
QLoRA: Efficient Finetuning of Quantized LLMs
T Dettmers, A Pagnoni, A Holtzman, L Zettlemoyer
[University of Washington]
QLoRA:量化LLM高效微调
-
动机:降低内存使用,实现在单个48GB GPU上对65B参数模型进行微调,并保持完整的16位微调任务性能。 -
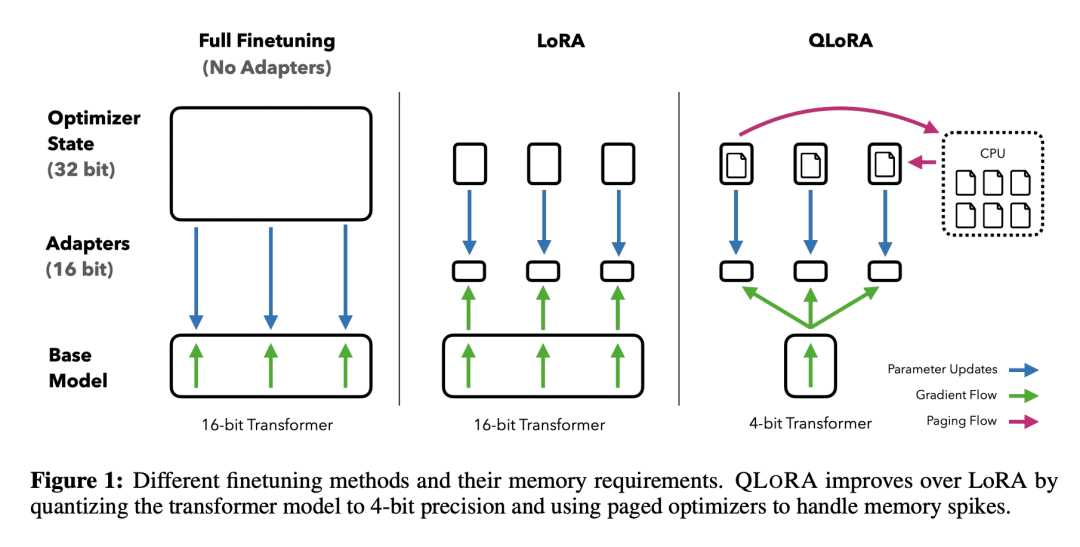
方法:QLORA通过将梯度反向传播到冻结的4比特量化预训练语言模型中,并使用低秩适配器(LoRA),实现了通过少量内存消耗来保持性能的高效微调方法。 -
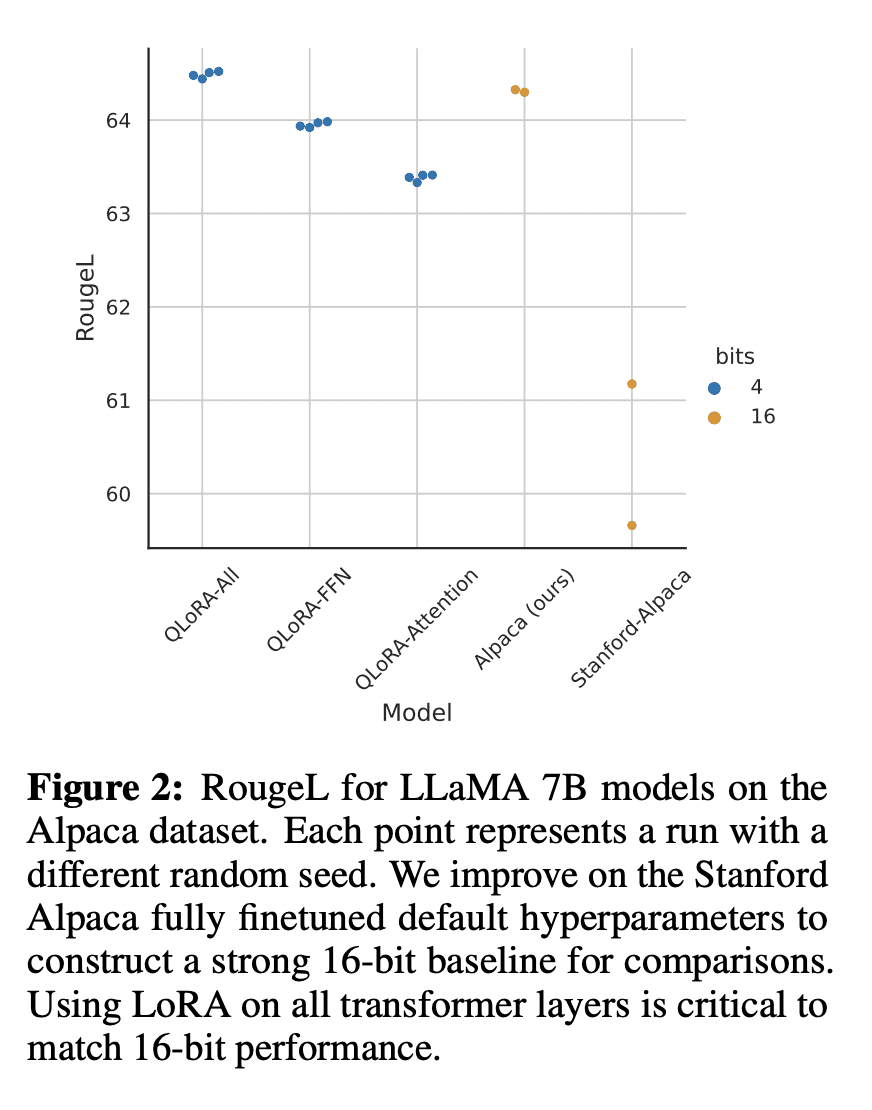
优势:QLORA引入了多项创新,旨在在不牺牲性能的情况下减少内存使用,包括4比特NormalFloat数据类型、双重量化和分页优化器等。同时,QLORA的高效性使得可以进行更深入的指令微调和聊天机器人性能研究,并取得了先进的结果。
一句话总结:
QLORA是一种高效的微调方法,通过降低内存使用,实现在单个GPU上对大型语言模型进行微调,并取得了先进的性能结果。
https://arxiv.org/abs/2305.14314
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢