
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
来自普林斯顿大学和Google DeepMind研究人员提出了一种全新的语言模型推理框架——「思维树」(ToT)。ToT将当前流行的「思维链」方法泛化到引导语言模型,并通过探索文本(思维)的连贯单元来解决问题的中间步骤。
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, Karthik Narasimhan
[Princeton University & Google DeepMind]
关于作者
论文一作Shunyu Yao是普林斯顿大学的四年级博士生,此前毕业于清华大学的姚班。他的研究方向是在语言智能体与世界之间建立互动。
Dian Yu是Google DeepMind的一名研究科学家。他在加州大学戴维斯分校获得了博士学位,并在纽约大学获得了学士学位,双主修计算机科学和金融,他的研究兴趣是语言的属性表征,以及多语言和多模态的理解,主要专注于对话研究。
Yuan Cao也是Google DeepMind的一名研究科学家。他在上海交通大学获得了学士和硕士学位,并在约翰斯·霍普金斯大学获得了博士学位。曾担任过百度的首席架构师。
Jeffrey Zhao是Google DeepMind的软件工程师。此前,他在卡内基梅隆大学获得了学士和硕士学位。
论文地址:https://arxiv.org/abs/2305.10601
「思维树」可以让LLM:
· 自己给出多条不同的推理路径
· 分别进行评估后,决定下一步的行动方案
· 在必要时向前或向后追溯,以便实现进行全局的决策
ToT显著提高了LLM在三个新任务(24点游戏,创意写作,迷你填字游戏)中的问题解决能力。比如,在24点游戏中,GPT-4只解决了4%的任务,但ToT方法的成功率达到了74%。
要点:
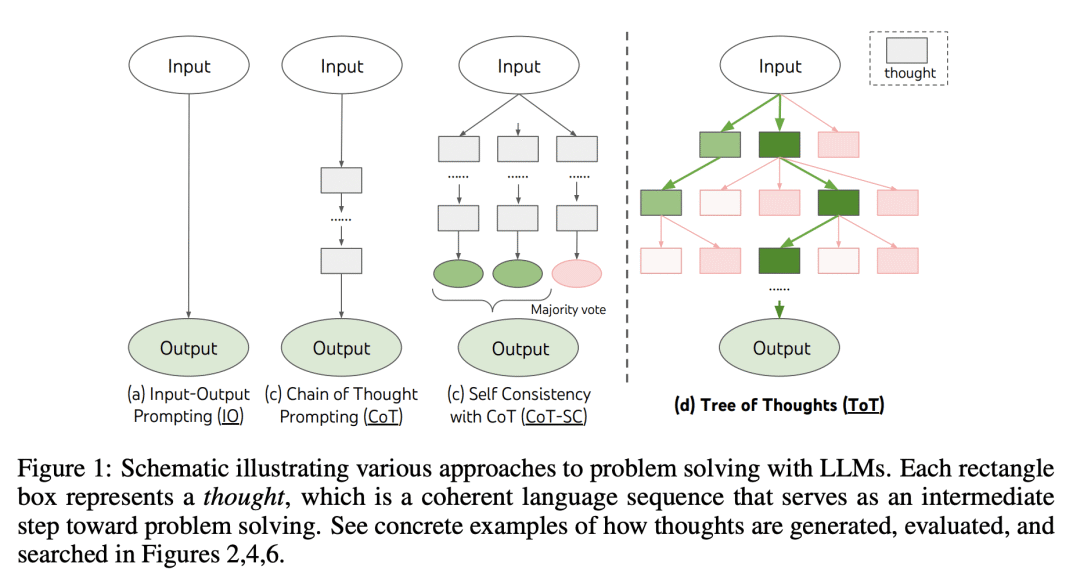
动机:解决语言模型在问题求解中的局限性,特别是对于需要探索、策略先见性或初始决策起关键作用的任务。为克服这些挑战,引入一种新的语言模型推理框架"Tree of Thoughts"(ToT),通过提供具有连贯性的文本单元("thoughts")的探索,使语言模型能够进行有意识的决策过程,考虑多个不同的推理路径并自我评估选择以决定下一步行动。
方法:提出"Tree of Thoughts"(ToT)框架,通过维护一棵思维树,每个思维是一条连贯的语言序列,作为问题求解的中间步骤,实现语言模型的有意识推理过程。通过与搜索算法(如广度优先搜索或深度优先搜索)结合,允许系统性地探索思维树并进行前瞻和回溯。
优势:ToT框架显著提升了语言模型在需要复杂规划或搜索的任务中的问题求解能力。在Game of 24、Creative Writing和Mini Crosswords等任务中,ToT方法的成功率明显高于传统的prompting方法,例如在Game of 24中,使用ToT方法的成功率达到74%。ToT框架提供了一种直观的方式来观察模块,从而增强了模型的可解释性。
Tree of Thoughts"(ToT)框架为语言模型提供了有意识的决策过程,通过探索连贯的文本单元来解决问题,显著提升了语言模型在复杂任务中的问题解决能力。
论文名称:
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
论文链接:
https://arxiv.org/pdf/2305.10601.pdf
语言模型越来越多地被部署用于解决各种任务中的一般问题,但在推理过程中仍然局限于令牌级别的从左到右的决策过程。这意味着他们可能无法完成需要探索、战略展望或初始决策发挥关键作用的任务。为了克服这些挑战,我们引入了一种新的语言模型推理框架“思想树”(ToT),它概括了流行的“思想链”方法来提示语言模型,并能够探索连贯的文本单元(“思想”),作为解决问题的中间步骤。ToT允许LMs通过考虑多个不同的推理路径和自我评估选择来进行深思熟虑的决策,以决定下一个行动方案,并在必要时前瞻或回溯以做出全局选择。我们的实验表明,ToT显著提高了语言模型的问题解决能力。
根据经验,我们提出了三个新问题,即使使用最先进的语言模型GPT-4,也会挑战现有的LM推理方法:24小时游戏、创造性写作和交叉词。这些任务需要演绎、数学、常识、词汇推理能力,以及结合系统规划或搜索的方法。我们表明,ToT在所有三项任务中都能获得优异的结果,因为它足够通用和灵活,能够支持不同级别的思想、生成和评估思想的不同方法,以及适应不同问题性质的不同搜索算法。我们还分析了这些选择如何通过系统消融影响模型性能,并讨论了更好地训练和使用LMs的未来方向。
对人类解决问题的研究表明,人们在组合问题空间中搜索——这是一棵树,其中节点表示部分解决方案,分支对应于修改它们的运算符。采取哪一个分支是由启发式决定的,启发式有助于导航问题空间并引导问题解决者找到解决方案。这一观点突出了使用LM解决一般问题的现有方法的两个关键缺点:1)在局部上,它们没有探索思维过程中的不同延续——树的分支。2) 在全球范围内,它们不包含任何类型的计划、前瞻或回溯来帮助评估这些不同的选项——这种启发式引导搜索似乎是人类解决问题的特征。
为了解决这些缺点,我们引入了思想树(ToT),这是一种范式,允许LM探索思想的多种推理路径(图1(c))。ToT将任何问题定义为在树上的搜索,其中每个节点都是一个状态s=[x;z1···i],表示到目前为止具有输入和思想序列的部分解。ToT的一个具体实例化涉及回答四个问题:1。如何将中间过程分解为思维步骤;2.如何从每种状态中产生潜在的想法;3.如何启发式地评估状态;4.使用什么搜索算法。
思想分解
虽然CoT在没有显式分解的情况下对思想进行连贯采样,但ToT利用问题属性来设计和分解中间思想步骤。如表1所示,根据不同的问题,一个想法可以是几个单词(交叉词)、一行方程式(24的游戏)或一整段写作计划(创造性写作)。一般来说,一个想法应该足够“小”,以便LMs可以生成有希望的和多样化的样本(例如,生成一整本书通常太“大”而不连贯),但也应该足够“大”,以便LM可以评估其解决问题的前景(例如,生成一个令牌通常太“小”而无法评估)。
评估
给定不同状态的边界,状态评估器评估他们在解决问题方面所取得的进展,作为搜索算法的启发式方法,以确定要继续探索哪些状态以及以何种顺序进行探索。虽然启发式是解决搜索问题的标准方法,但它们通常是编程的(例如DeepBlue)或学习(例如AlphaGo)。我们提出了第三种替代方案,通过使用LM来故意对状态进行推理。在适用的情况下,这种深思熟虑的启发式方法可以比编程规则更灵活,并且比学习模型更具样本效率。与思想生成器类似,我们考虑两种策略来独立或一起评估状态:对于这两种策略,我们可以多次提示LM聚合价值或投票结果,以时间/资源/成本换取更忠实/更稳健的启发式。
搜索算法
最后,在ToT框架内,可以根据树结构,即插即用不同的搜索算法。我们探索了两种相对简单的搜索算法,并将更高级的算法(例如A*、MCTS)留给未来的工作:从概念上讲,ToT作为使用LMs解决一般问题的方法有几个好处:
(1)一般性。IO、CoT、CoT-SC和自精化可以被视为ToT的特殊情况(即深度和广度有限的树)。
(2) 模块化。基本LM以及思想分解、生成、评估和搜索过程都可以独立变化。
(3) 适应性。可以适应不同的问题属性、LM能力和资源约束。
(4) 方便。不需要额外的培训,只要一个经过预先培训的LM就足够了。下一节将展示这些概念上的好处如何转化为不同问题中强大的经验表现。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢