
Generating Images with Multimodal Language Models
提出了一种方法(GILL)来将纯文本语言模型与图像编码器和解码器模型融合,实现了多模态图像生成和处理任意交错图文输入的能力。
Jing Yu Koh, Daniel Fried, Ruslan Salakhutdinov
[CMU]
基于多模态语言模型的图像生成
要点:
-
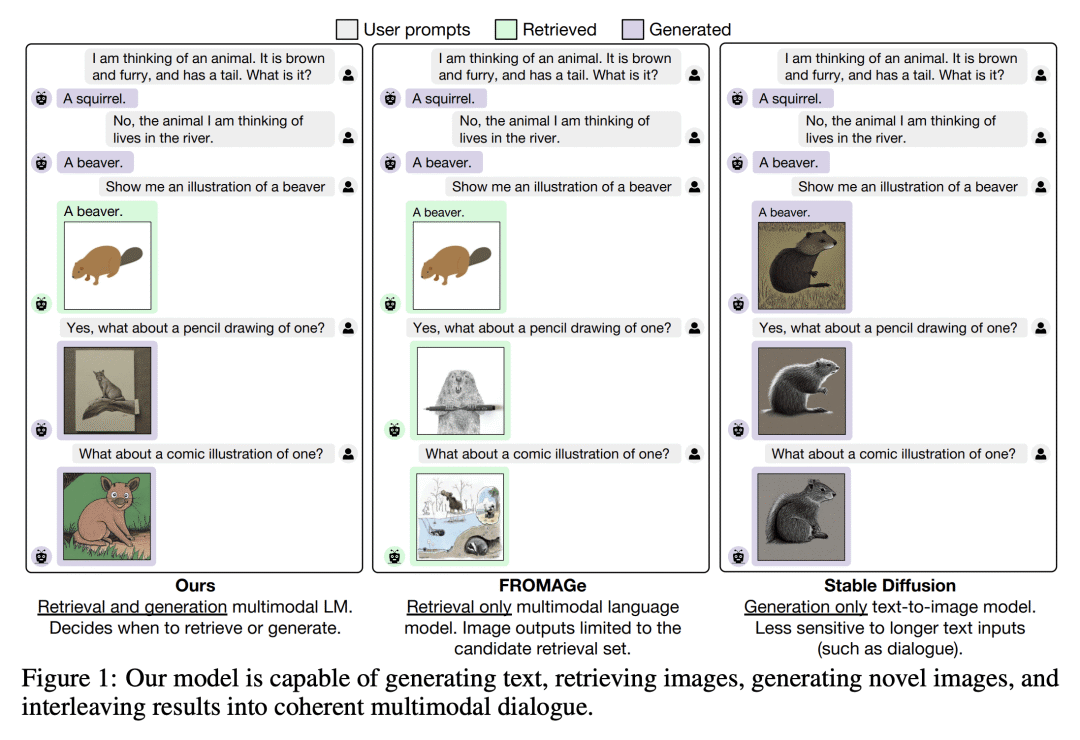
动机:提出一种方法,将冻结的纯文本语言模型(LLM)与预训练的图像编码器和解码器模型进行融合,通过映射它们的嵌入空间,实现多模态图像生成和对话等多种功能。 -
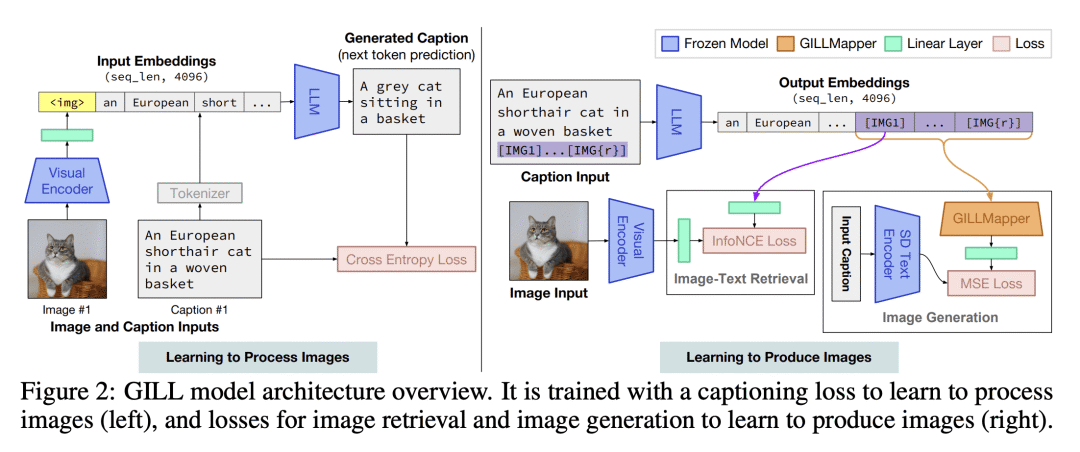
方法:提出一种名为基于大语言模型的图像生成(GILL)的方法,通过有效地映射冻结的纯文本LLM的输出嵌入空间与冻结的生成模型的嵌入空间,实现了处理任意交错的图像和文本输入来生成连贯图像(和文本)输出。为了实现强大的图像生成性能,提出了一种高效的映射网络,将LLM与现有的文本到图像生成模型联系起来。 -
优势:提出一种能处理任意交错图文输入的方法,实现了图像生成、图像检索和生成是对话等多模态功能。在处理长且语言复杂的任务上表现出色,并且在测量语言上下文相关性的多个文本到图像任务中优于基线生成模型。
https://arxiv.org/abs/2305.17216
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢