
ArtGPT-4: Artistic Vision-Language Understanding with Adapter-enhanced MiniGPT-4
解决问题:本文的目标是提出一种新的多模态模型ArtGPT-4,以解决MiniGPT-4在艺术图片理解方面的不足。同时,文章还提出了新的评估视觉语言模型性能的基准。
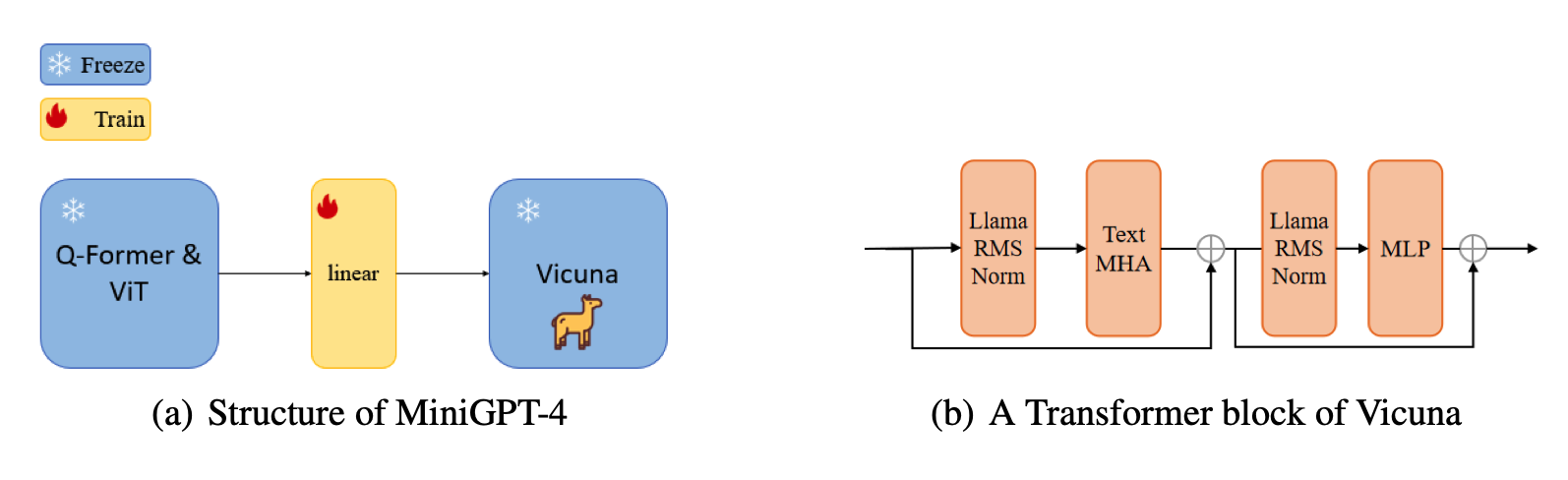
关键思路:文章采用了一种名为Adapter-enhanced MiniGPT-4的方法,通过对MiniGPT-4的改进,使其在视觉语言理解方面表现更好。同时,作者还使用了一些创新的训练策略,如对抗训练和数据增强。此外,作者还提出了一种新的多模态模型ArtGPT-4,它可以用于生成艺术化的图像和代码。
其他亮点:本文还提出了新的基准来评估视觉语言模型的性能,并展示了ArtGPT-4在这些基准上的表现。此外,作者还公开了代码和预训练模型。
关于作者:本文的主要作者来自清华大学。他们在计算机视觉、自然语言处理和机器学习等领域都有很多代表作。例如,其中一位作者Yongming Liu曾经参与开发过深度学习框架MXNet。
论文摘要:最近几年,大型语言模型(LLMs)在自然语言处理(NLP)方面取得了重要进展,像ChatGPT和GPT-4这样的模型在各种语言任务中取得了令人印象深刻的能力。然而,对这样大规模的模型进行训练是具有挑战性的,找到与模型规模相匹配的数据集通常也很困难。微调和使用新方法训练具有更少参数的模型已成为克服这些挑战的有希望的方法之一。其中一种模型是MiniGPT-4,它通过利用新颖的预训练模型和创新的训练策略实现了与GPT-4相当的视觉语言理解能力。
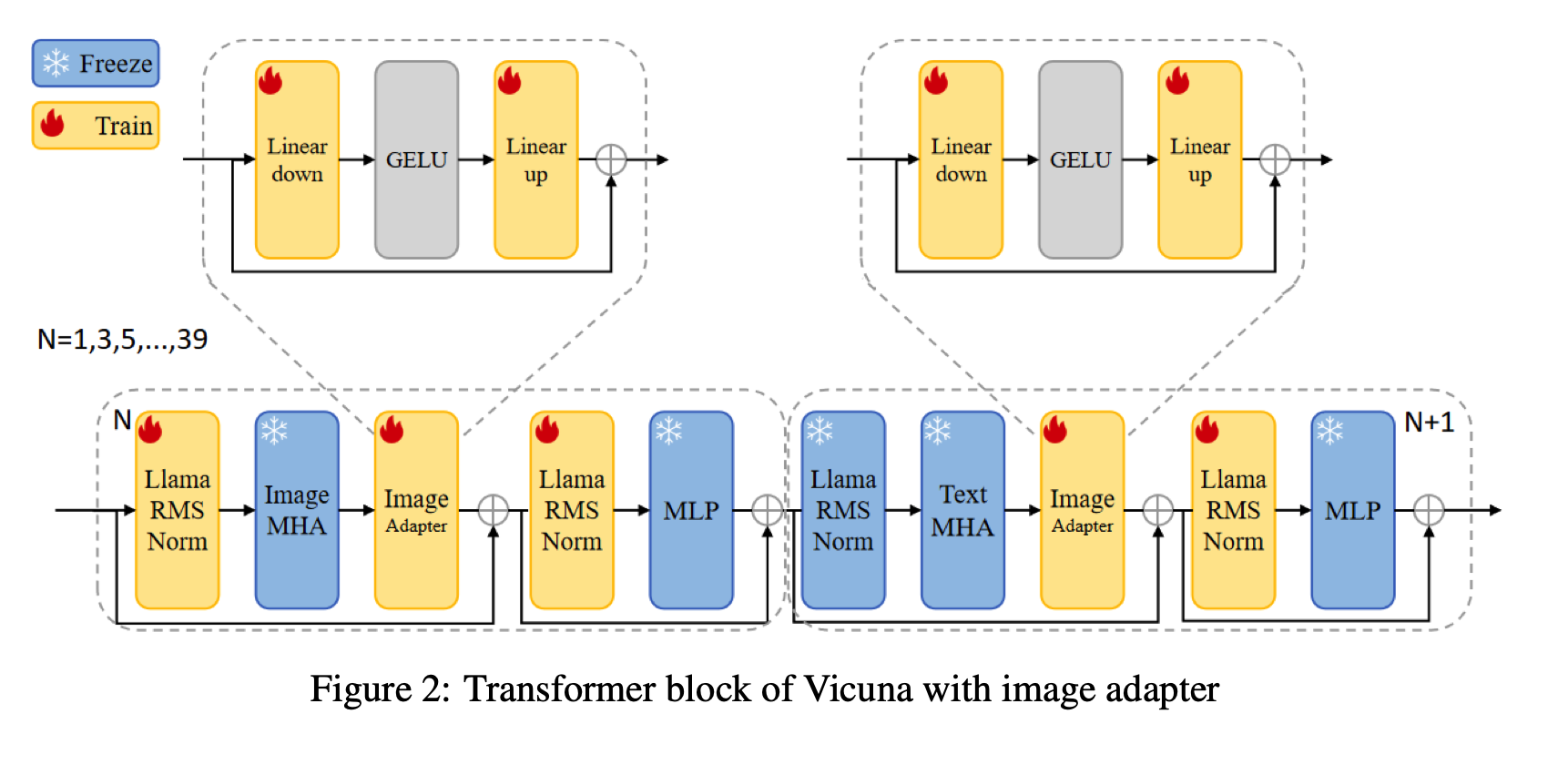
然而,该模型在图像理解方面仍然面临一些挑战,特别是在艺术图片方面。为了解决这些限制,提出了一种新的多模态模型ArtGPT-4。ArtGPT-4使用Tesla A100设备在仅2小时内,使用约200 GB的数据对图像文本对进行了训练。该模型可以以艺术风格描绘图像并生成视觉代码,包括美观的HTML/CSS网页。此外,文章提出了评估视觉语言模型性能的新基准。在随后的评估方法中,ArtGPT-4得分比当前的最先进模型高了1分以上,在6分制上仅比艺术家低0.25分。
我们的代码和预训练模型可在\url{https://huggingface.co/Tyrannosaurus/ArtGPT-4 }上找到。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢