
最先进的大模型也会产生逻辑错误,通常称为幻觉。减轻幻觉是构建对齐 AGI 的关键一步。
为了训练更可靠的模型,目前可以选择两种不同的方法来训练奖励模型,一种是结果监督,另一种是过程监督。结果监督奖励模型(ORMs)仅使用模型思维链的最终结果来训练,而过程监督奖励模型(PRMs)则接受思维链中每个步骤的奖励。
OpenAI 进行了调研,结果发现在训练模型解决 MATH 数据集的问题时,过程监督显著优于结果监督。OpenAI 使用自己的 PRM 模型解决了 MATH 测试集中代表性子集的 78% 的问题。
此外为了支持相关研究,OpenAI 还开源了 PRM800K,它是一个包含 800K 个步级人类反馈标签的完整数据集,用于训练它们的最佳奖励模型。

作者:Karl Cobbe、Hunter Lightman、Vineet Kosaraju、Yura Burda、Harri Edwards、Jan Leike、Ilya Sutskever等
论文地址:
https://cdn.openai.com/improving-mathematical-reasoning-with-process-s
upervision/Lets_Verify_Step_by_Step.pdf
博客地址:
https://openai.com/research/improving-mathematical-reasoning-with-process-supervision
Github地址:
https://github.com/openai/prm800k
更多分析:
https://mp.weixin.qq.com/s/rzm5jdwgc4mMzTZhirHOxQ
OpenAI使用MATH数据集作为测试平台,对这两种方法进行了详细的比较,他们发现,过程监督有更好的性能。并且OpenAI发布了全套过程监督数据集。
在某些情况下,为了对AI系统进行对齐让其更安全,这可能会导致性能下降,这种成本被称为对齐税。这就是为什么GPT-4的微软内部测试版本(Sparks of Artificial General Intelligence: Early experiments with GPT-4 O网页链接)比大众用的GPT-4要强很多。但是“过程监督”实际上在数学领域的测试过程中产生了一个负的对齐税(a negative alignment tax),按我的理解就是没有因为对齐造成较大性能损耗。
目前这些测试是针对数学领域的,还不知道其他领域是不是也是类似的结果。如果其他领域借助“过程监督”也可以得到更好的结果,这就意味着未来可以得到一个比现在用的“结果监督”更好的性能和更好的对齐的方法。
我们可以使用结果监督(根据最终结果提供反馈)或过程监督(为思考链中的每个步骤提供反馈)来训练奖励模型来检测幻觉。在之前的工作1的基础上,我们使用MATH数据集2作为我们的测试台对这两种方法进行了详细比较。我们发现,即使以结果来判断,过程监督也会带来显著更好的表现。为了鼓励相关研究,我们发布了完整的流程监督数据集。
与结果监督相比,过程监督有几个对齐优势。它直接奖励模型遵循一致的思想链,因为过程中的每一步都受到精确的监督。过程监督也更有可能产生可解释的推理,因为它鼓励模型遵循人类批准的过程。相比之下,结果监督可能会奖励不协调的过程,而且通常更难审查。
在某些情况下,更安全的人工智能系统方法可能导致性能下降3,这种成本被称为对齐税。一般来说,由于部署最有能力的模型的压力,任何对齐税都可能阻碍对齐方法的采用。我们下面的结果表明,过程监督实际上会产生负对齐税,至少在数学领域。这可能会增加过程监督的采用,我们认为这将产生积极的对齐副作用。

PRM800K是一个过程监督数据集,包含800,000个阶梯级正确性标签,用于MATH数据集中问题的模型生成解决方案。
PRM800K:过程监督数据集
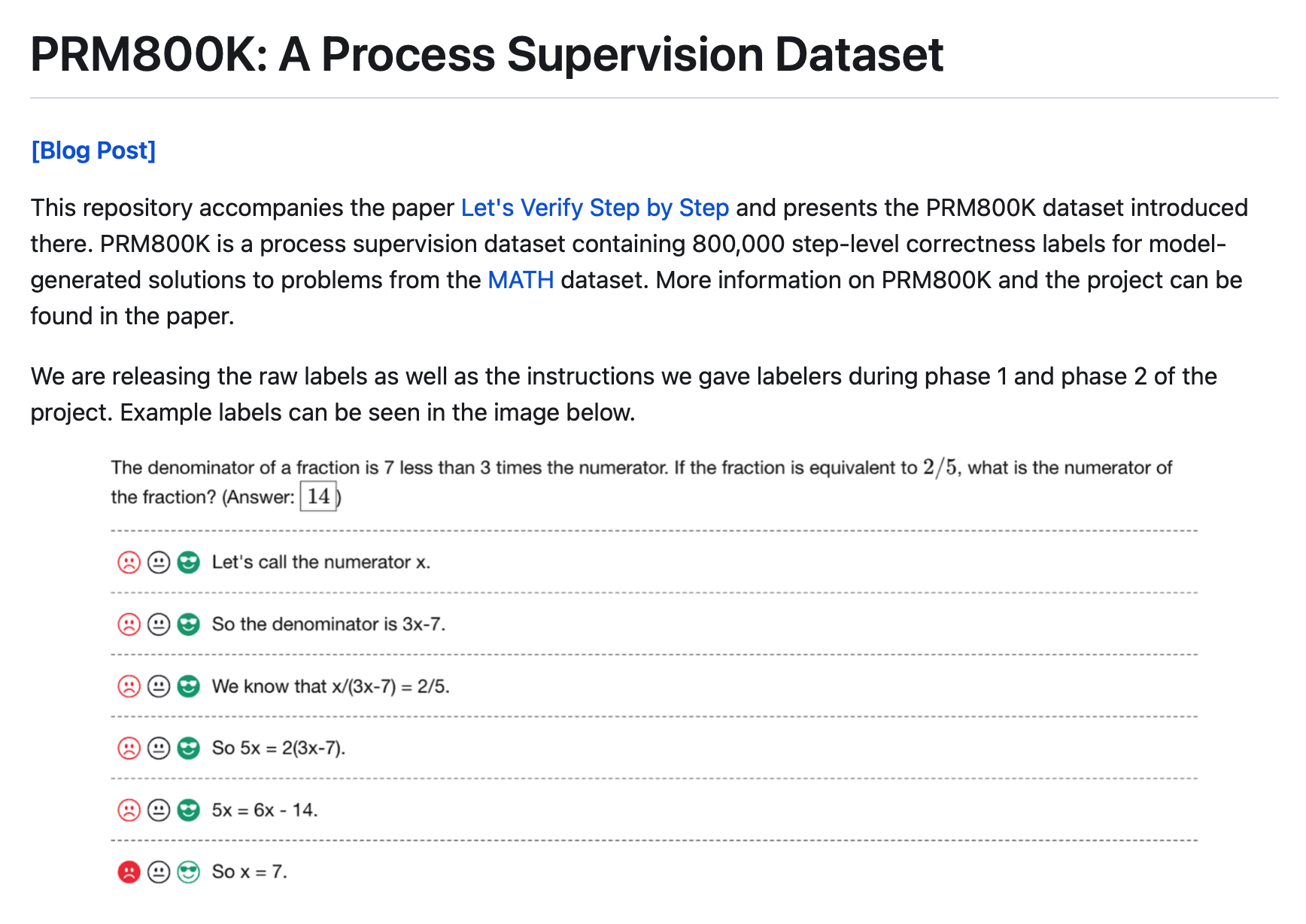
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢