
MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training
Yizhi Li, Ruibin Yuan, Ge Zhang, Yinghao Ma, Xingran Chen, Hanzhi Yin, Chenghua Lin, Anton Ragni, Emmanouil Benetos, Norbert Gyenge, Roger Dannenberg, Ruibo Liu, Wenhu Chen, Gus Xia, Yemin Shi, Wenhao Huang, Yike Guo, Jie Fu
[University of Sheffield & Beijing Academy of Artificial Intelligence & Queen Mary University of London & ...]
MERT: 基于大规模自监督训练的声学音乐理解模型
-
动机:探索在音乐音频领域中应用自监督学习的潜力,提出一种音乐音频理解模型MERT,通过大规模自监督训练提高模型的性能,并解决音乐知识建模中的挑战。 -
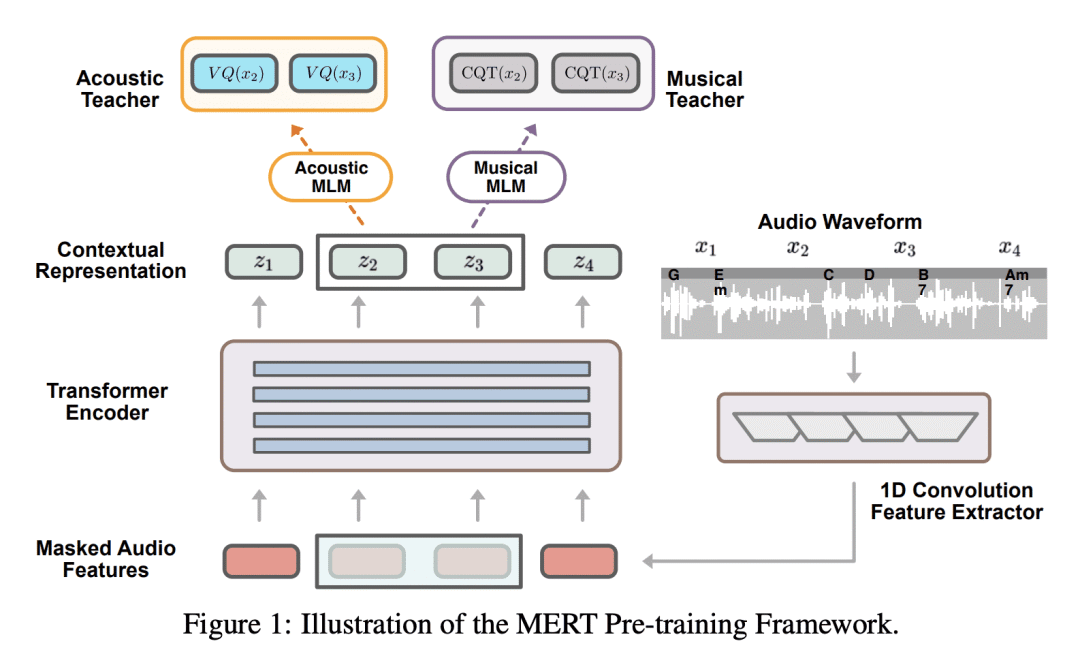
方法:所提出的方法使用教师模型在掩码语言建模的自监督预训练中提供伪标签,将音频特征进行预训练。研究中采用了基于RVQ-VAE的声学教师和基于CQT的音乐教师,指导BERT风格的Transformer编码器进行音乐音频建模,并引入批内噪声混合增强以提高表示的鲁棒性。 优势:MERT模型在14个音乐理解任务上表现出色,取得了最先进的综合得分。论文提出的预训练范式在音乐理解中取得了SOTA性能,并提供了开源的音乐预训练模型,满足行业和研究社区的需求。
提出一种基于自监督学习的音乐音频理解模型MERT,通过大规模预训练和教师模型的引导,提高音乐音频建模的性能,在多个任务上达到最先进水平。
https://arxiv.org/abs/2306.00107
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢