
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
X Liu, H Peng, N Zheng, Y Yang, H Hu, Y Yuan
[Microsoft Research & The Chinese University of Hong Kong]
EfficientViT:基于级联组注意力的记忆高效视觉Transformer
要点:
-
动机:提出一种高速的视觉Transformer模型——EfficientViT,以解决现有Transformer模型在实时应用中的计算成本问题。 -
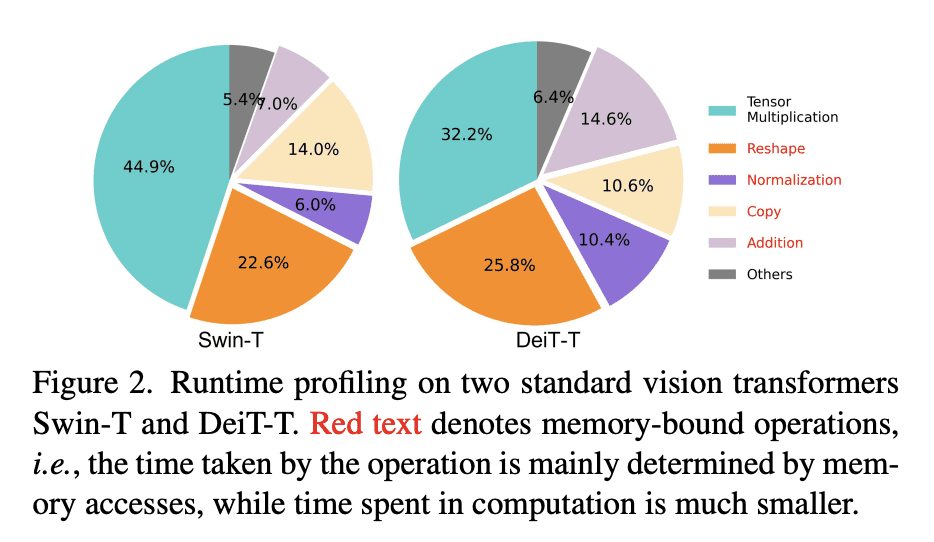
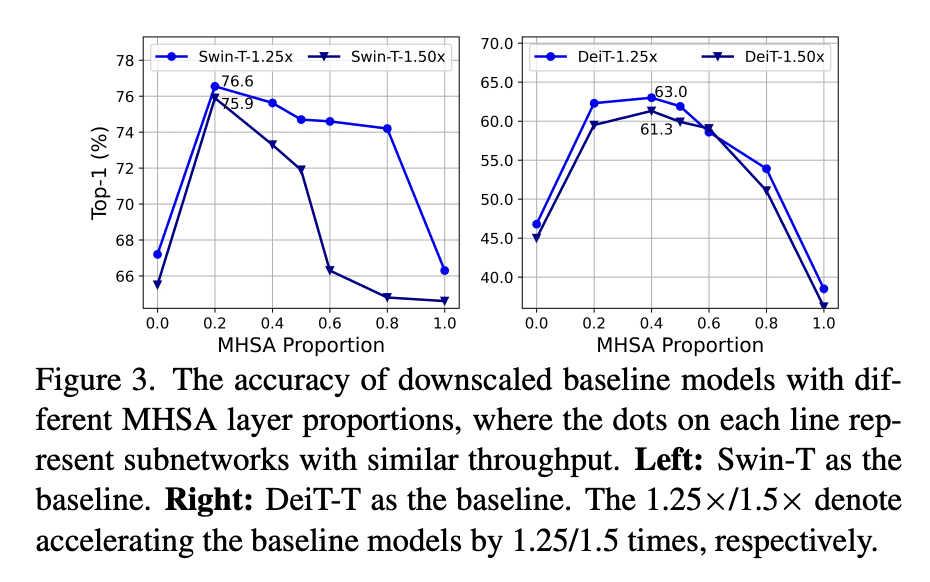
方法:设计了一种新的构建块,采用单独的memory-bound MHSA和高效的FFN层之间的夹层布局,以提高内存效率和通道通信,并提出了一种级联组注意力模块,用于不同分裂的全特征输入注意力头,以节省计算成本并改善注意力多样性。 优势:EfficientViT在速度和准确性之间取得了良好的平衡,比现有的高效模型表现更好,同时在各种下游基准测试中表现出优越性,如在Nvidia V100 GPU和Intel Xeon CPU上获得了更高的吞吐量,同时超过MobileNetV3-Large 1.9%的准确度。
提出一种名为EfficientViT的高速视觉Transformer模型,采用了新的构建块和级联组注意力模块,以实现内存效率和通道通信的提高,同时在速度和准确性之间取得了良好的平衡。
https://arxiv.org/abs/2305.07027 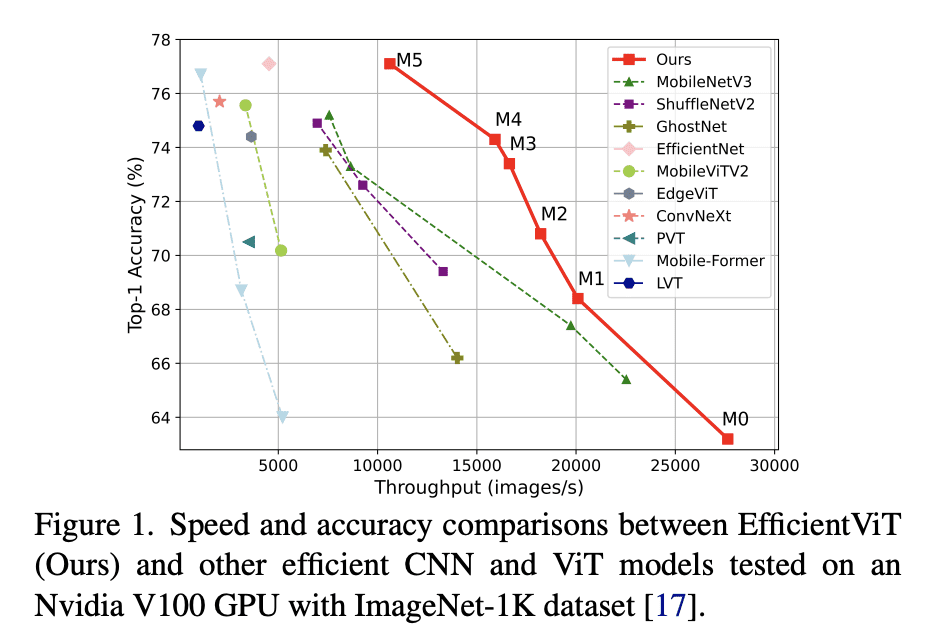
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢