

从聊天到编程再到支持各种插件,强大的 ChatGPT 早就不是一个简单的对话助手,而是朝着 AI 界的「管理层」不断前进。
3 月 23 号,OpenAI 宣布 ChatGPT 开始支持各类第三方插件,比如著名的理工科神器 Wolfram Alpha。借助该神器,原本鸡兔同笼都算不准的 ChatGPT 一跃成为理工科尖子生。Twitter 上许多人评论说,ChatGPT 插件的推出看起来有点像 2008 年 iPhone App Store 的推出。这也意味着 AI 聊天机器人正在进入一个新的进化阶段 ——「meta app」阶段。
紧接着,4 月初,浙江大学和微软亚研的研究者提出了一种名为「HuggingGPT」的重要方法,可以看做是上述路线的一次大规模演示。HuggingGPT 让 ChatGPT 充当控制器(可以理解为管理层),由它来管理其他的大量 AI 模型,从而解决一些复杂的 AI 任务。具体来说,HuggingGPT 在收到用户请求时使用 ChatGPT 进行任务规划,根据 HuggingFace 中可用的功能描述选择模型,用选定的 AI 模型执行每个子任务,并根据执行结果汇总响应。
这种做法可以弥补当前大模型的很多不足,比如可处理的模态有限,在某些方面比不上专业模型等。
虽然调度的是 HuggingFace 的模型,但 HuggingGPT 毕竟不是 HuggingFace 官方出品。刚刚,HuggingFace 终于出手了。

和 HuggingGPT 理念类似,他们推出了一个新的 API——HuggingFace Transformers Agents。通过 Transformers Agents,你可以控制 10 万多个 Hugging Face 模型完成各种多模态任务。
比如在下面这个例子中,你想让 Transformers Agents 大声解释图片上描绘了什么内容。它会尝试理解你的指令(Read out loud thecontent of the image),然后将其转化为 prompt,并挑选合适的模型、工具来完成你指定的任务。
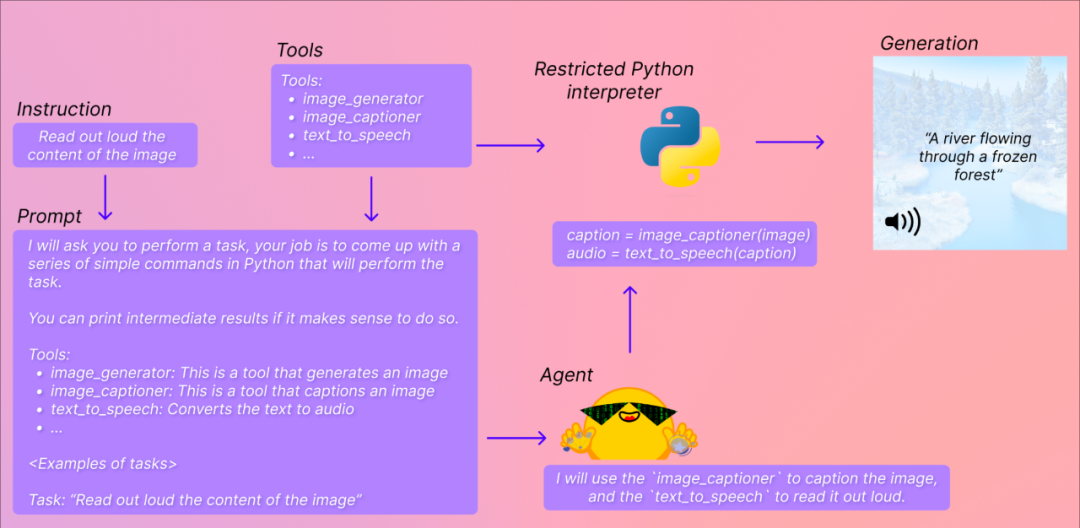
英伟达 AI 科学家 Jim Fan 评价说:这一天终于来了,这是迈向「Everything APP」(万事通 APP)的重要一步。

不过也有人说,这和 AutoGPT 的自动迭代还不一样,它更像是省掉了写 prompt 并手动指定工具这些步骤,距离万事通 APP 还为时过早。
Transformers Agents 地址:https://huggingface.co/docs/transformers/transformers_agents
Transformers Agents 怎么用?
在发布的同时,HuggingFace 就放出了 Colab 地址,任何人都可以上手一试:
https://huggingface.co/docs/transformers/en/transformers_agents
简而言之,它在 transformers 之上提供了一个自然语言 API:首先定义一套策划的工具,并设计了一个智能体来解释自然语言和使用这些工具。而且,Transformers Agents 在设计上是可扩展的。
团队已经确定了一组可以授权给智能体的工具,以下是已集成的工具列表:
-
文档问答:给定一个图像格式的文档(例如 PDF),回答关于该文档的问题 (Donut)
-
文本问答:给定一段长文本和一个问题,回答文本中的问题(Flan-T5)
-
无条件的图像说明:为图像添加说明 (BLIP)
-
图片问答:给定一张图片,回答关于这张图片的问题(VILT)
-
图像分割:给定图像和 prompt,输出该 prompt 的分割掩码(CLIPSeg)
-
语音转文本:给定一个人说话的录音,将语音转录成文本 (Whisper)
-
文本到语音:将文本转换为语音(SpeechT5)
-
零样本文本分类:给定文本和标签列表,确定文本与哪个标签最对应 ( BART )
-
文本摘要:用一个或几个句子来概括一个长文本(BART)
-
翻译:将文本翻译成给定的语言(NLLB)
这些工具集成在 transformers 中,也可以手动使用:
from transformers import load_tool
tool = load_tool("text-to-speech")
audio = tool("This is a text to speech tool")
用户还可以将工具的代码推送到 Hugging Face Space 或模型存储库,以便直接通过智能体来利用该工具,比如:
-
文本下载器:从 web URL 下载文本
-
Text to image : 根据 prompt 生成图像,利用 Stable Diffusion
-
图像转换:在给定初始图像和 prompt 的情况下修改图像,利用 instruct pix2pix stable diffusion
-
Text to video : 根据 prompt 生成小视频,利用 damo-vilab
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢