
【编者按:GPT模型以其卓越的生成能力和性能在语言模型中独树一帜。OpenAI作为GPT的背后开发机构,在不断扩大模型规模、改进数据质量和训练技术、增加参数数量等方面取得了显著进展。这些改进推动了模型在各种任务上的卓越表现。Sigmoid 高级数据科学家Ankit Mehra等人深入探讨了GPT(Generative Pre-trained Transformers)模型系列的不断演进及其在自然语言处理领域的重要性。从GPT-1到GPT-4,这些模型经历了多次改进和增强,以提供更出色的输出和性能。特别值得一提的是,GPT-3.5模型通过强化学习和人类反馈等技术,注重伦理和可靠性,更好地满足用户需求。而GPT-4模型则引入了多模态处理的能力,进一步拓展了其应用领域。本文为读者提供了全面而详细的GPT模型系列发展历程和改进的介绍。我们特将该内容编译出来和各位客户、合作伙伴朋友分享。如需转载,请联系我们(ID:15937102830)】

在过去的几年中,由于大型语言模型的出现,自然语言处理领域取得了显著的进展。语言模型在机器翻译系统中被用来学习如何将一种语言的字符串映射到另一种语言。在语言模型家族中,基于生成式预训练变换器(GPT)的模型最近引起了最多的关注。最初,语言模型是基于规则的系统,严重依赖于人类的输入才能发挥作用。然而,深度学习技术的演进对这些模型处理的任务的复杂性、规模和准确性产生了积极的影响。
在我们之前的博客中,我们全面解释了GPT-3模型的各个方面,评估了Open AI的GPT-3 API提供的功能,并探讨了该模型的用途和局限性。在本博客中,我们将把重点转向GPT模型及其基本组成部分。我们还将从GPT-1开始,一直到最近推出的GPT-4,并深入探讨每一代中的关键改进,以此逐步使模型变得更加强大。
01
了解GPT模型
GPT(Generative Pre-trained Transformers)是一种基于深度学习的大型语言模型(LLM),采用了基于变换器的仅解码器架构。其目的是处理文本数据并生成类似人类语言的文本输出。
正如名称所示,该模型有三个关键组成部分:
1. 生成式
2. 预训练
3. Transformers
让我们通过这些组件来探索模型:
生成式(Generative):这个特性强调了模型通过理解和回应给定的文本样本来生成文本的能力。在GPT模型之前,文本输出是通过重新排列或从输入中提取单词来生成的。GPT模型的生成能力使其相比现有模型具有优势,能够生成更连贯和类似人类的文本。
该生成能力是在训练过程中使用的建模目标的结果。
GPT模型通过这些组成部分来实现其功能,并在训练过程中使用自回归语言建模来提高生成文本的准确性。模型会根据概率分布预测最可能的下一个单词或短语,以实现生成文本的能力。
预训练(Pre-trained):预训练是指在将机器学习模型用于特定任务之前,模型已经在大规模样本数据集上进行了训练。对于GPT来说,该模型使用无监督学习方法在大量的文本数据语料库上进行训练。这使得模型能够在没有明确指导的情况下学习数据中的模式和关系。
简单来说,通过以无监督方式使用大量数据对模型进行训练,可以帮助模型理解语言的一般特征和结构。一旦学习到了这些特征,模型就可以将这种理解应用于特定的任务,例如问答和摘要生成。
Transformers:这是一种专门设计用于处理长度可变的文本序列的神经网络架构。Transformers 的概念在2017年发表的开创性论文《Attention Is All You Need》后变得引人注目。
GPT使用的是仅解码器架构。Transformers 的主要组成部分是“自注意力机制”,它使模型能够捕捉每个单词与同一句子中其他单词之间的关系。
例如:
1. A dog is sitting on the bank of the River Ganga.
2. I’ll withdraw some money from the bank.
自注意力机制会评估句子中的每个单词与其他单词的关系。在第一个例子中,当“bank”与“River”的上下文一起评估时,模型学习到它指的是河岸。同样,在第二个例子中,将“bank”与“money”进行关联,就可以推断出它指的是金融银行。
02
GPT模型的演变
现在,让我们仔细研究GPT模型的各个版本,重点关注每个后续模型引入的改进和增强。
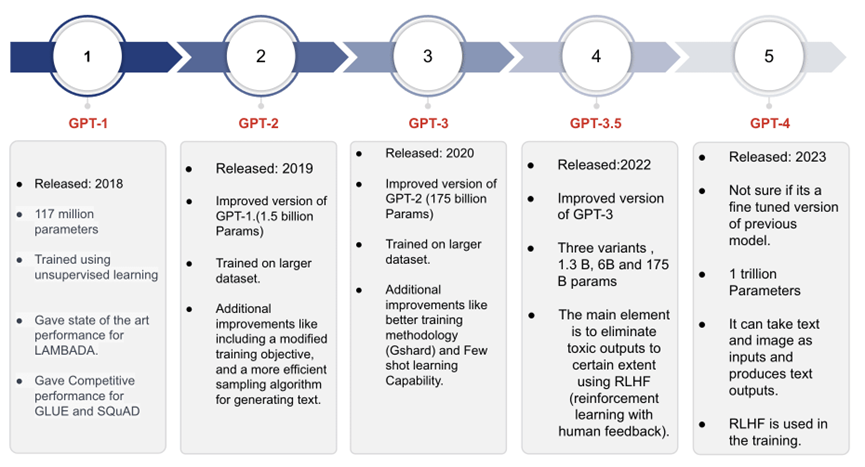 * GPT 模型中的幻灯片 3
* GPT 模型中的幻灯片 3
GPT-1
它是GPT系列的第一个模型,它在约40GB的文本数据上进行了训练。该模型在LAMBADA等建模任务上取得了最先进的结果,并在GLUE和SQuAD等任务上表现出竞争力。该模型的最大上下文长度为512个标记(约380个单词),可以针对每个请求保留相对较短的句子或文档的信息。模型令人印象深刻的文本生成能力和在标准任务上的出色表现为该系列的后续模型的开发提供了动力。
GPT-2
GPT-2是基于GPT-1模型发展而来的,保留了相同的架构特征。然而,与GPT-1相比,GPT-2在更大规模的文本数据语料库上进行了训练。值得注意的是,GPT-2可以容纳双倍的输入大小,使其能够处理更广泛的文本样本。拥有近15亿个参数的GPT-2在语言建模方面展示出了显著的能力和潜力。
以下是GPT-2相对于GPT-1的一些主要改进:
1. 修改目标训练(Modified Objective Training):在预训练阶段使用的一种技术,用于增强语言模型。传统上,模型仅基于前面的单词来预测序列中的下一个单词,可能导致不连贯或不相关的预测。修改目标训练通过加入额外的上下文信息,如词性(名词、动词等)和主谓识别等,解决了这个限制。通过利用这些补充信息,模型生成更连贯和信息丰富的输出。
2. 层归一化(Layer Normalization):这是一种用于改进训练和性能的技术。它将神经网络中每个层的激活进行归一化,而不是整体归一化网络的输入或输出。这种归一化缓解了内部协变量偏移(Internal Covariate Shift)的问题,该问题指的是由于网络参数的改变而导致网络激活分布的变化。
3. GPT-2还采用了比GPT-1更强大的采样算法。关键改进包括:
a. Top-p采样(Top-p sampling):仅考虑累积概率质量超过一定阈值的标记。这避免了从低概率标记中进行采样,从而生成更多样化和连贯的文本。
b. Logits(神经网络在Softmax之前的原始输出)的温度缩放(Temperature scaling):控制生成文本中的随机性水平。较低的温度会产生更保守和可预测的文本,而较高的温度会产生更有创造性和意外性的文本。
c. 无条件采样(随机采样)选项:允许用户探索模型的生成能力,并产生别出心裁的结果。
这些改进使得GPT-2相对于GPT-1在文本生成方面表现更出色。
GPT-3

GPT-3模型是GPT-2模型的进化版本,在多个方面超越了GPT-2。它在更大规模的文本数据语料库上进行了训练,并具有高达1750亿个参数。
除了增加的规模,GPT-3引入了一些显著的改进:
GShard(巨型分片模型并行):允许将模型分割到多个加速器上。这有助于并行训练和推断,尤其适用于具有数百亿个参数的大型语言模型。
零样本学习能力:GPT-3展示了执行其未经明确训练的任务的能力。这意味着它可以通过利用其对语言的一般理解和给定任务来生成对新颖提示的文本响应。
少样本学习能力:GPT-3可以在很少的训练样本下迅速适应新任务和领域。它展示了从少量示例中学习的出色能力。
多语言支持:GPT-3能够熟练生成大约30种语言的文本,包括英语、中文、法语、德语和阿拉伯语。这种广泛的多语言支持使其成为适用于各种应用的高度灵活的语言模型。
改进的采样:GPT-3使用了改进的采样算法,类似于GPT-2,可以调整生成文本的随机性。此外,它引入了“提示”采样的选项,使得可以基于用户指定的提示或上下文进行文本生成。
这些改进使得GPT-3成为一个更加强大和全面的语言模型。
GPT-3.5

与前身相似,GPT-3.5系列模型也是从GPT-3模型发展而来。然而,GPT-3.5模型的显著特点在于其遵循基于人类价值观的特定策略,这是通过一种称为“强化学习与人类反馈(RLHF)”的技术实现的。主要目标是使模型与用户的意图更加接近,减少有害性,并在生成的输出中优先考虑真实性。这种演进意味着有意识地努力增强语言模型的道德和负责任的使用,以提供更安全可靠的用户体验。
相对于GPT-3的改进:
OpenAI利用人类反馈的强化学习对GPT-3进行了微调,使其能够遵循广泛的指令集。RLHF技术涉及使用强化学习原理对模型进行训练,模型根据其生成的输出与人类评估者的质量和一致性而获得奖励或惩罚。通过将这些反馈信息整合到训练过程中,模型能够从错误中学习并提高性能,最终产生更自然、吸引人的文本输出。
GPT-4
GPT-4代表了GPT系列中最新的模型,引入了多模态能力,使其能够处理文本和图像输入,并生成文本输出。它可以处理各种图像格式,包括带有文本的文档、照片、图表、示意图和屏幕截图等。
尽管OpenAI尚未公开披露GPT-4的技术细节,如模型大小、架构、训练方法或模型权重,但一些估计表明它包含近1万亿个参数。GPT-4的基础模型遵循了与之前的GPT模型类似的训练目标,即给定一系列单词,预测下一个单词。训练过程涉及使用大量公开可用的互联网数据和授权数据的语料库。
在OpenAI的内部对抗性真实性评估和TruthfulQA等公共基准测试中,GPT-4展示了比GPT-3.5更优秀的性能。GPT-3.5中使用的RLHF技术也被应用到了GPT-4中。OpenAI积极根据来自ChatGPT和其他来源的反馈来改进GPT-4模型。
03
标准建模任务的GPT模型性能比较
GPT-1、GPT-2 和 GPT-3 在标准 NLP 建模任务 LAMBDA、GLUE和 SQuAD 中的得分。
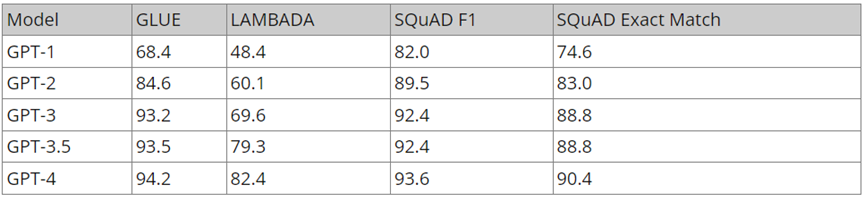 所有数字以百分比表示。 || 数据来源 - BARD
所有数字以百分比表示。 || 数据来源 - BARD
这张表格展示了结果的持续改善,这可以归功于前面提到的增强措施。
GPT-3.5和GPT-4在较新的基准测试和标准考试中进行了测试。
新的GPT模型(3.5和4)在需要推理和领域知识的任务上进行了测试。这些模型已经在许多被认为具有挑战性的考试中进行了测试。其中一项对比GPT-3(ada、babbage、curie、davinci)、GPT-3.5、ChatGPT和GPT-4的考试是MBE考试。从图表中可以看出,得分持续改善,GPT-4甚至超过了平均学生得分。
图1显示了不同GPT模型在MBE考试中获得的百分比分数的比较:
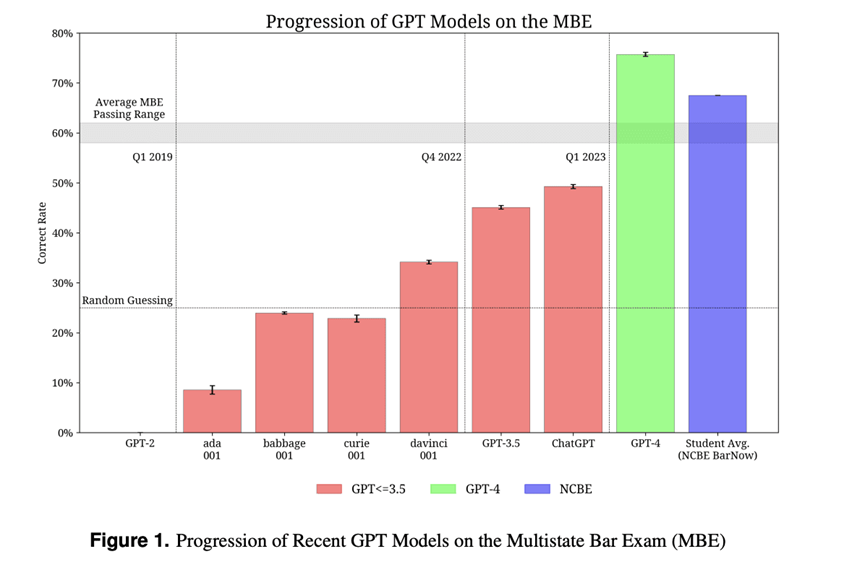 *多州律师考试(MBE)是一套旨在评估申请人的法律知识和技能的挑战性考试,是在美国执业的先决条件。
*多州律师考试(MBE)是一套旨在评估申请人的法律知识和技能的挑战性考试,是在美国执业的先决条件。
下面的图表还突出显示了这些模型的进步,并再次超过了不同法律学科领域的平均学生分数。
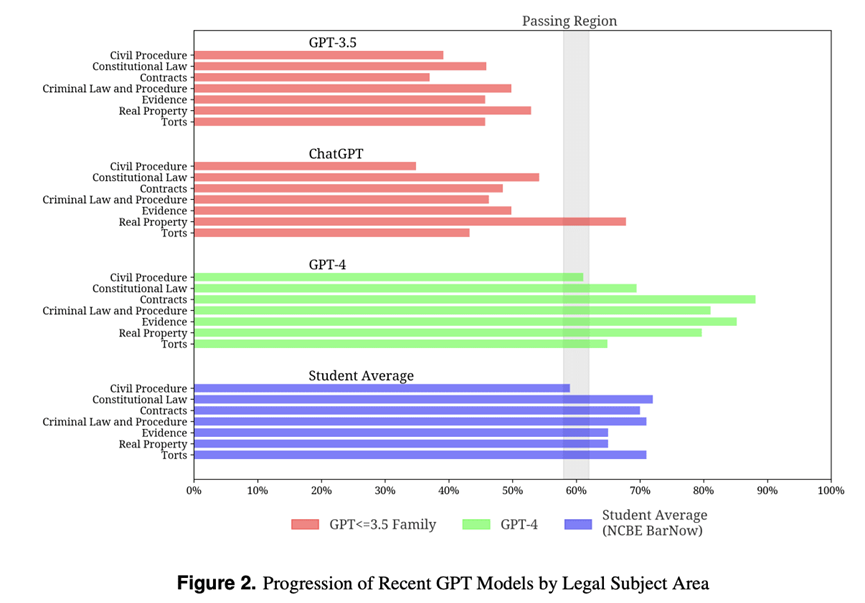 资料来源:数据科学协会
资料来源:数据科学协会
结论
以上的结果验证了这些新模型的强大能力,将模型性能与人类得分进行比较是一个重要的指标。自GPT-1问世以来的短短5年时间里,模型的大小增长了大约8500倍。
在下一篇博客中,我们将更详细地探讨GPT模型的专业版本,包括它们的创建过程、能力和潜在应用。我们将对这些模型进行比较分析,以获得有价值的见解,了解它们的优势和局限性。
指数
 注:ZS:Zero Shot,来源:ChatGPT,BARD
注:ZS:Zero Shot,来源:ChatGPT,BARD
04
结论
随着基于Transformer的大型语言模型(LLM)的兴起,自然语言处理领域正在快速发展。在基于这一架构构建的各种语言模型中,GPT模型在输出和性能方面表现出色。自第一个模型发布以来,OpenAI一直在多个方面不断改进这个模型。
在五年的时间里,模型的大小经历了显著的扩展,从GPT-1到GPT-4大约扩大了8500倍。这一显著进展可以归功于在训练数据规模、数据质量、数据来源、训练技术和参数数量等方面的持续改进。这些因素在使模型在各种任务上表现出色方面起到了关键作用。
一款AI生成头像工具,可以生成各种风格的头像,快来试试吧~
权益福利:
1、AI 行业、生态和政策等前沿资讯解析;
2、最新 AI 技术包括大模型的技术前沿、工程实践和应用落地交流(社群邀请人数已达上限,可先加小编微信:15937102830)

源于硅谷、扎根中国,上海殷泊信息科技有限公司 (MoPaaS魔泊云) 是中国领先的人工智能(AI) 平台和服务提供商,为用户的数字转型、智能升级和融合创新直接赋能。针对中国AI应用和工程市场的需求,基于自主的智能云平台专利技术,MoPaaS 魔泊云在业界率先推出新一代开放的AI平台为加速客户AI技术创新和应用落地提供高效的GPU算力优化和规模化AI模型开发运维 (ModelOps) 能力和服务。MoPaaS魔泊云 AI平台已经服务在教学科研、工业制造、能源交通、互联网、医疗卫生、政府和金融等行业超过300家国内外满意的客户的AI技术研发、人才培养和应用落地工程需求。MoPaaS魔泊云致力打造全方位开放的AI技术和应用生态。同时,MoPaaS魔泊云在浙江嘉兴设立安尚云信信息科技有限公司全资子公司,致力于推动当地的科技产业发展,并积极培养本地专业技术人才,创造更大的社会和经济效益。MoPaaS 被Forrester评为中国企业级云平台市场的卓越表现者(Strong Performer)。
END
▼ 往期精选 ▼
3、深度对话产业专家:“百模大战”愈演愈烈,地球上现有算力不够支撑十亿人使用
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢