
READ: Recurrent Adaptation of Large Transformers
Sid Wang, John Nguyen, Ke Li, Carole-Jean Wu
[Meta AI]
READ: 大型Transformer的RNN自适应
要点:
-
动机:解决大规模Transformer模型在微调过程中的内存和计算资源消耗问题,提出一种轻量级、高效的微调方法,以克服当前参数高效迁移学习(PETL)方法的限制。 -
方法:使用REcurrent ADaptation(READ)方法,通过在主干模型旁边插入一个小型的循环神经网络(RNN)来实现微调。这样,模型不必通过大型主干网络进行反向传播,从而减少了计算资源的消耗。 -
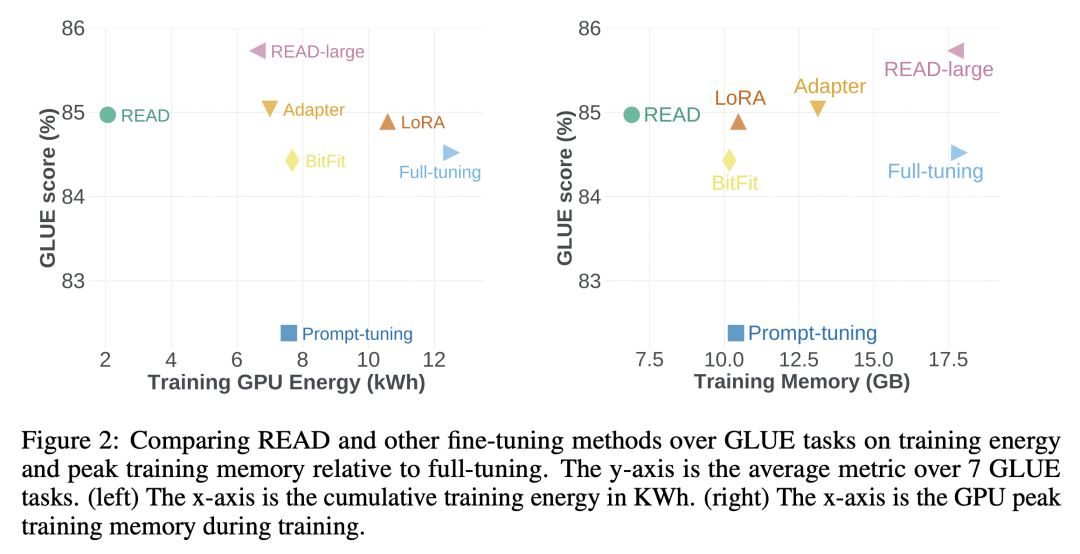
优势:READ方法能显著降低微调过程的内存消耗和GPU能耗,同时保持高质量的模型性能。相较于全量微调方法,READ在训练内存消耗上可降低56%,在GPU能耗上可降低84%。此外,READ的模型大小不随主干模型的增加而增加,使其成为大规模Transformer的高度可扩展的微调解决方案。
通过在主干模型旁边插入小型RNN进行微调,READ方法实现了高效的参数和内存消耗,为大规模Transformer的微调提供了可扩展的解决方案。
https://arxiv.org/abs/2305.15348 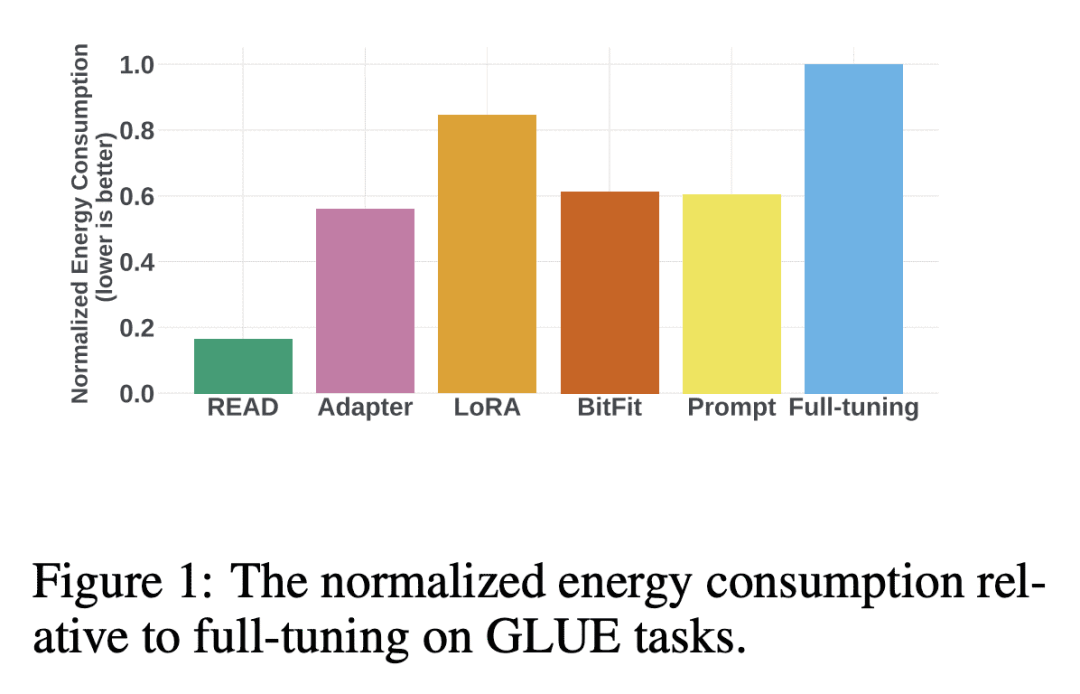
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢