
前段时间,来自LMSYS Org(UC伯克利主导)的研究人员又搞了个大新闻——大语言模型版排位赛,「LLM排位赛」就是让一群大语言模型随机进行battle,并根据它们的Elo得分进行排名。
https://hub.baai.ac.cn/view/26567
这次,团队不仅带来了4位新玩家,而且还有一个(准)中文排行榜。
-
OpenAI GPT-4
-
OpenAI GPT-3.5-turbo
-
Anthropic Claude-v1
-
RWKV-4-Raven-14B(开源)
毫无疑问,只要GPT-4参战,必定是稳居第一。
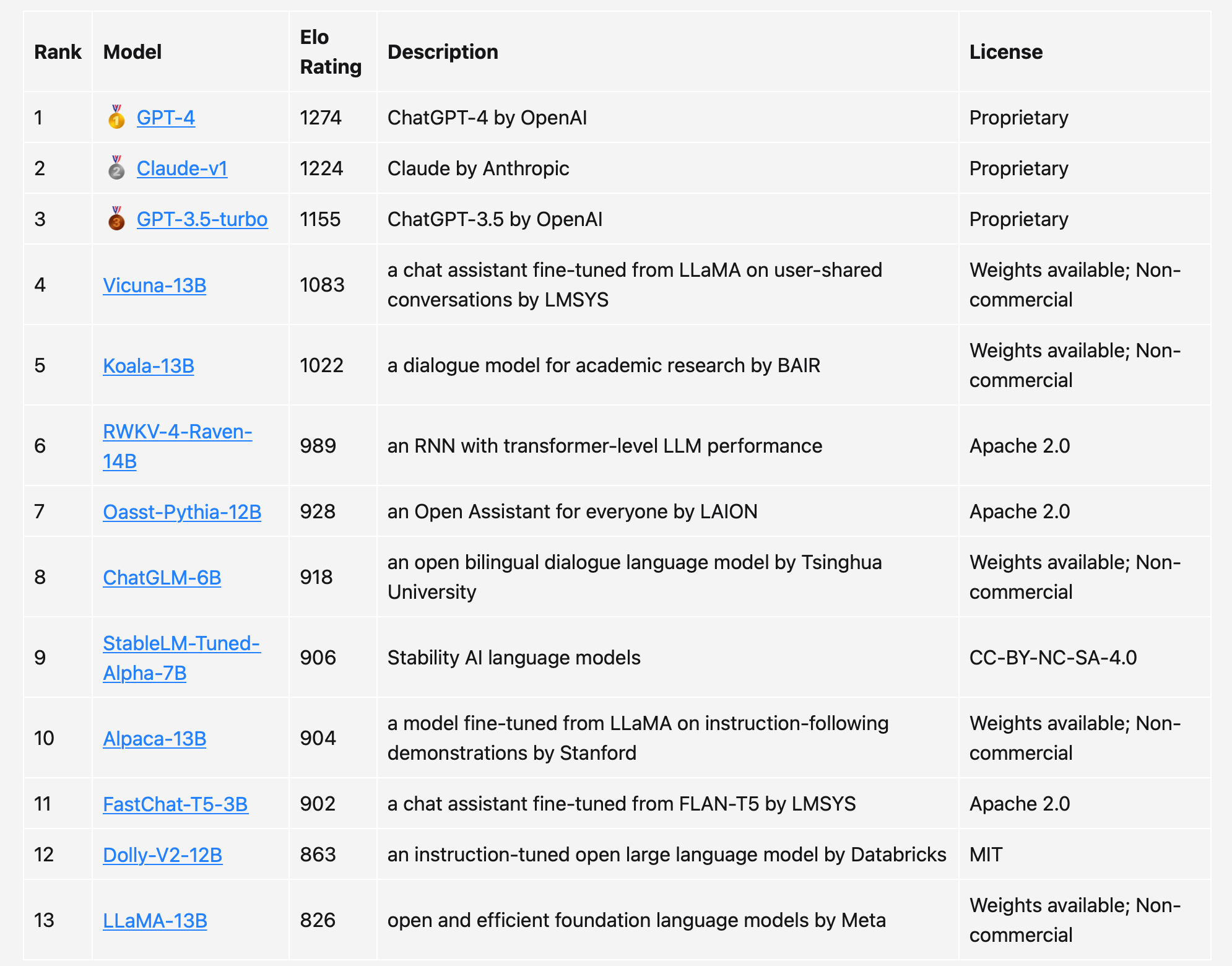
140亿参数的「纯RNN模型」RWKV-4-Raven-14B凭借着卓越的表现,超越一众Transformer模型排到了第6——除Vicuna模型外,RWKV在与所有其他开源模型的非平局比赛中赢得了超过50%的比赛。
此外,团队还分别制作了「仅英语」和「非英语」(其中大部分是中文)这两个单独的排行榜。可以看到,不少模型的排位都出现了明显的变化。比如,用更多中文数据训练的ChatGLM-6B确实表现更好,而GPT-3.5也成功超越Claude排到了第二的位置。
本次更新的主要贡献者是盛颖、Lianmin Zheng、Hao Zhang、Joseph E. Gonzalez和Ion Stoica。
盛颖是LMSYS Org的3个创始人之一(另外两位是Lianmin Zheng和Hao Zhang),斯坦福大学计算机科学系的博士生。她也是之前爆火的、可以在单GPU上可以跑175B模型推理的系统FlexGen的一作,目前已获8k星。
参考资料:https://lmsys.org/blog/2023-05-10-leaderboard/
详细分析:https://colab.research.google.com/drive/1iI_IszGAwSMkdfUrIDI6NfTG7tGDDRxZ?usp=sharing
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢