
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
J Ainslie, J Lee-Thorp, M d Jong, Y Zemlyanskiy, F Lebrón, S Sanghai
[Google Research]
GQA: 从多头检查点训练通用多查询Transformer模型
要点:
-
动机:改进多查询注意力(MQA)的性能,以加速解码器的推理速度。现有的MQA方法可能导致质量下降,并且为了更快的推理速度需要训练单独的模型,并不理想。 -
方法:通过预训练模型进行上训练(uptraining),将现有的多头注意力(MHA)模型转换为使用MQA的模型,并引入分组查询注意力(GQA),多查询注意力和多头注意力的一种泛化方法。GQA使用中间数量的键值头(大于一个,小于查询头的数量),实现了性能和速度的平衡。 -
优势:论文的主要优势是通过上训练(uptraining)现有模型,以较小的计算成本将多头注意力模型转换为多查询模型,从而实现快速的多查询和高质量的推理。同时,引入的分组查询注意力方法在接近多头注意力的质量的同时,速度几乎与多查询注意力相当。
GQA是一种训练通用多查询Transformer模型的方法,通过上训练现有的多头注意力模型并引入分组查询注意力,实现了快速推理和高质量输出。
Multi-query attention (MQA), which only uses a single key-value head, drastically speeds up decoder inference. However, MQA can lead to quality degradation, and moreover it may not be desirable to train a separate model just for faster inference. We (1) propose a recipe for uptraining existing multi-head language model checkpoints into models with MQA using 5% of original pre-training compute, and (2) introduce grouped-query attention (GQA), a generalization of multi-query attention which uses an intermediate (more than one, less than number of query heads) number of key-value heads. We show that uptrained GQA achieves quality close to multi-head attention with comparable speed to MQA.
https://arxiv.org/abs/2305.13245
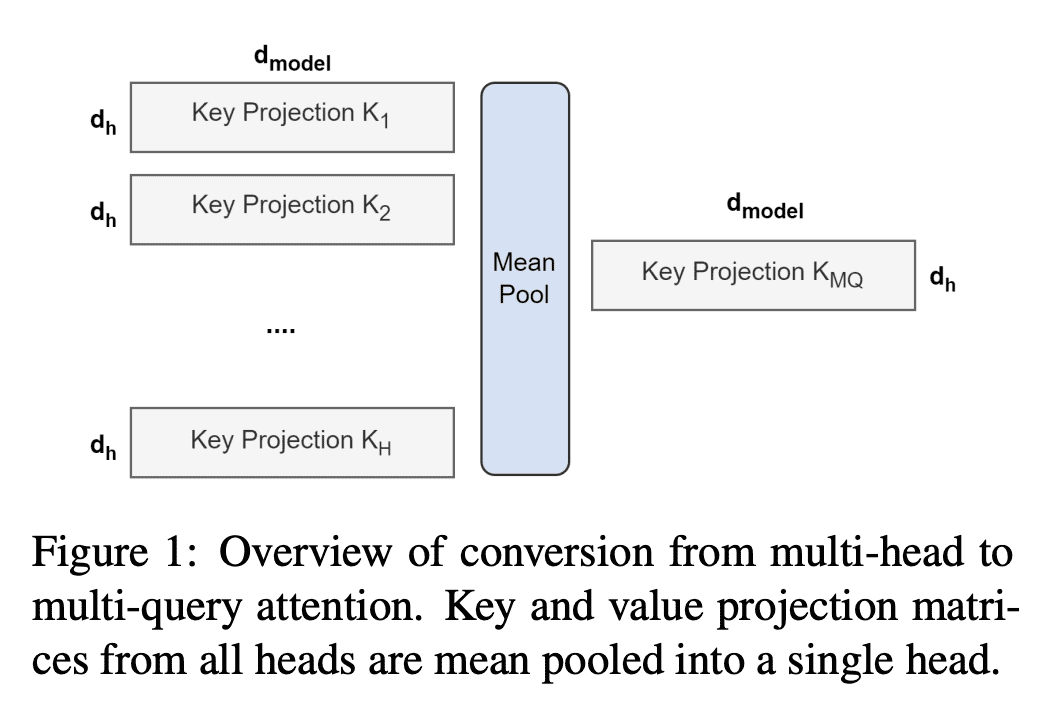
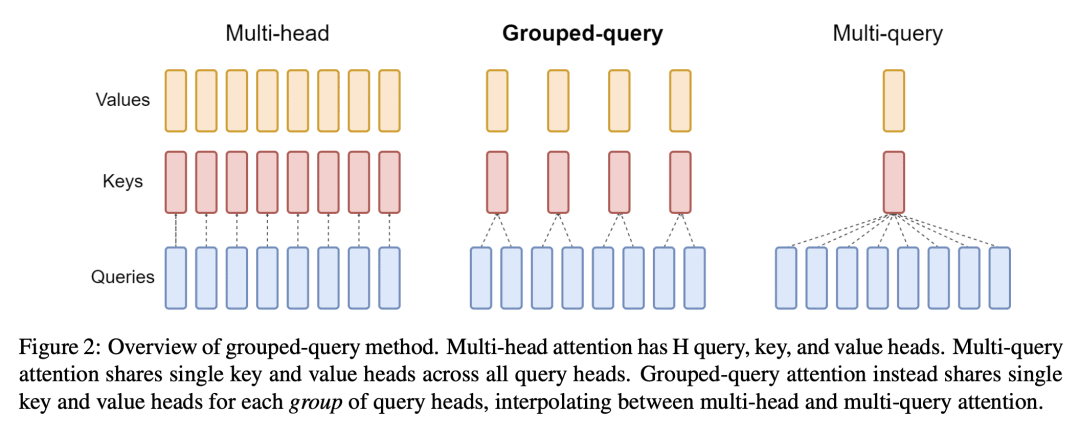
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢