
Towards Expert-Level Medical Question Answering with Large Language Models
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, Mike Schaekermann, Amy Wang, Mohamed Amin, Sami Lachgar, Philip Mansfield, Sushant Prakash, Bradley Green, Ewa Dominowska, Blaise Aguera y Arcas, Nenad Tomasev, Yun Liu, Renee Wong, Christopher Semturs, S. Sara Mahdavi, Joelle Barral, Dale Webster, Greg S. Corrado, Yossi Matias, Shekoofeh Azizi, Alan Karthikesalingam, Vivek Natarajan
介绍了Med-PaLM 2,通过基于新的基础模型(PaLM 2)和医学领域的特定微调,以及包括新的集成改进方法在内的提示策略,实现了医学问答方面的医生水平性能的快速进展。
谷歌健康Dr. Alan Karthikesalingam分享Med-PaLM2模型
-
动机:人工智能系统在诸如围棋和蛋白质折叠等“重大挑战”上取得了里程碑式的进展。检索医学知识、对其进行推理,并能够回答医学问题,被长期视为一个重大挑战。大型语言模型(LLM)在医学问题回答方面取得了显著进展,Med-PaLM首次在MedQA数据集上的美国医学执业考试(USMLE)风格问题中超过了“及格”分数,达到了67.2%的分数。然而,这项研究以及其他之前的工作都表明还有很大的改进空间,尤其是当模型的答案与临床医生的答案进行比较时。
-
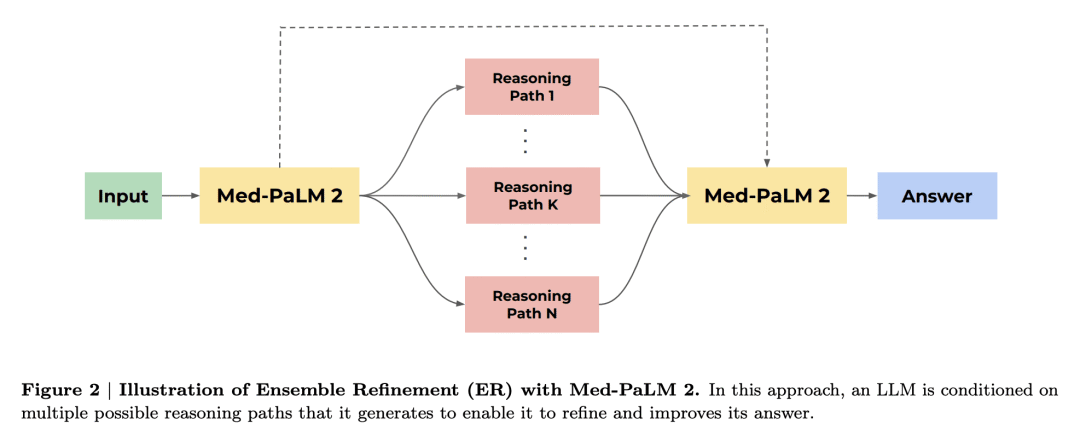
方法:通过结合基础LLM的改进(PaLM 2)、医学领域的微调和提示策略(包括一种新的集成改进方法),利用Med-PaLM 2填补这些差距。
-
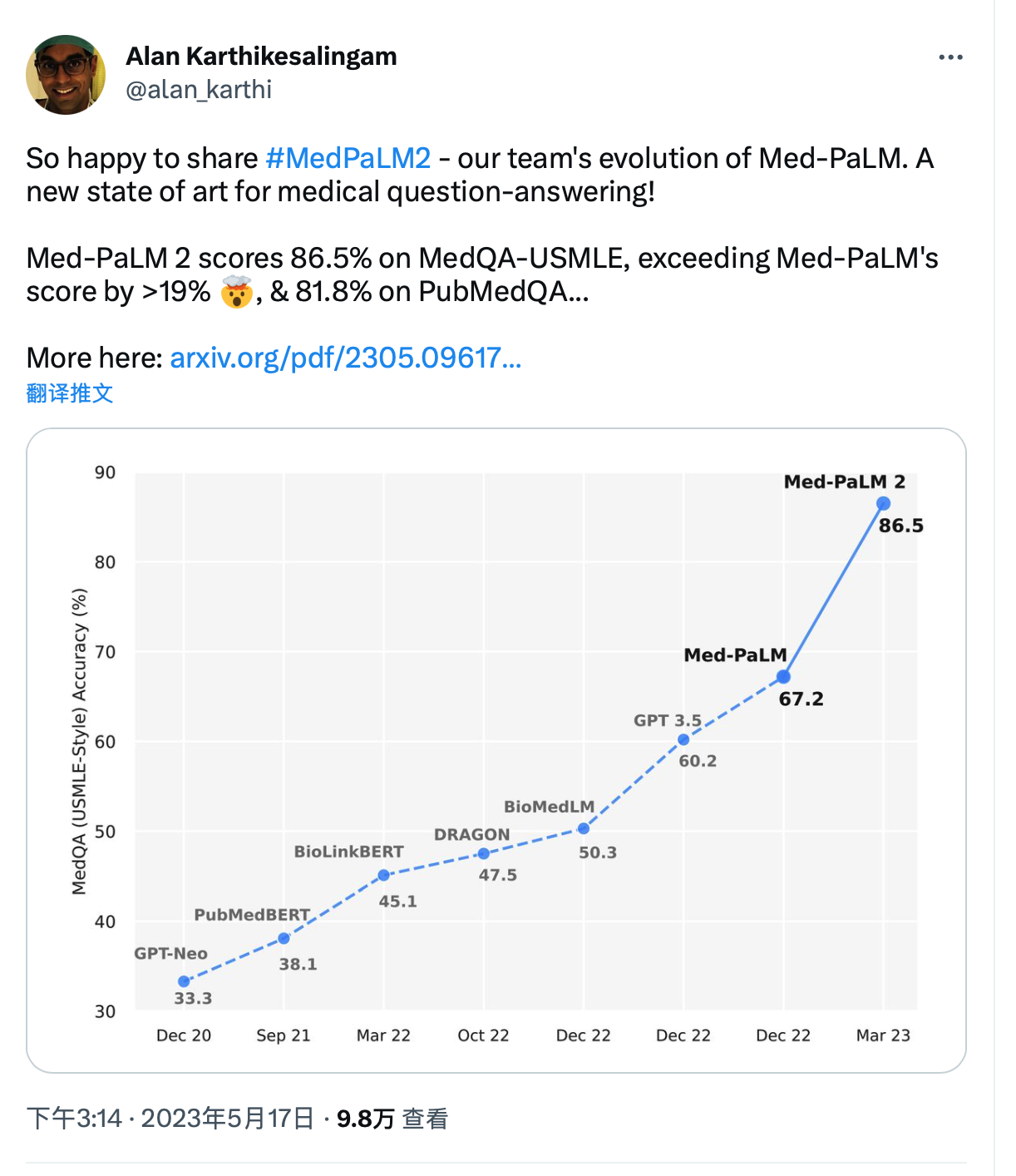
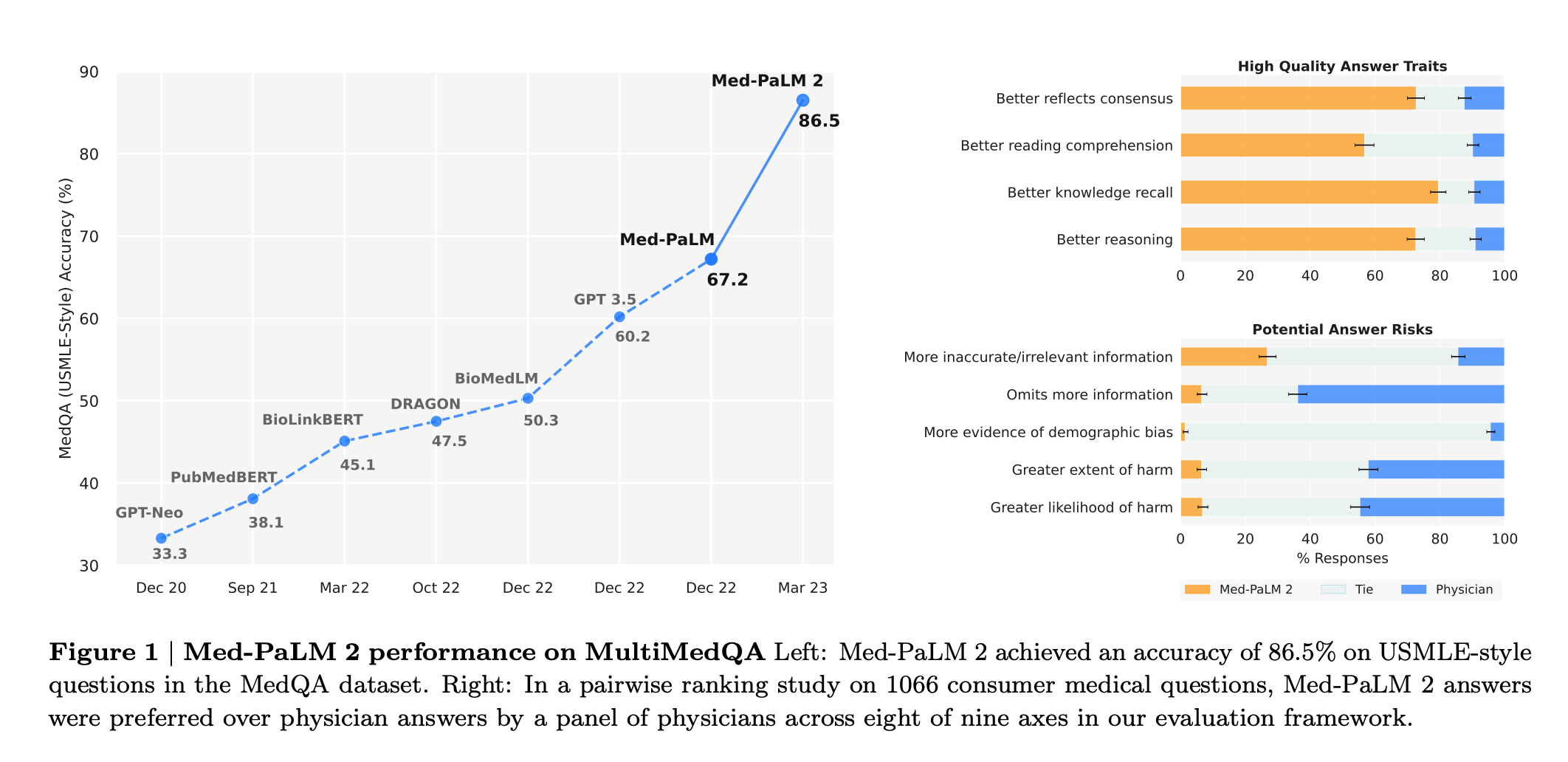
优势:Med-PaLM 2在MedQA数据集上的得分高达86.5%,比Med-PaLM提高了19%以上,创造了新的最高水平。在MedMCQA、PubMedQA和MMLU临床主题数据集上,观察到性能接近或超过了最先进水平。通过对临床应用相关的多个方面进行详细的人类工评估,发现在1066个消费者医学问题的成对比较排名中,医生在与临床实用性相关的九个轴上有八个轴上更喜欢Med-PaLM 2的答案(p < 0.001)。在探测LLM局限性的240个长篇“对抗性”问题的新数据集上,还观察到与Med-PaLM相比在每个评估轴上都有显著改进(p < 0.001)。这些结果突显了医学问题回答方面朝着与医生水平相媲美的表现迅速进展的情况。
解决问题:本论文旨在解决医学领域问题回答的专家级水平,验证大型语言模型在医学问题回答方面的可行性。这是一个新问题,需要解决。
关键思路:本文提出了Med-PaLM 2模型,该模型结合了基础语言模型改进(PaLM 2)、医学领域微调和提示策略,包括新的集成细化方法。与之前的工作相比,Med-PaLM 2在MedQA数据集上的得分提高了19%以上,达到了86.5%,创造了新的最高水平。在MedMCQA、PubMedQA和MMLU临床主题数据集上,该模型的表现也接近或超过了最先进的水平。
其他亮点:本文进行了详细的人类评估,对长篇问题进行了多个与临床应用相关的评估。在1066个消费者医学问题的成对比较排名中,医生在与临床效用有关的九个轴上有八个轴更喜欢Med-PaLM 2的答案(p <0.001)。在新引入的240个“对抗性”长篇问题数据集上,该模型在每个评估轴上与Med-PaLM相比都有显着的改进(p <0.001)。
论文摘要:最近的人工智能系统已经在“大挑战”方面取得了里程碑式的成就,从围棋到蛋白质折叠。检索医学知识,对其进行推理,并回答医学问题,与医生相当的能力长期以来一直被视为这样一个大挑战。
大型语言模型(LLM)在医学问题回答方面取得了显著进展;Med-PaLM是第一个在MedQA数据集上以67.2%的得分超过“及格”分数的美国医学执照考试(USMLE)风格问题的模型。然而,这项工作和其他先前的工作表明,仍有大量改进的空间,特别是当将模型的答案与临床医生的答案进行比较时。
在这里,我们提出了Med-PaLM 2,它通过利用基础LLM改进(PaLM 2)、医学领域微调和提示策略(包括一种新的集成细化方法)来弥合这些差距。
Med-PaLM 2在MedQA数据集上的得分高达86.5%,比Med-PaLM提高了超过19%,并创造了一个新的最先进水平。我们还观察到在MedMCQA、PubMedQA和MMLU临床主题数据集上接近或超过最先进水平的表现。我们对与临床应用相关的多个方面的长形式问题进行了详细的人类评估。
在1066个消费者医学问题的成对比较排名中,医生在与临床效用有关的九个轴上有八个轴更喜欢Med-PaLM 2的答案(p <0.001)。我们还观察到,在新引入的240个长形式“对抗性”问题的数据集上,在每个评估轴上与Med-PaLM相比都有显着改进(p <0.001)。虽然需要进一步研究来验证这些模型在实际环境中的功效,但这些结果突显了在医学问题回答方面朝着医生级别的表现的快速进展。
https://arxiv.org/pdf/2305.09617.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢