
Towards Building the Federated GPT: Federated Instruction Tuning
提出一种名为联邦指令微调(FedIT)的方法,使用联邦学习框架对大型语言模型(LLM)进行指令微调。该方法利用终端用户设备上的异构和多样化的指令,以提高LLM的性能和普适性,提供了一个名为Shepherd的Github库,可用于探索联邦细调LLM的方法。
J Zhang, S Vahidian, M Kuo, C Li, R Zhang, G Wang, Y Chen
[Duke University & Microsoft Research]
联邦GPT探索:联邦指令微调
要点:
-
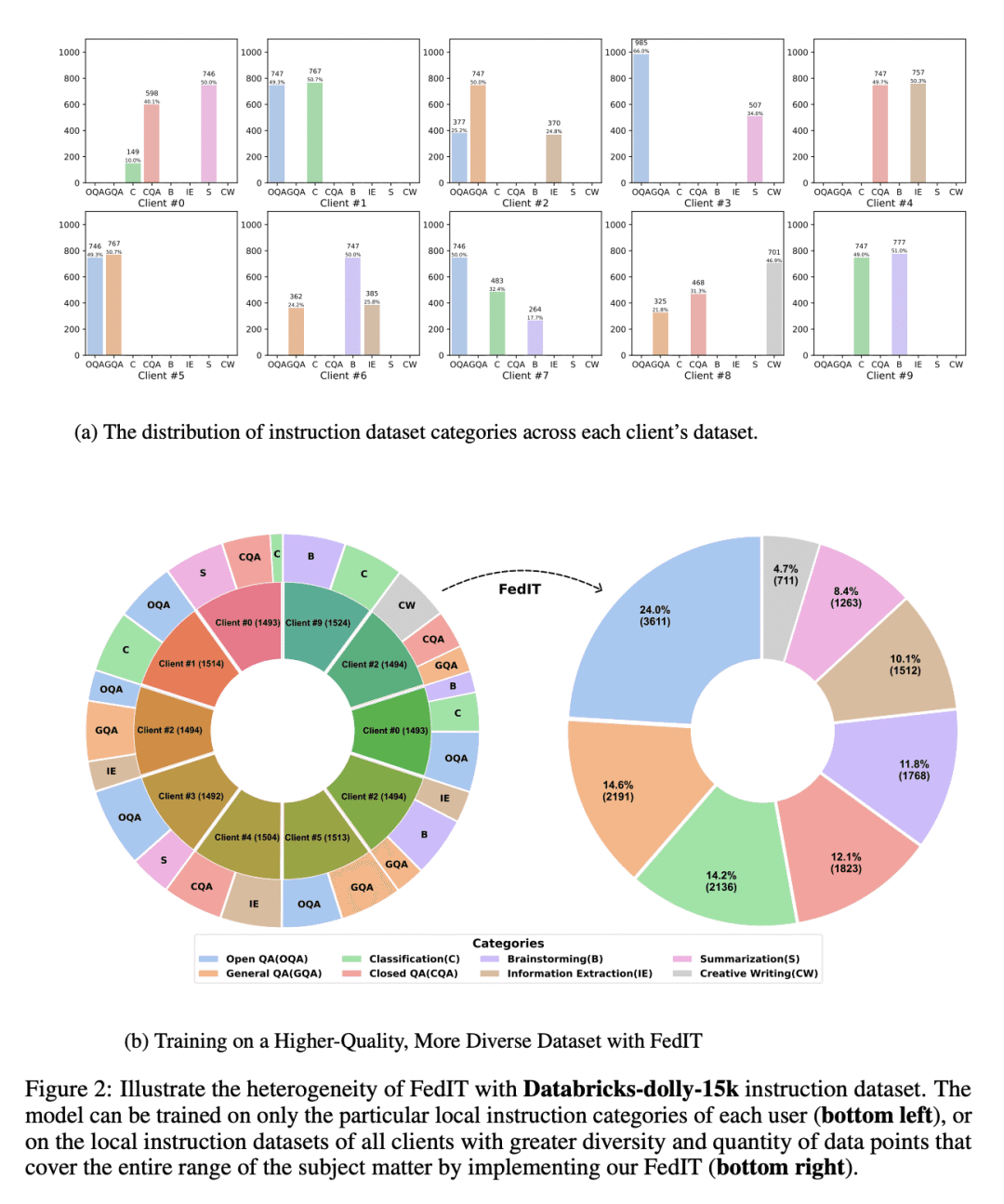
动机:获取高质量的指令数据可以帮助LLM训练,但获取这些数据的成本和隐私问题可能会导致LLM在某些情况下效果不佳。 -
方法:使用联邦学习框架,利用终端用户设备上的异构和多样化的指令,对LLM进行指令微调。此外,开发了一种名为Shepherd的开发库,用于探索联邦微调LLM的方法。 -
优势:使用FedIT方法可以充分利用用户设备上的指令数据,提高LLM的性能和普适性,从而改善LLM在特定环境下的效果。
https://arxiv.org/abs/2305.05644


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢