
Meta-in-context learning in large language models
J Coda-Forno, M Binz, Z Akata, M Botvinick, J X. Wang, E Schulz
[Max Planck Institute for Biological Cybernetics & University of Tübingen & Google DeepMind]
大型语言模型的元上下文学习
要点:
-
动机:探索大型语言模型(LLM)的元上下文学习能力,即通过上下文学习本身来递归地改进模型的性能。研究大型语言模型的元上下文学习能力是否可以进一步改善。
-
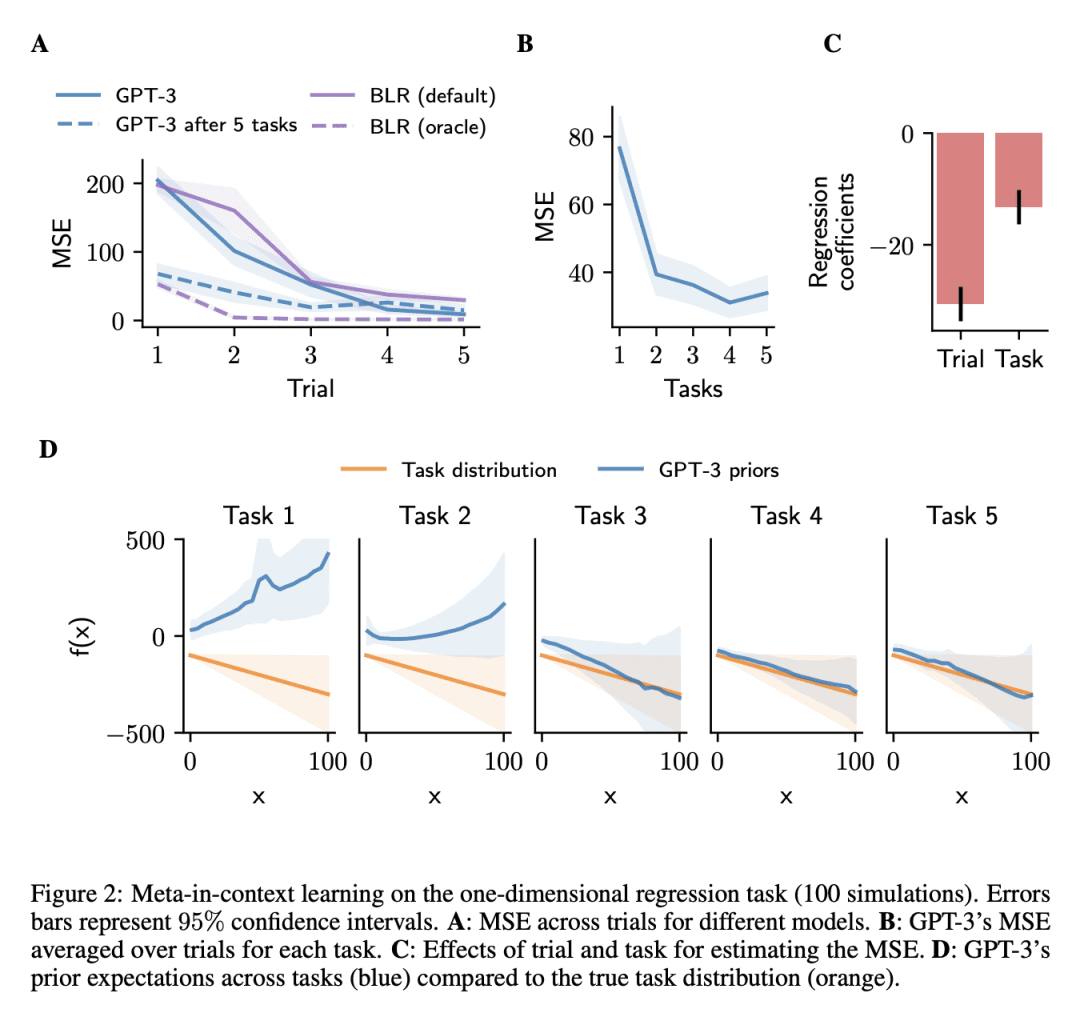
方法:通过在多个学习任务中顺序展示LLM,并进行实验研究,证明了通过元上下文学习可以递归地提升LLM的上下文学习能力,并改变模型的先验知识和学习策略。
-
优势:揭示了大型语言模型的元上下文学习现象,并展示了通过元上下文学习可以使模型性能逐步提升,并在实际回归问题上与传统算法竞争。
通过元上下文学习改进了大型语言模型的性能,并揭示了其先验知识和学习策略的递归性,为模型的应用环境中的自适应提供了新的思路。
https://arxiv.org/abs/2305.12907 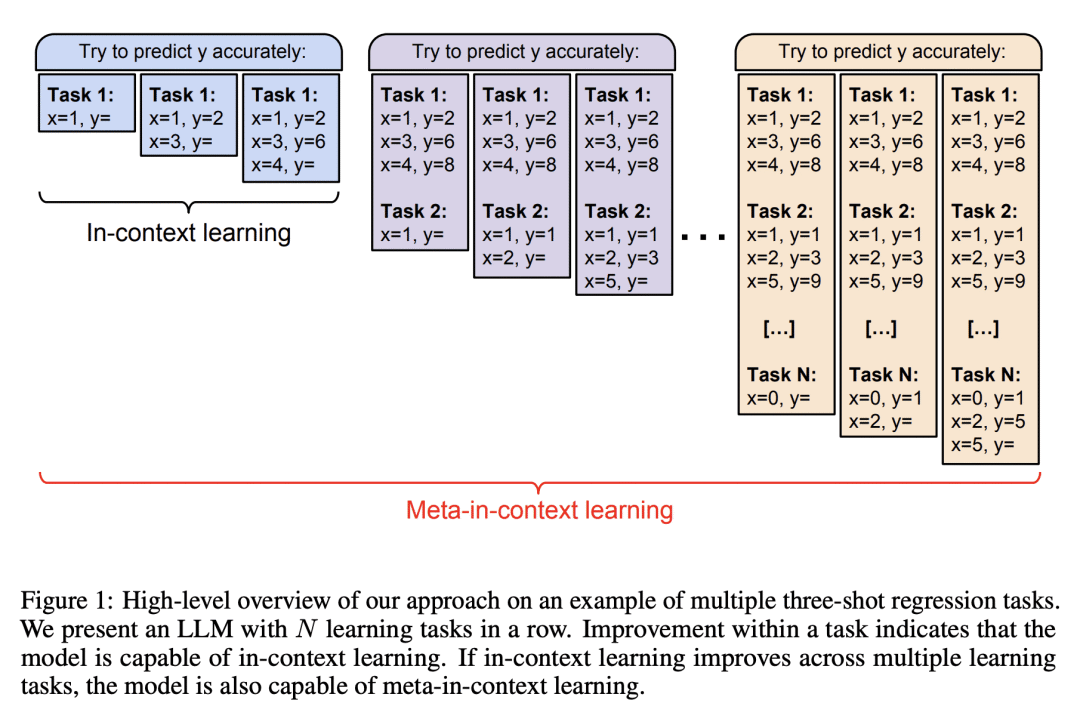
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢