
LIMA: Less Is More for Alignment
Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, Omer Levy
[Meta AI & CMU]
介绍 LIMA,这是一种 65B LLaMa 语言模型,仅在 1k 个精选样本上进行了微调,没有 RLHF。 LIMA 的输出分别在 43% 或 58% 的情况下与 GPT-4 或 Bard 相当或严格首选。
作为当前 AI 领域的顶流,ChatGPT、GPT-4 等大模型在文本理解、生成、推理等方面展现出强大的能力,这离不开其背后的生成领域训练新范式 ——RLHF (Reinforcement Learning from Human Feedback) ,即以强化学习的方式依据人类反馈优化语言模型。
使用 RLHF 方法,大型语言模型可与人类偏好保持对齐,遵循人类意图,最小化无益、失真或偏见的输出。但 RLHF 方法依赖于大量的人工标注和评估,因此成本非常高昂。
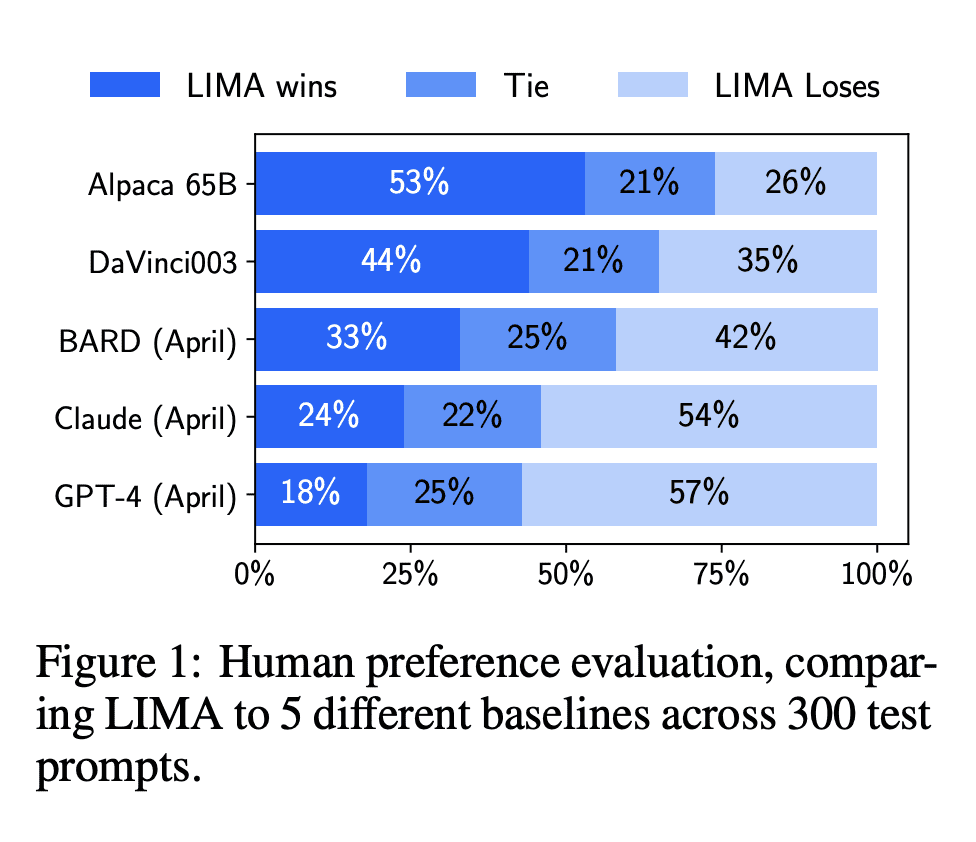
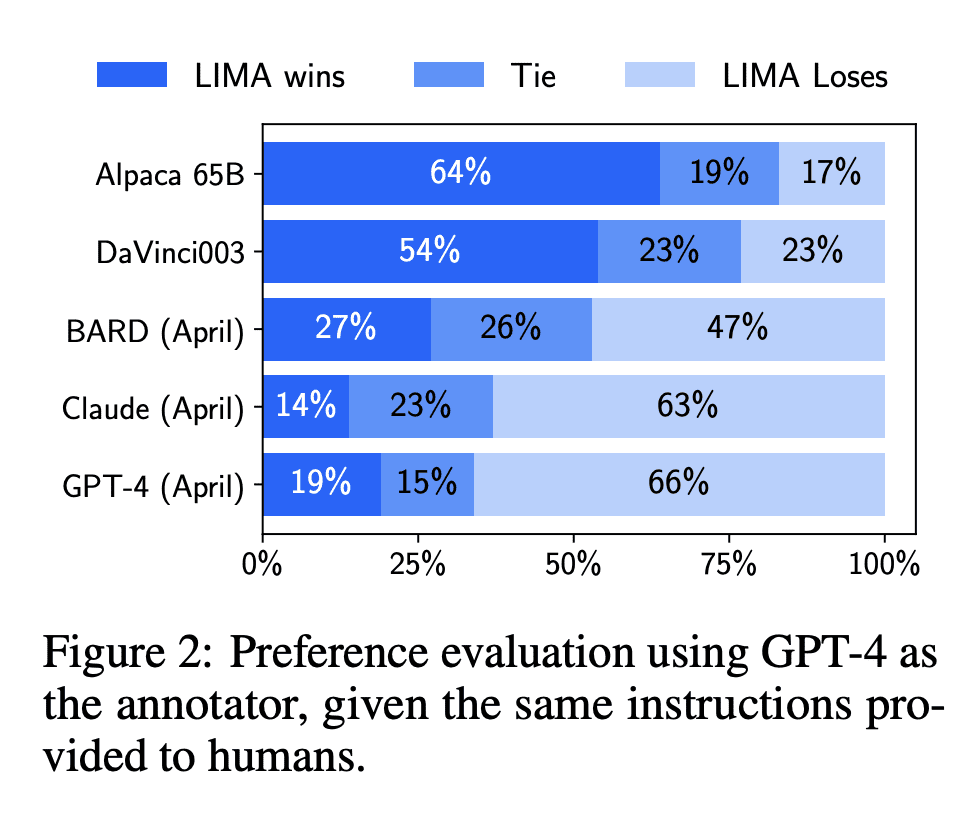
该研究使用了一个 65B 参数的 LLaMa 模型(该模型称为 LIMA)在 1000 个精选样本上进行有监督学习,在完全没使用 RLHF 方法的情况下,LIMA 表现出非常强大的性能,并且能够很好地泛化到训练数据以外的任务上。在人类评估结果中,LIMA 甚至可与 GPT-4、Bard、DaVinci003 相媲美。图灵奖得主 Yann LeCun 也转推称赞这项研究。

研究表明,几乎所有知识都是在预训练阶段学习的,通过仅使用少量的指令微调数据,可以教会语言模型产生高质量输出。
论文地址:https://arxiv.org/abs/2305.11206
LIMA: 大型语言模型对齐少即是多
动机:研究大型语言模型的训练过程,通过比较模型的两个阶段(无监督预训练和大规模指令微调),衡量它们的相对重要性。通过训练LIMA,一个使用标准监督损失在仅1,000个精心挑选的提示和响应上进行了微调的65B参数的LLaMa语言模型,证明了几乎所有知识都是在预训练阶段学习的,仅需少量指令微调数据就可以教会模型产生高质量的输出。
方法:通过在仅有少量样本的训练数据上进行监督微调,研究了模型在学习特定响应格式和处理各种任务的能力。与其他语言模型和产品进行了对比实验,并进行了人工偏好研究和人工评估。
优势:LIMA展现出出色的性能,仅从训练数据中的少量示例中学会了遵循特定响应格式的能力,并在未出现在训练数据中的任务上具有良好的泛化能力。与其他模型相比,在人工偏好研究中,在43%的情况下,LIMA的响应要么等同于GPT-4,要么被严格优先选择。这些结果强烈表明,在大型语言模型中几乎所有的知识都是在预训练阶段学习的,只需要有限的指令微调数据就可以教会模型产生高质量的输出。
我们知道训练大型语言模型需要两个步骤:
-
在原始内容中进行无监督预训练,以学习通用表征;
-
大规模指令微调和强化学习,以更好地对齐最终任务和用户偏好。
该研究训练了一个 65B 参数的 LLaMa 语言模型「LIMA」,以衡量这两个步骤的重要程度。LIMA 仅在 1000 个精选 prompt 和回答(response)上使用标准监督损失进行微调,不涉及任何强化学习或人类偏好建模。
LIMA 能够从训练数据的少量样本中学习遵循特定的回答格式,包括从计划旅行行程到推测备用历史的复杂查询。并且,该模型能够很好地泛化到训练数据以外的新任务上。在一项人体对照试验中,LIMA 在 43% 的病例中疗效都与 GPT-4 媲美甚至更好;相比于 Bard,占比能够达到 58%;更别说与使用人类反馈训练的 DaVinci003 对比了,这个数字高达 65%。
该研究根据对比结果总结道:大型语言模型中几乎所有的知识都是在预训练期间学习的,并且想让模型产生高质量的输出只需要部分必要的指令调优数据。这一点与 RLHF 方法不同,将有助于大型语言模型(LLM)降低训练成本。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢