着GPT-3已经看到了大量的语言模式,使其能够内插并增加生成对人类有用回复的可能性。不过对代码生成任务来说,GPT-3并不知道如何编程,只是知道代码看起来像什么样,以及哪些词最可能出现在下一个位置,其工作原理类似于自动补全,基于概率模型预测下一个代码块(chunk),块通常比词(word)要小,也可以叫做token
生成正确token的概率基于所有token的概率乘积,即增加预测token的数量或降低选中token的确定性会增加任务的难度,从而降低获得正确token的概率。
因此,想要增加正确token的概率,需要缩短生成任务的长度,或是提供更具体的指令。最后,研究人员提醒,ChatGPT生成的文本有些看起来像代码,但可能无法执行,所以在编码过程中需要仔细观察调试。
头脑风暴工具
ChatGPT可以很好地检索多个数据源,例如在生态领域可以同时获取植物性状、物种分布区域和气象数据。虽然ChatGPT提供的数据有些是不正确的,但通过其提供的链接可以很快地校正这些错误。不过ChatGPT并不能写爬虫从网站上下载数据,可能是因为R语言的包和底层应用程序接口(如R访问数据库的协议)更新过快,毕竟ChatGPT的训练数据是在2021年构建的。
ChatGPT可以在遇到特定问题时提出各种统计技术,在后续的提问中可以生成更多基于用户假设的指导意见,并提供一份初始代码。不过综合(synthesis)过程只适用于提出并交流想法,仍然需要通过传统的数据源(如论文等)进行事实核查。
需要注意的是,一些网站声称ChatGPT有能力对书籍写摘要,不过从研究人员的测试结果来看,这种摘要综合的结果完全不对,可能是因为测试用的书籍没有在GPT-3训练集中出现。
更难的任务需要更多的debug
ChatGPT非常擅长生成模板代码,在特定指令下提供一份包含少量函数的短脚本代码。比如下面的例子中,研究人员要求ChatGPT将四个常用函数的输入和输出串一起。并提供一个将此函数用于模拟数据的示例代码。
可以看到ChatGPT生成的结果几乎是完美的,调试代码只花了几分钟,不过需要在提示中非常具体地说明query,包括提供命名和用到的函数。
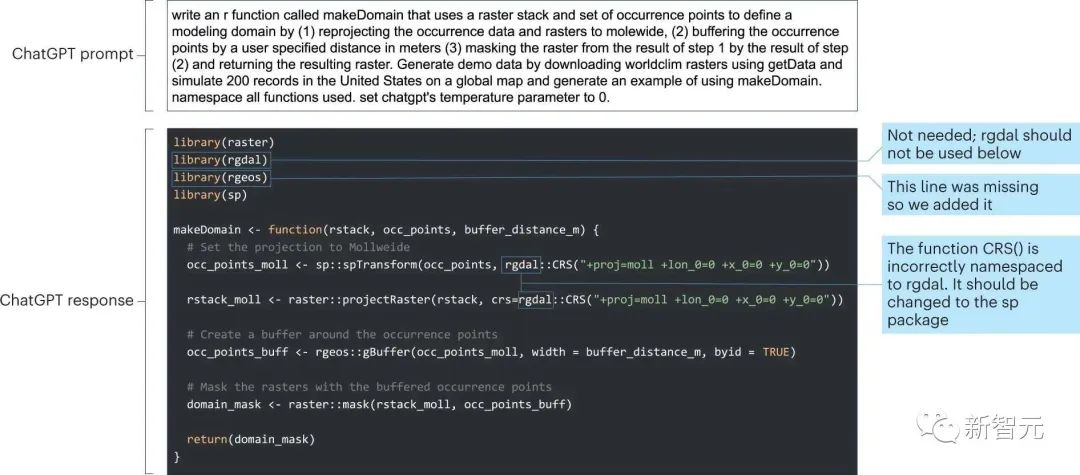
研究人员发现,成功的关键在于:
1、将复杂任务分解成多个子任务,每个子任务最好只需要少数几个步骤即可完成,毕竟ChatGPT生成的代码是基于概率文本预测模型的结果。
2、ChatGPT在使用已经存在的函数时表现最佳,因为这时只涉及内插而非外推。
例如,使用正则表达式(regex)从文本中提取信息的代码对于许多开发人员来说是非常困难的,不过因为已经有正则网站提供了大量在线示例,并可能出现在ChatGPT示例中,所以ChatGPT写正则的性能还是不错的。
3、学术界对ChatGPT最大的批评之一是其信息来源缺乏透明度。
对于代码生成任务,通过指定「命名空间」(namespace),即在使用函数时显式调用包名可以实现一定程度的透明性。不过ChatGPT可能会直接复制个人的公开代码而没有引用出来,并且研究人员仍然有责任验证正确的代码归属人。同时,如果要求生成更长的脚本会暴露出一些ChatGPT的缺陷,例如伪造函数名或参数等,这也是StackOverflow禁用ChatGPT生成代码的原因。
但如果用户提供了一组明确的执行步骤,ChatGPT仍然可以生成一个有用的工作流模板,定义步骤之间的输入和输出之间的连接,这可能是用GPT-3外推生成新代码的最有用的途径。
目前ChatGPT还不能将伪代码(用简单语言描述的算法步骤) 转换为完美的计算机可执行代码,但这可能离现实并不遥远。ChatGPT对于初学者、不熟悉的编程语言来说特别有帮助,因为初学者只会写一些较短的脚本,调试更方便。
ChatGPT更擅长非创造性任务
ChatGPT最擅长解决的是耗时的公式化任务,可用于调试、检测和解释代码中的错误。ChatGPT在编写函数文档时也非常有效,例如使用roxygen 2的内联文档语法,在标识出所有参数及类上非常高效,不过却很少解释如何使用函数。
一个关键的限制是ChatGPT的生成被限制在大约500个单词,只能专注于较小代码块的生成,同时还可以生成单元测试以自动化确认代码功能。
ChatGPT给出的大多数建议在定义测试的结构和检查预期的对象类方面是很有帮助的。
最后,ChatGPT在对代码进行重新格式化以遵循标准化(例如Google)代码样式方面非常有效。
未来属于伪代码
ChatGPT和其他人工智能驱动的自然语言处理工具已经准备好将开发人员的简单任务进行自动化,例如编写短函数,语法调试,注释和格式化,而扩展复杂性取决于用户的调试意愿(以及他们的熟练程度)。
研究人员总结了ChatGPT在代码生成上的功能,可以简化科学领域的代码编写过程,不过人工检查仍然是必要的,可运行的代码并不一定意味着代码能够执行预期的任务,因此单元测试或非正式的交互式测试仍然至关重要。

在解决方案可能由人类开发,并由ChhatGPT简单复制生成的情况下,确保正确的代码归属人至关重要。目前已经有聊天机器人开始自动提供指向其来源的链接(例如,微软的必应),尽管这一步还处于起步阶段。
与传统方法相比,ChatGPT提供了一种学习编码技能的替代方法,通过将伪代码直接转换为代码,可以缓解编写初始任务的障碍。
研究人员怀疑未来的进展将使用ChatGPT这样的工具来自动调试编写的代码,根据遇到的错误迭代地生成、运行和提出新代码,在实验过程中,研究人员发现纠正代码的能力有限,只有在非常具体的指令针对小代码块时才会偶尔成功,调试过程的效率远低于人工调试。
研究人员猜想,随着技术的进步(比如最近发布的GPT-4模型 ,据称比GPT-3模型大10倍),自动化调试将会得到改进。
未来即将到来,现在是开发人员学习提示工程技能以利用新兴AI工具的时候了,研究人员预计,使用人工智能生成的代码将成为软件开发各个方面越来越有价值的技能,这些技能是科学发现和理解的基础。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢