
提出了一种统一的框架,将Transformer网络视为优化稀疏率衰减目标的增量迭代方案,实现了数学解释性和良好实际性能。
White-Box Transformers via Sparse Rate Reduction
Yaodong Yu, Sam Buchanan, Druv Pai, Tianzhe Chu, Ziyang Wu, Shengbang Tong, Benjamin D. Haeffele, Yi Ma
这是马毅在伯克利的团队在理解深度学习深度网络方面的最新工作, 也应该是五年来工作的集成:“White-box Transformers via Sparse Rate Reduction”
GitHub:https://github.com/Ma-Lab-Berkeley/CRATE
希望这项工作能将深度学习的理论和实践真正结合在一起。基于深度学习人工智能,由于经验设计的深度网络一直是不透明的黑盒子,使得掌握这些技术的人能够夸大,炒作,近期甚至到了威胁、绑架社会的地步。这也使得深度学习的理论工作更加重要和迫切。只有大家弄明白AI所用的技术的本质,这些乌七八糟的东西才会消亡。整体来讲,对智能的研究还在非常初始的阶段(而不是某些人在鼓吹的)。保持开源透明的研究是保障进步的必要前提。
在本文中,我们认为表征学习的目标是压缩和转换数据的分布,比如说标记集,使其成为支持在不连贯子空间上的低维高斯分布的混合物。最终表征的质量可以通过一个统一的目标函数来衡量,该函数被称为稀疏率降低。从这个角度来看,流行的深度网络,如变换器,可以自然地被视为实现迭代方案,逐步优化这个目标。
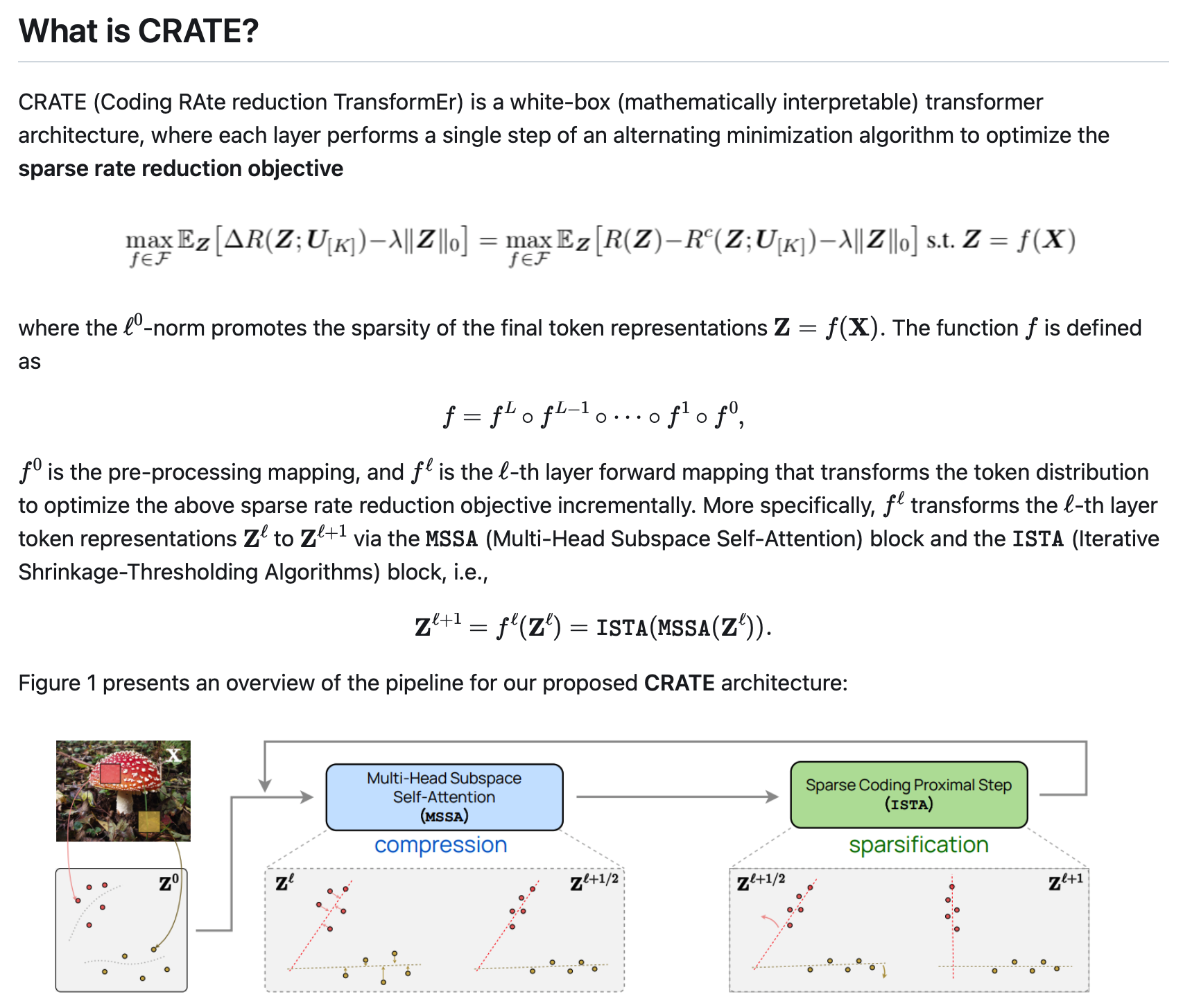
特别是,我们表明,标准的变压器块可以从这个目标的互补部分的交替优化中得到:多头自我注意算子可以被看作是一个梯度下降步骤,通过最小化其有损编码率来压缩标记集,而随后的多层感知器可以被看作是试图稀疏化标记的表示。
这导致了一系列类似白盒变压器的深度网络架构,在数学上是完全可以解释的。尽管它们很简单,但实验表明,这些网络确实学会了优化所设计的目标:它们对ImageNet等大规模真实世界的视觉数据集进行了压缩和稀疏化,并取得了与ViT等彻底设计的转化器非常接近的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢