
VideoLLM: Modeling Video Sequence with Large Language Models
Guo Chen, Yin-Dong Zheng, Jiahao Wang, Jilan Xu, Yifei Huang, Junting Pan, Yi Wang, Yali Wang, Yu Qiao, Tong Lu, Limin Wang
[Nanjing University & Shanghai AI Laboratory] (2023)
VideoLLM:用大型语言模型对视频序列进行建模
-
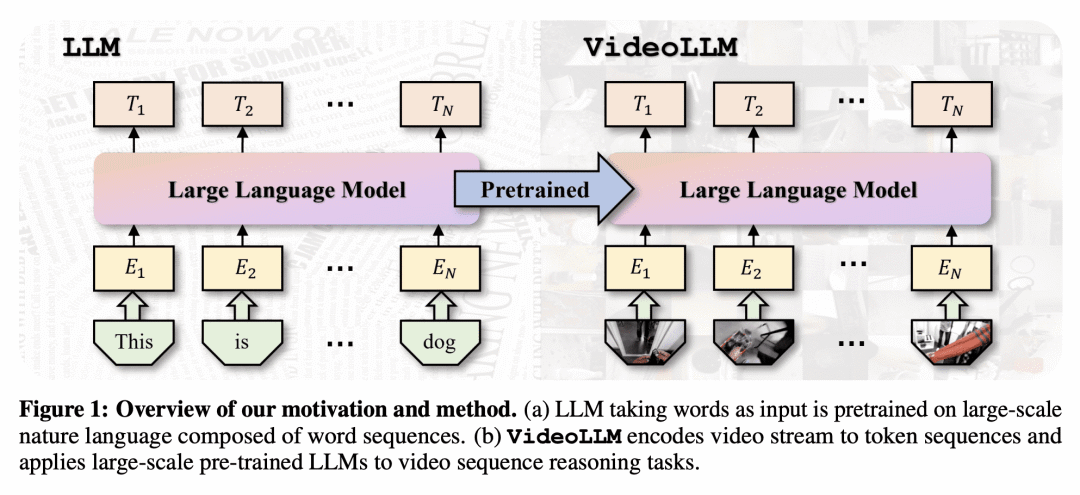
动机:由于视频数据的指数增长,迫切需要自动化技术来分析和理解视频内容。现有的视频理解模型通常是针对特定任务的,缺乏处理多样任务的综合能力。借鉴大型语言模型(LLM)如GPT在序列因果推理方面的成功,提出一种名为VideoLLM的新框架,利用自然语言处理(NLP)中预训练LLM的序列推理能力进行视频序列理解。
-
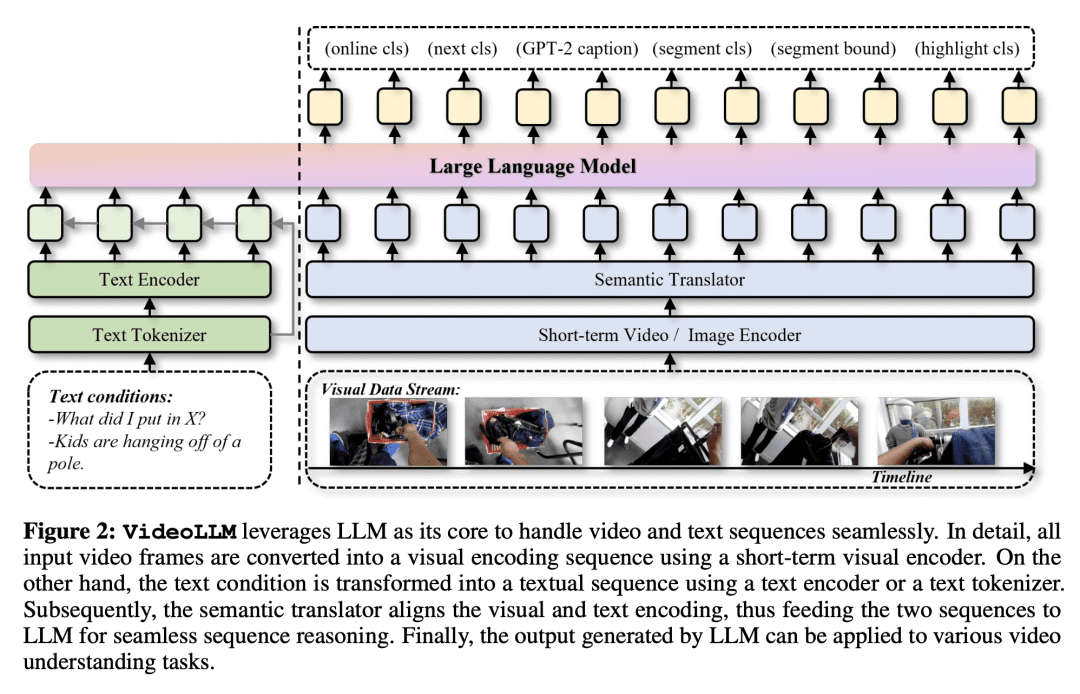
方法:提出VideoLLM框架,包括经过精心设计的模态编码器和语义转换器,将来自不同模态的输入转换为统一的Token序列。然后,将该Token序列输入到decoder-only的LLM中。接下来,通过简单的任务头,VideoLLM为不同类型的视频理解任务提供了一个有效的统一框架。 优势:VideoLLM将LLM的理解和推理能力成功应用于视频理解任务,实现了基于语言的视频序列理解。通过与语言的对齐,VideoLLM能够同时推理语言逻辑和现实世界状态的演变,提供了一种有效的解决方案。实验结果表明,VideoLLM在多个视频理解任务上取得了与或优于任务特定模型相媲美的性能,同时参数量相当或更少。
通过借鉴大型语言模型的序列推理能力,论文提出了VideoLLM框架,将语言和视频对齐,实现了统一的视频理解框架,取得了优于任务特定模型的性能。
https://arxiv.org/abs/2305.13292
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢