
首先,在本次测评中,我们选取了 11 个模型进行测试:GPT-3.5、GPT-4、智谱 AI ChatGLM 初版及最新的 130B-v0.8 版、文心一言初版及 4 月 27 日更新版、商汤 SenseChat、阿里巴巴通义千问、科大讯飞星火、面壁模方以及复旦大学 MOSS(开源);
其次,与上次一样,我们依旧选择了从基础能力、涌现能力与垂直能力三个角度对模型进行了测评,题目共计 311 道:我们对其中的一些问题进行了优化,也基于大家看到的,在过去的两个月中模型明显的能力特点或进步,增加了一些可以体现模型新能力的题目,量不多,供大家参考;
最后,要声明的是,除部分游戏类(如二十问、是否黑白)题目外,所有题目均为单轮对话,鉴于语言模型的回答具有随机性的特点,我们均选取第一次答案作为正误或合理与否的判断标准。
首先,给大家展示一个可以直观展示各个模型能力横向对比的条形图:
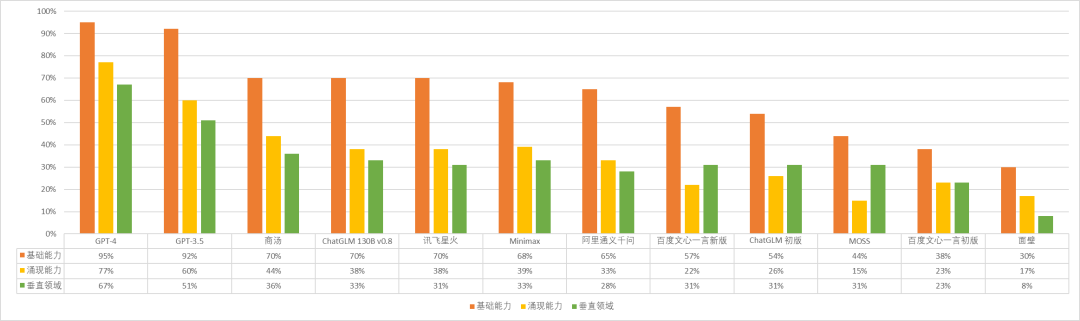
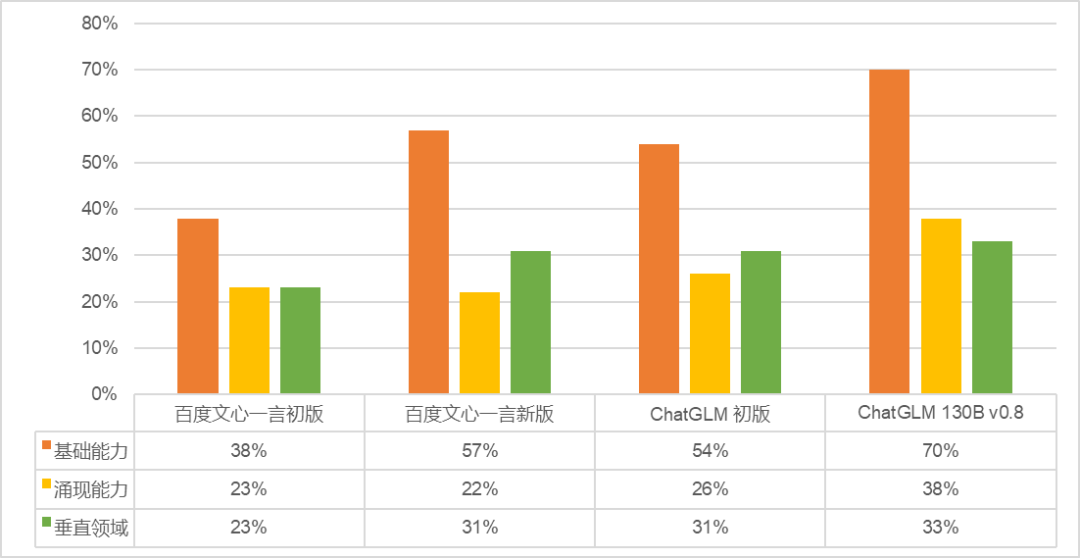
第二,从新发布模型的能力进行分析。我们以表现最突出的四个模型,商汤 SenseChat、讯飞星火、Minimax 应事 AI 与阿里通义千问为例:
- 先说优点,几个模型的事实问答能力都已经到了不错的水平。在 19 个问题的测评中,阿里通义千与讯飞星火都得到了 12 分,商汤 SenseChat 11 分,Minimax 10 分。
- 但其他能力方面,几个模型都存在「偏科」现象:
✔ 商汤 SenseChat 全部回答错误的类别更少,能力更为全面,尤其值得一提的是,SenseChat 在对话与文本处理的多个细分类别中得到了满分;
✔ 阿里通义千问的常识与基础编程能力相较其他模型更好,但涉及数据、编码、符号相关的处理能力较差,对语言逻辑的判断能力还需进一步提升;
✔ 讯飞星火的基础数学能力(17/44)在其中是最为优秀的,但几何能力却是这四个模型中最差的,无论空间几何还是坐标几何,均全部回答错误;
✔ Minimax 的对话与文本处理能力已经很不错了,在分类、语法修正、情绪感知这三类中得到了满分,在语义识别与语言逻辑判断中的得分也较为优秀,但其文本处理能力也不是全面的,其中要点总结能力显然还需要提高。
- 最后说说缺点,国产中文模型的编程可用性还相对较低,数据与符号处理能力还有所欠缺,多语言处理能力较差,老生常谈的逻辑推理与数学能力也还有很大提升空间。
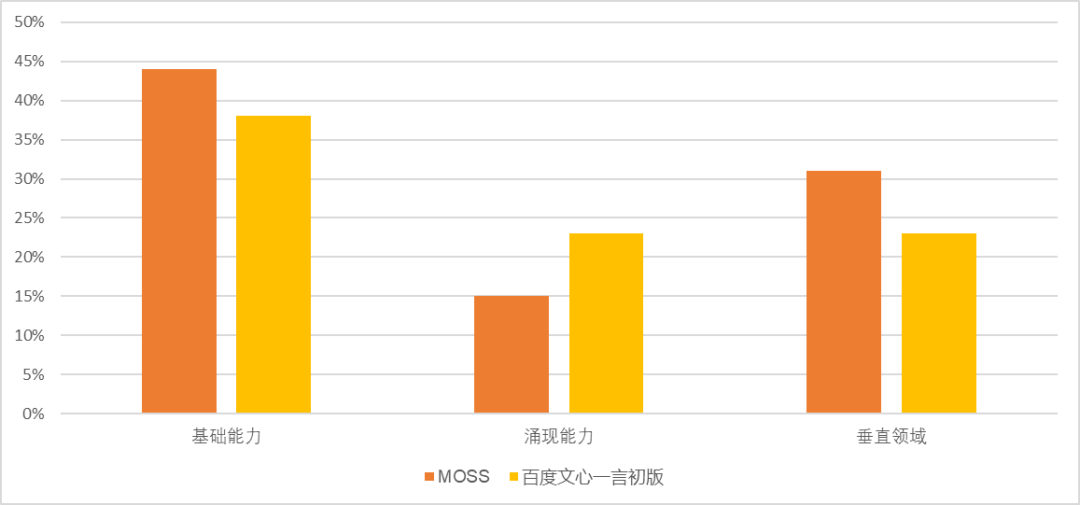
在本次测评中,还有一个特殊的模型 MOSS —— 由复旦大学开发并完全开源的大语言模型。在这次的测评中 MOSS 的表现虽然并不突出,但在我们的测评中,综合能力已经超过了 3 月发布的百度文心一言(基础能力 44%:38%,涌现能力 15%:23%;垂直能力 31%:23%)。
另外,值得一提的是,ChatGLM 不仅在我们的测评中排名靠前,在前不久 UC Berkeley 团队领衔的 LMSYS 组织的 Chatbot Arena 测评中,开源的 ChatGLM-6B 英文表现也很优秀(测评结果链接我们也附在了文末)。海外开源模型蔚然成风的当下,我们希望听到更多来自中文开源社区的好消息!
LMSYS Chatbot Arena - https://lmsys.org/blog/2023-05-03-arena/
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢