
MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
LiliYu、DanielSimig、ColinFlaherty、ArmenAghajanyan、LukeZettlemoyer、 MikeLewis
Meta AI,Augment Computing,Work performed while at Meta AI.
解决问题: 该论文试图解决的问题是对于长序列,如高分辨率图像、音频、代码或书籍等,自回归变压器模型的规模扩展问题。同时,论文还尝试验证了一种新的多尺度解码器架构对于长序列建模的有效性。
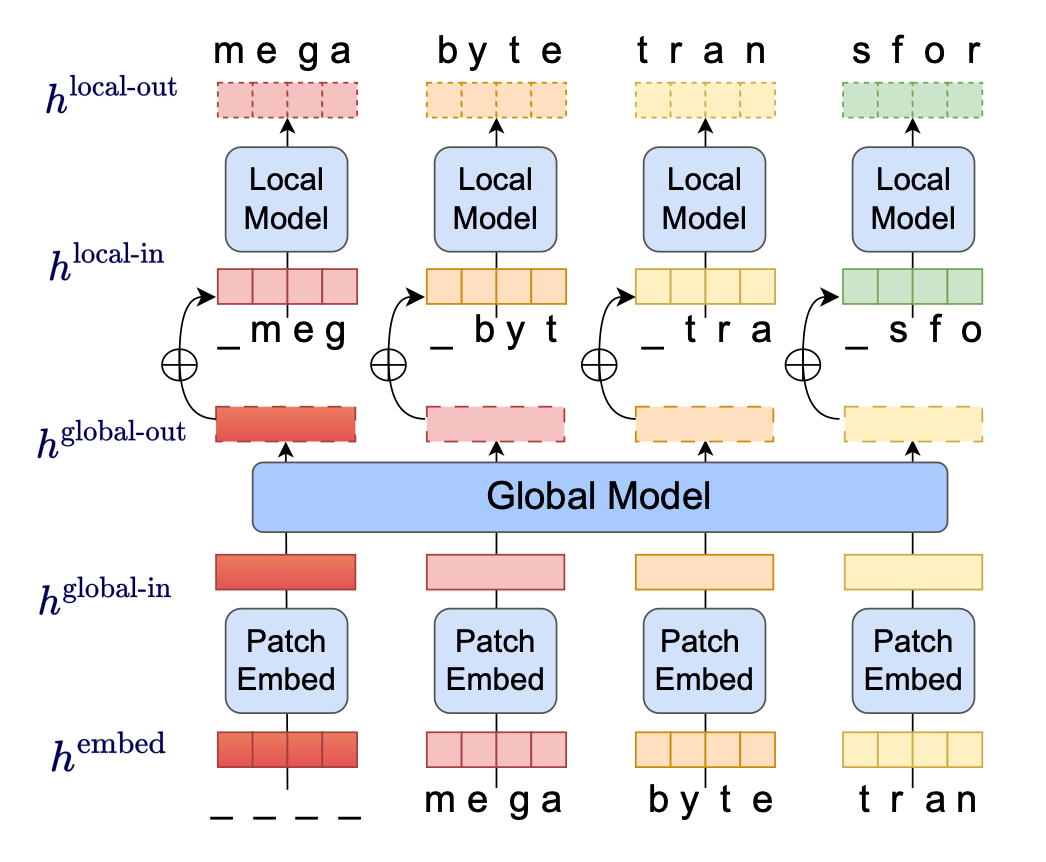
关键思路: 论文中提出的关键思路是使用多尺度解码器架构,将长序列分为多个小块,每个小块内部使用本地子模型进行建模,而不是直接使用全局模型。这种方法可以实现子二次自注意力机制,使得同样的计算资源可以使用更大的前馈层,并且在解码过程中可以实现更好的并行化,从而提高训练和生成的效率。
其他亮点: 论文使用了多个数据集进行实验,包括ImageNet、音频数据集等,实验结果表明,该方法可以在长序列建模方面与子词模型相媲美,并且在ImageNet数据集上实现了最先进的密度估计。此外,该论文还提供了开源代码,方便其他研究者进行复现和进一步研究。
关于作者: 本文主要作者为Lili Yu、Dániel Simig、Colin Flaherty、Armen Aghajanyan、Luke Zettlemoyer和Mike Lewis。其中,Lili Yu曾在谷歌工作,主要研究方向为自然语言处理和计算机视觉,曾发表过多篇相关论文;Mike Lewis是Facebook AI Research的研究员,曾在OpenAI工作,主要研究方向为自然语言处理和强化学习,也曾发表过多篇相关论文。
相关研究: 近期其他相关的研究包括:
- "Scaling Autoregressive Video Models" by Carl Vondrick, Hamed Pirsiavash, and Antonio Torralba, MIT。
- "Long Range Arena: A Benchmark for Efficient Transformers" by Yacine Jernite, Edouard Grave, and Armand Joulin, Facebook AI Research。
- "Reformer: The Efficient Transformer" by Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya, Google Brain。
论文摘要:
Megabyte是一种多尺度解码器架构,可以对超过一百万字节的序列进行端到端可微建模。它将序列分成多个补丁,并在补丁内使用本地子模型和补丁间的全局模型。这使得子二次自注意力、更大的前馈层以及解码期间的改进并行性成为可能,从而在训练和生成时降低成本的同时提高性能。
大量实验证明,Megabyte使得字节级模型在长上下文语言建模方面可以与子词模型竞争,并在ImageNet上实现了最先进的密度估计,并且可以对原始音频文件进行建模。这些结果共同证明了在大规模情况下无需进行标记化的自回归序列建模的可行性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢