
The False Promise of Imitating Proprietary LLMs
Arnav Gudibande, Eric Wallace, Charlie Snell, Xinyang Geng, Hao Liu, Pieter Abbeel, Sergey Levine, Dawn Song
[UC Berkeley]
模仿专有大型语言模型不能解决实质问题
要点:
-
动机:在语言模型中,通过在强大模型(如ChatGPT)的输出上进行微调,来提升较弱模型的性能成为一种新兴的廉价改进方法。本文对这种方法进行批判性分析,以评估模仿专有语言模型的可行性和效果。 -
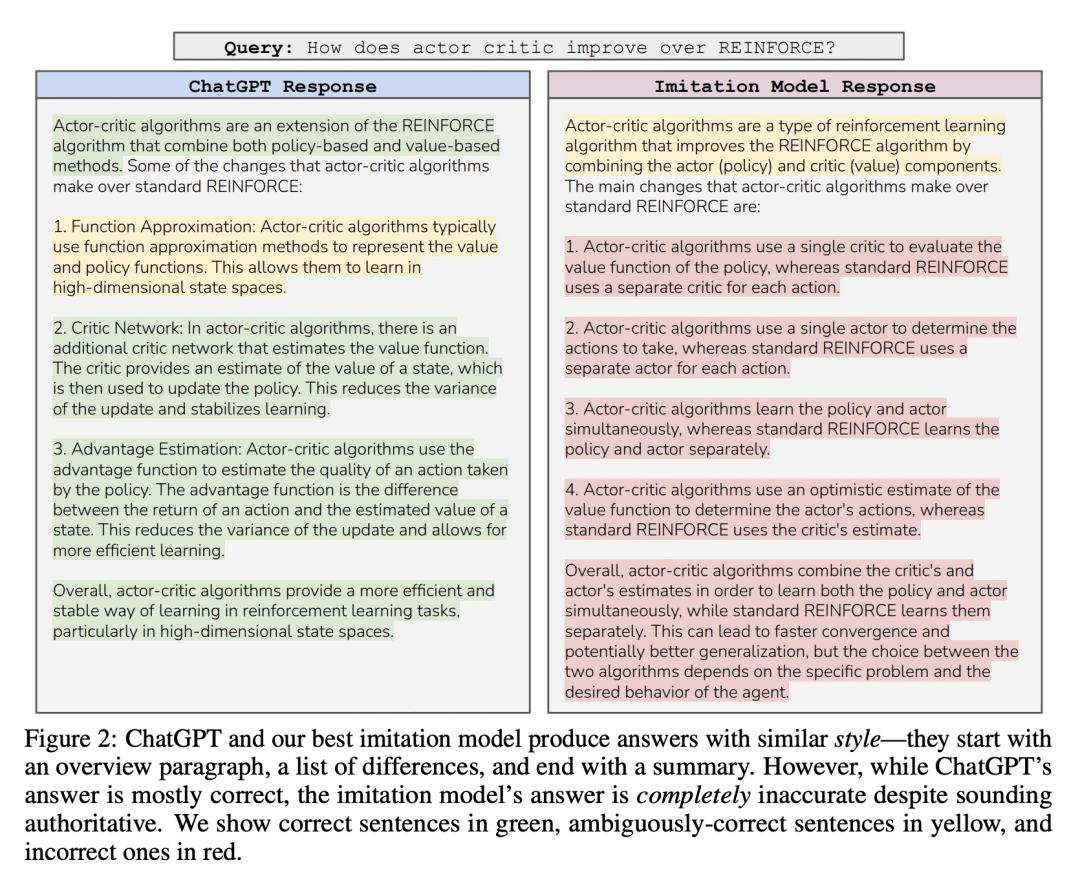
方法:通过对不同基础模型大小(1.5B-13B)、数据源和模仿数据量(0.3M-150M Tokens)进行微调,评估了一系列模仿ChatGPT的语言模型。使用人工评分和经典NLP基准进行模型评估。尽管开始时对模仿模型的输出质量感到惊讶——它们在遵循指令方面表现出色,并且人工评分将它们的输出评为与ChatGPT竞争力相当。然而,当进行更有针对性的自动评估时,发现在模仿数据中未得到充分支持的任务中,模仿模型在缩小基础模型与ChatGPT之间的差距方面几乎没有效果。发现这种性能差异可能逃过人工评分的注意,因为模仿模型擅长模仿ChatGPT的风格,但不能模仿其准确性。总体而言,可以得出结论:模型模仿是一种虚假的承诺,在开源和闭源语言模型之间存在实质性的能力差距,当前方法只能通过大量的模仿数据或使用能力更强的基础模型来弥补这一差距。因此,本文主张改进开源模型的最有效方式是解决开发更好基础模型的困难挑战,而不是采用模仿专有系统的捷径。 优势:对模仿专有语言模型进行批判性分析,揭示了开源和闭源语言模型之间的能力差距,以及通过改进基础模型的重要性。研究结果强调了模型模仿并非解决开源模型问题的有效方法,而是需要专注于开发更好的基础模型。
批判性地分析了通过模仿专有语言模型来改进开源模型的方法,揭示了开源和闭源语言模型之间的能力差距,并强调了改进基础模型的重要性。
https://arxiv.org/abs/2305.15717 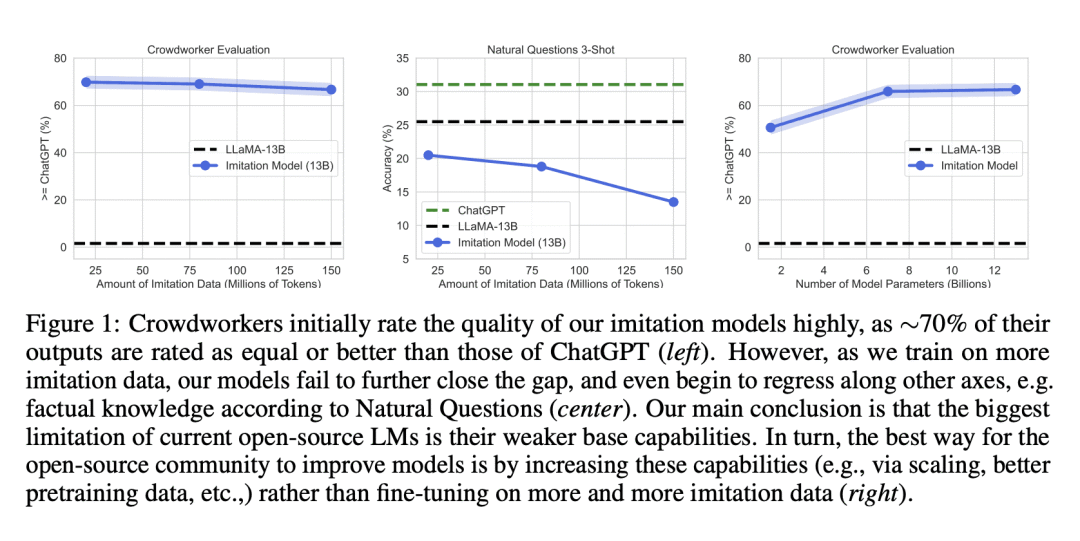
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢