
A Pretrainer’s Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity
S Longpre, G Yauney, E Reif…
[Google Research & MIT & Cornell University]
预训练数据指南: 数据时效、领域覆盖、质量和毒性的影响
要点:
-
动机:解决预训练数据设计的问题,这在开发能力强的语言模型中起到了初步和基础性的作用。现有的预训练数据设计方法缺乏系统的文献记录,常常依赖经验不支持的直觉。因此,本文旨在通过对不同时间、不同毒性和质量过滤以及不同领域组成的数据进行预训练,对预训练数据进行量化分析,以验证和量化文本预训练的一些未记录直觉,并帮助在语言模型开发中做出更明智的基于数据的决策。 -
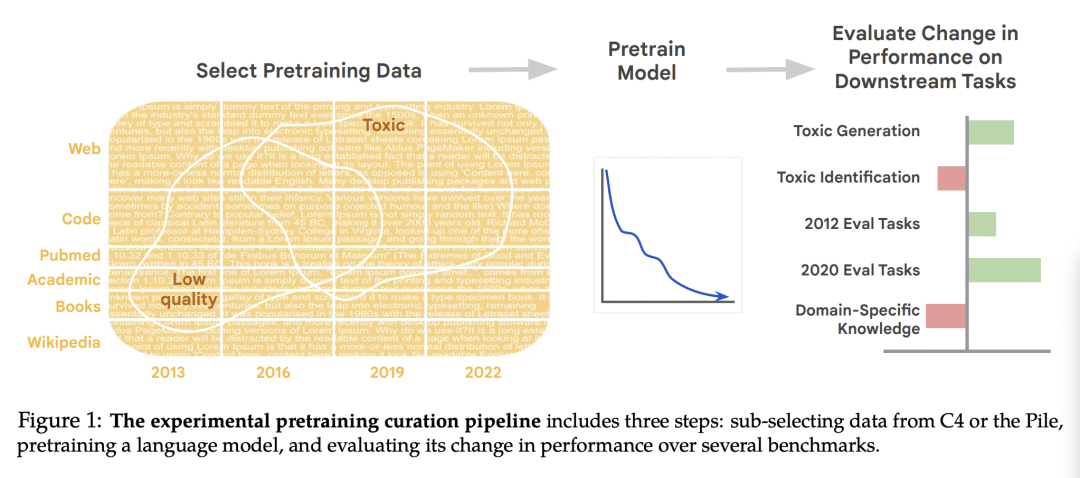
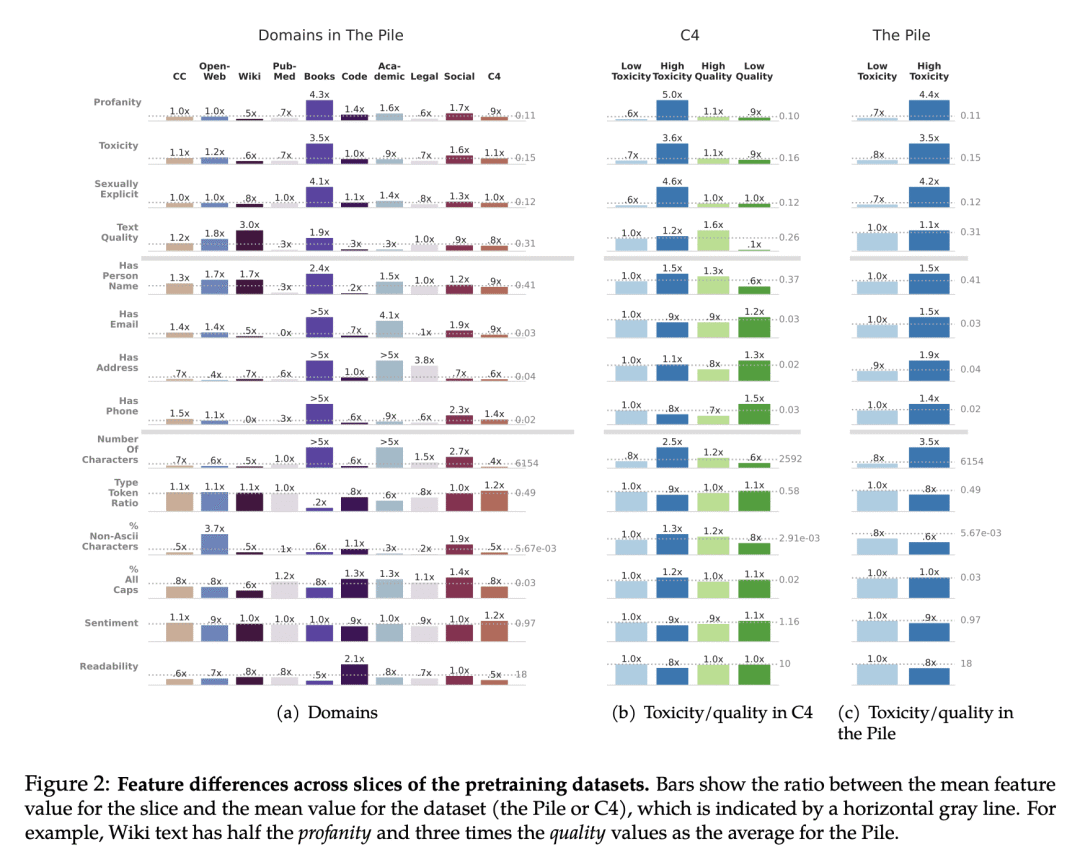
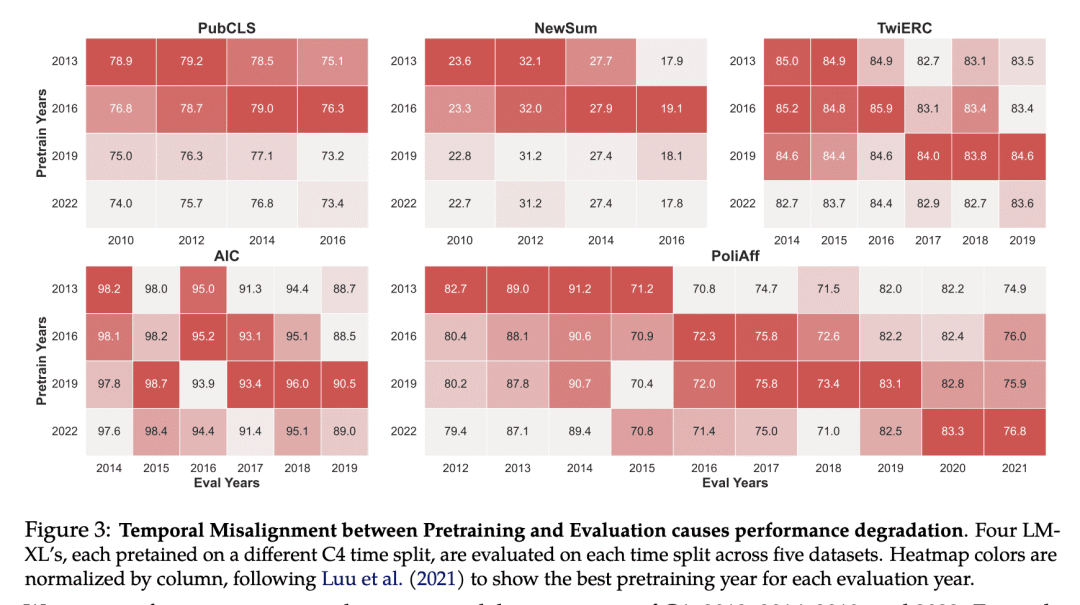
方法:使用28个1.5B参数的仅解码器模型进行预训练,使用具有不同时间、毒性和质量过滤以及领域组成的数据。通过对预训练数据时效的影响进行量化分析,探索质量和毒性过滤的影响,并验证包含异构数据源(如图书和网络)的效果。此外,还通过在下游任务上对修改后的数据集进行评估,系统地测试常见数据设计决策对模型性能的影响。 -
优势:通过大规模实验证明了预训练数据的设计决策对模型行为的重要影响,并提出了针对模型开发者的实用发现和建议。研究结果表明,预训练数据的相对时间、内容过滤器和数据源对下游模型行为具有显著影响,并且这些影响可以通过微调来减少。对于模型开发者和用户来说,关注这些细节在设计或选择最适合其需求的模型时非常重要,因为每个决策都有具体的可量化的权衡。
通过大规模实验证明了预训练数据设计对语言模型行为的重要影响,并提供了实用的发现和建议,为模型开发者提供了更明智的基于数据的决策。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢