

Scaling Data-Constrained Language Models
Niklas Muennighoff, Alexander M. Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, Colin Raffel
[Hugging Face & Harvard University]
数据受限语言模型扩展
要点:
-
动机:随着语言模型规模的不断扩大,训练数据集的大小可能受限于互联网上可用的文本数据量。本研究的动机是在数据受限的情况下探索语言模型的规模扩展,并研究多次重复数据对模型扩展的影响。 -
方法:通过运行大量实验,对数据重复程度和计算预算进行变化,涵盖了多达9000亿个训练标记和90亿参数模型的范围。研究发现,在受限数据的情况下,使用多次重复数据进行训练与使用唯一数据相比,损失变化可以忽略不计。然而,随着数据的进一步重复,添加计算的价值最终趋于零。研究提出并经验验证了适用于计算最优性的扩展定律,考虑了重复标记和多余参数的价值递减。 优势:量化了数据受限情况下的语言模型规模扩展问题,以及如何在多次重复数据的情况下分配计算资源。研究结果表明,在受限数据的情况下,分配新的计算资源给参数和训练轮次都是必要的,并且训练轮次应稍微加快。此外,研究还探索了在不添加新的自然语言数据的情况下改善下游准确性的方法。
研究了在数据受限情况下语言模型的规模扩展问题,发现多次重复数据对模型扩展有益,并提出了适用于重复数据情况的计算最优性定律。
https://arxiv.org/abs/2305.16264 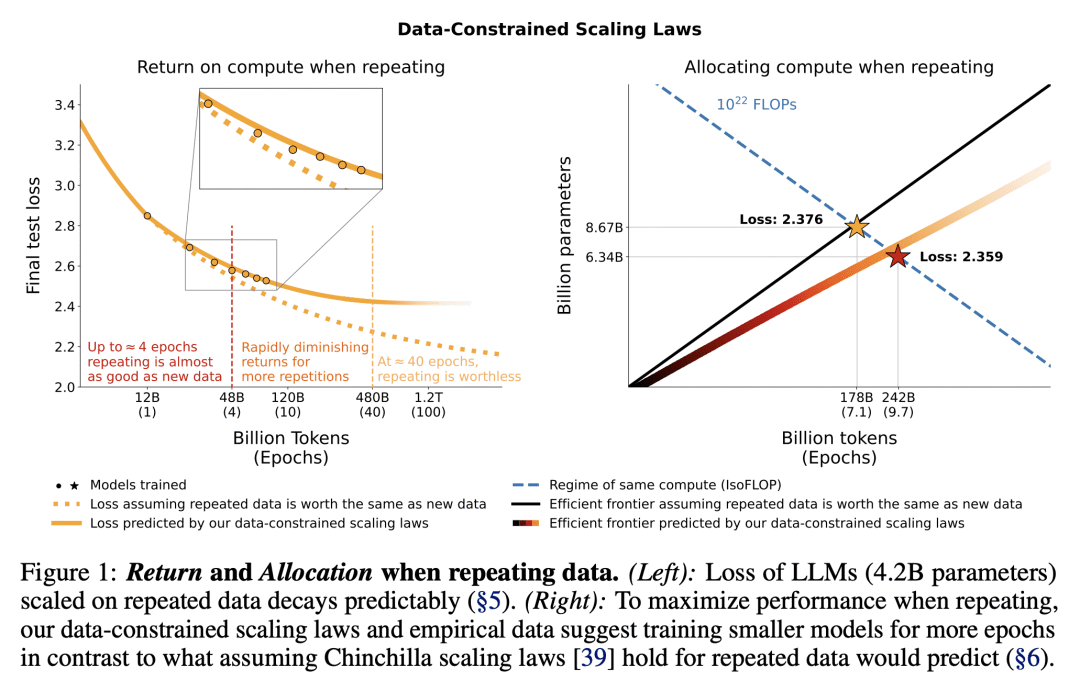

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢