来自剑桥、NAIST 和腾讯 AI Lab 的研究者近期发布了一项名为 PandaGPT 的研究成果,这是一种将大型语言模型与不同模态对齐、绑定以实现跨模态指令跟随能力的技术。PandaGPT 可以完成诸如生成详细的图像描述、根据视频编写故事以及回答关于音频的问题等复杂任务。它可以同时接收多模态输入,并自然地组合它们的语义。

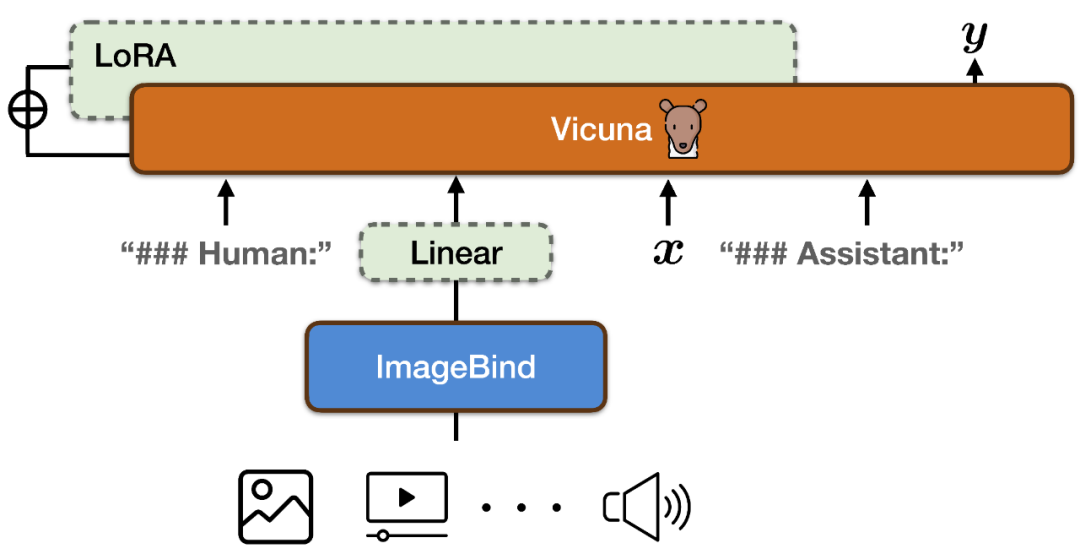
为了实现图像 & 视频、文本、音频、热力图、深度图、IMU 读数六种模态下的指令跟随能力,PandaGPT 将 ImageBind 的多模态编码器与 Vicuna 大型语言模型相结合(如上图所示)。
为了使 ImageBind 的多模态编码器和 Vicuna 的大型语言模型的特征空间对齐,PandaGPT 使用了组合 LLaVa 和 Mini-GPT4 发布的共 160k 基于图像的语言指令跟随数据作为训练数据。每个训练实例包括一张图像和相应一组多轮对话。
为了避免破坏 ImageBind 本身的多模态对齐性质和减少训练成本,PandaGPT 只更新了以下模块:
-
在 ImageBind 的编码结果上新增一个线性投影矩阵,将 ImageBind 生成的表示转换后插入到 Vicuna 的输入序列中;
-
在 Vicuna 的注意力模块上添加了额外的 LoRA 权重。两者参数总数约占 Vicuna 参数的 0.4%。训练函数为传统的语言建模目标。值得注意的是,训练过程中仅对模型输出对应部分进行权重更新,不对用户输入部分进行计算。整个训练过程在 8×A100 (40G) GPUs 上完成训练需要约 7 小时。
值得强调的是,目前的 PandaGPT 版本只使用了对齐的图像 - 文本数据进行训练,但是继承了 ImageBind 编码器的六种模态理解能力(图像 / 视频、文本、音频、深度度、热量图和 IMU)和它们之间的对齐属性,从而具备在所有模态之间跨模态能力。
在实验中,作者展示了 PandaGPT 对不同模态的理解能力,包括基于图像 / 视频的问答,基于图像 / 视频的创意写作,基于视觉和听觉信息的推理等等,下面是一些例子:



与其他多模态语言模型相比,PandaGPT 最突出的特点是它能够理解并将不同模态的信息自然地组合在一起。
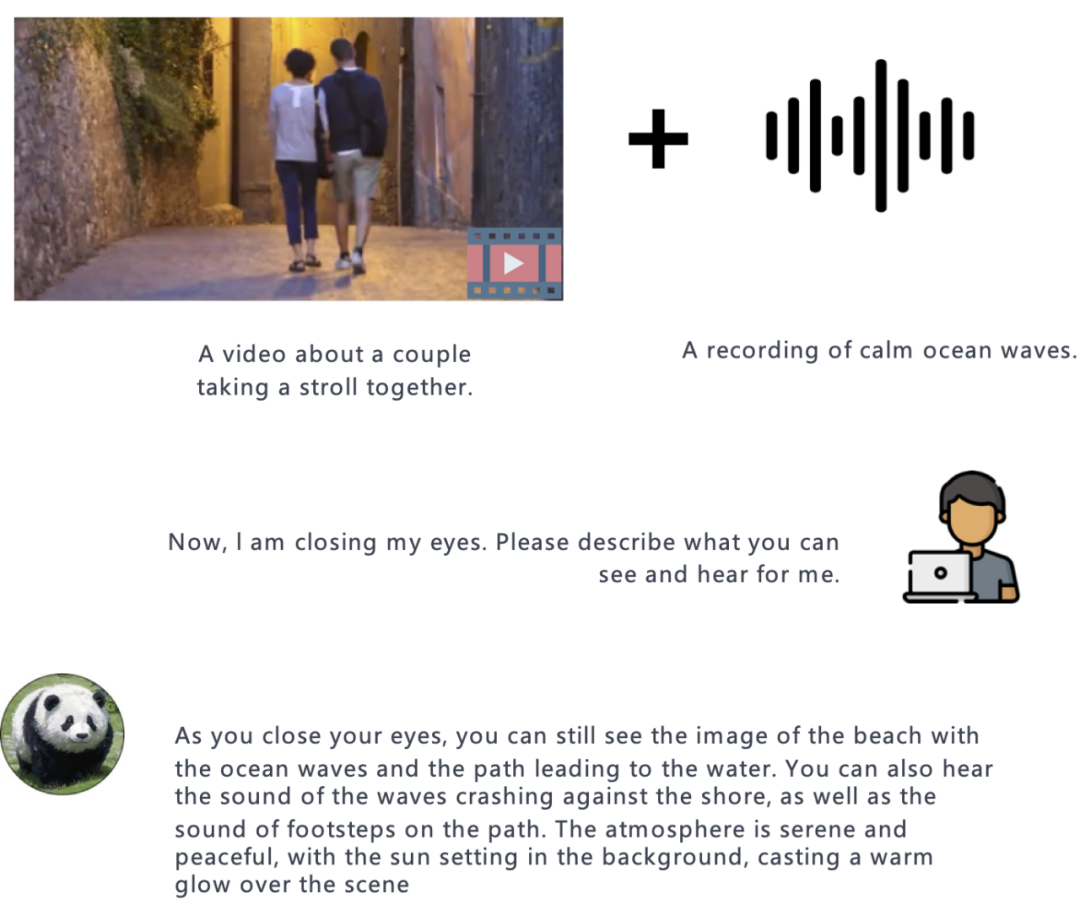
图像 + 音频:
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢