
Measuring Progress in Fine-grained Vision-and-Language Understanding
Benjamin Gutteridge, Xiaowen Dong, Michael Bronstein, Francesco Di Giovanni
[DeepMind]
细粒度视觉-语言理解进展分析
-
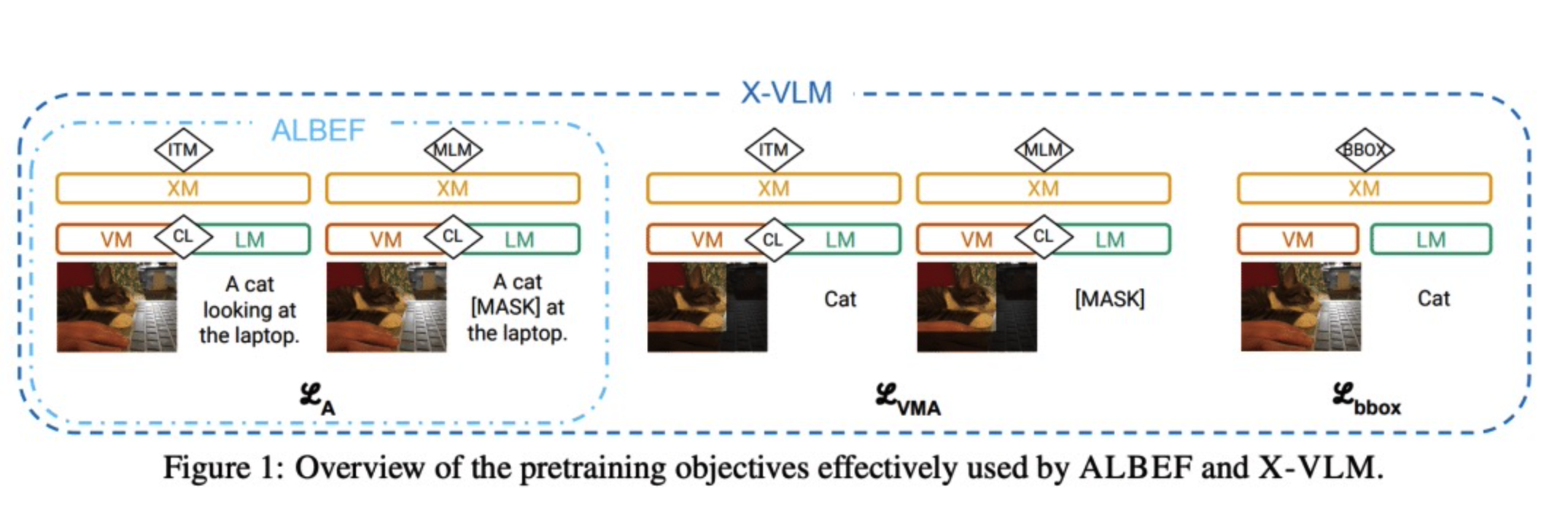
动机:最近的研究表明,预训练模型在细粒度理解方面存在不足,如在图像中识别关系、动词和数字的能力。为了更好地了解和量化在这方面的进展,本文对四个细粒度基准上的四个竞争性视觉语言模型进行了研究。 -
方法:通过对数据和建模决策对细粒度任务性能的影响进行深入分析,发现X-VLM模型在四个基准上始终优于其他基线模型,并且建模创新对性能的影响大于扩大Web数据规模,有时甚至会降低性能。通过对X-VLM的深入研究,本文强调了新的损失和丰富的数据源对学习细粒度技能的重要性。最后,对训练动态进行了调查,发现对于某些任务,性能在训练早期达到峰值或明显波动,从未收敛。 -
优势:深入分析数据和建模决策对细粒度任务性能的影响,对最佳模型(X-VLM)的数据和预训练损失提供进一步解释。结果表明,在细粒度理解方面取得进展,建模创新和数据质量与丰富性比仅扩大Web数据规模更有效。揭示了视觉语言模型的预训练动态,并建议未来的研究应重新审视预训练策略以在多个任务上实现持续改进。
通过深入分析数据和建模决策的影响,以及对最佳模型的探索,提升了细粒度视觉语言理解任务的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢