
最近,来自新加坡国立大学的研究人员提出了一个专供算术的模型山羊Goat,在LLaMA模型基础上微调后,实现了显著优于GPT-4的算术能力。

论文链接:https://arxiv.org/pdf/2305.14201.pdf
通过对合成的算术数据集进行微调,Goat在BIG-bench算术子任务上实现了最先进的性能,
Goat仅通过监督微调就可以在大数加减运算上实现近乎完美的准确率,超越了之前所有的预训练语言模型,如Bloom、OPT、GPT-NeoX等,其中零样本的Goat-7B所达到的精度甚至超过了少样本学习后的PaLM-540
研究人员将Goat的卓越性能归功于LLaMA对数字的一致性分词技术。
为了解决更有挑战性的任务,如大数乘法和除法,研究人员还提出了一种方法,根据算术的可学习性对任务进行分类,然后利用基本的算术原理将不可学习的任务(如多位数乘法和除法)分解为一系列可学习的任务。
通过全面的实验验证后,文中提出的分解步骤可以有效地提升算术性能。
并且Goat-7 B可以在24 GB VRAM GPU上使用LoRA高效训练,其他研究人员可以非常容易地重复该实验,模型、数据集和生成数据集的python脚本即将开源。
LLaMA是一组开源的预训练语言模型,使用公开可用的数据集在数万亿个token上进行训练后得到,并在多个基准测试上实现了最先进的性能。
先前的研究结果表明,分词(tokenization)对LLM的算术能力很重要,不过常用的分词技术无法很好地表示数字,比如位数过多的数字可能会被切分。
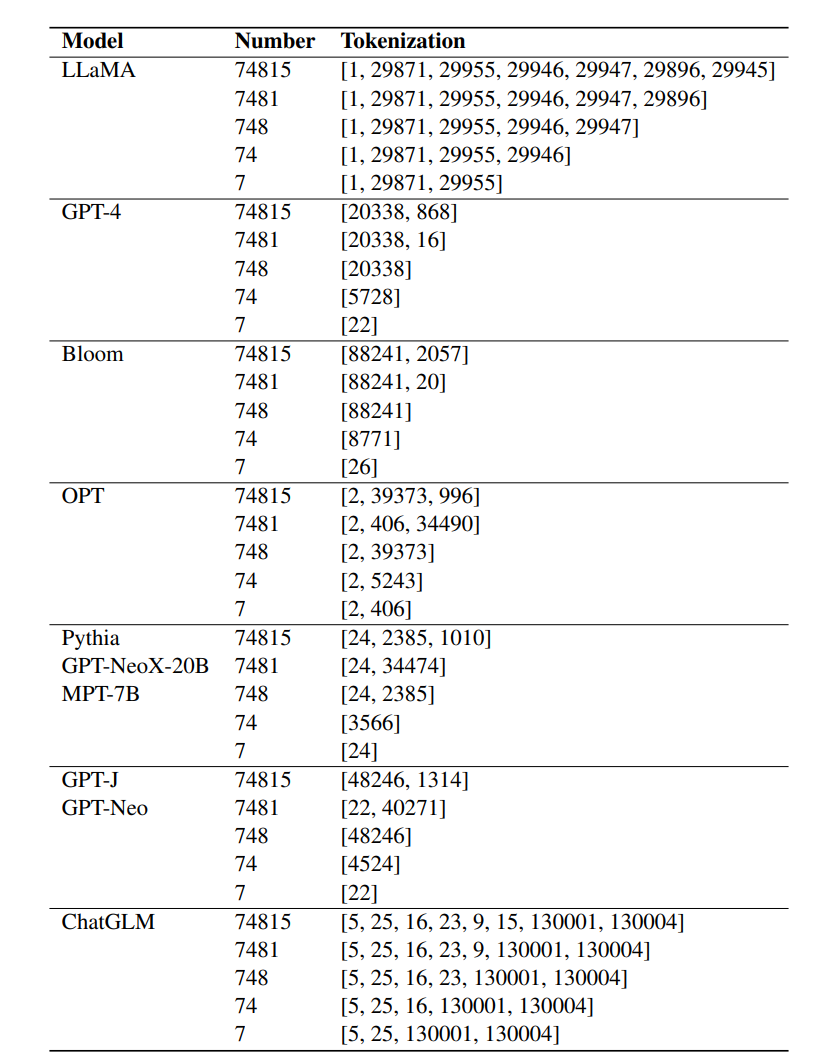
LLaMA选择将数字切分为多个token,确保数字表示的一致性,研究人员认为,实验结果中表现出的非凡算术能力主要归功于LLaMA对数字的一致性分词。
在实验中,其他微调后的语言模型,如Bloom、OPT、GPT-NeoX和Pythia,无法与LLaMA的算术能力相匹配。
最终从GPT-4的解决方案中确定了以下3个常见错误:
1. 对应数字的对齐
2. 重复数字
3. n位数乘以1位数的中间结果错误
参考资料:
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢