
Image Captioners Are Scalable Vision Learners Too
M Tschannen, M Kumar, A Steiner, X Zhai, N Houlsby, L Beyer
[Google DeepMind]
图像描述器也是可扩展的视觉学习器
要点:
-
动机:对比研究图像文本对的对比式预训练和图像描述的生成式预训练策略,以探究它们在视觉骨干网络的预训练中的效果差异。 -
方法:通过公平比较对比式预训练和生成式预训练的效果,匹配训练数据、计算资源和模型规模,使用标准的编码器-解码器Transformer模型进行实验。 -
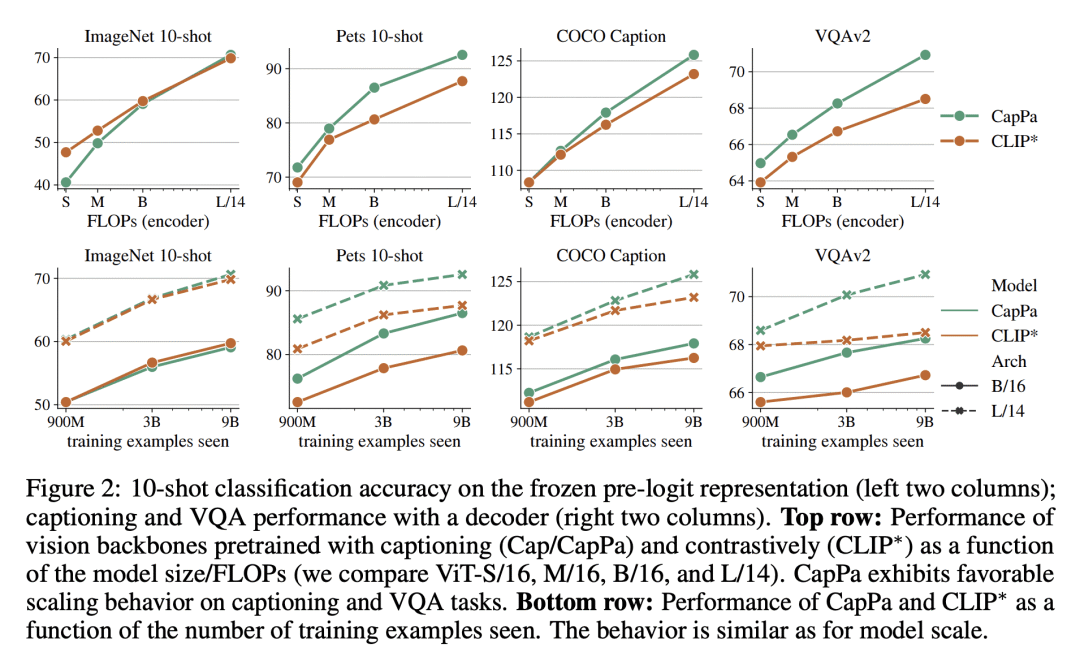
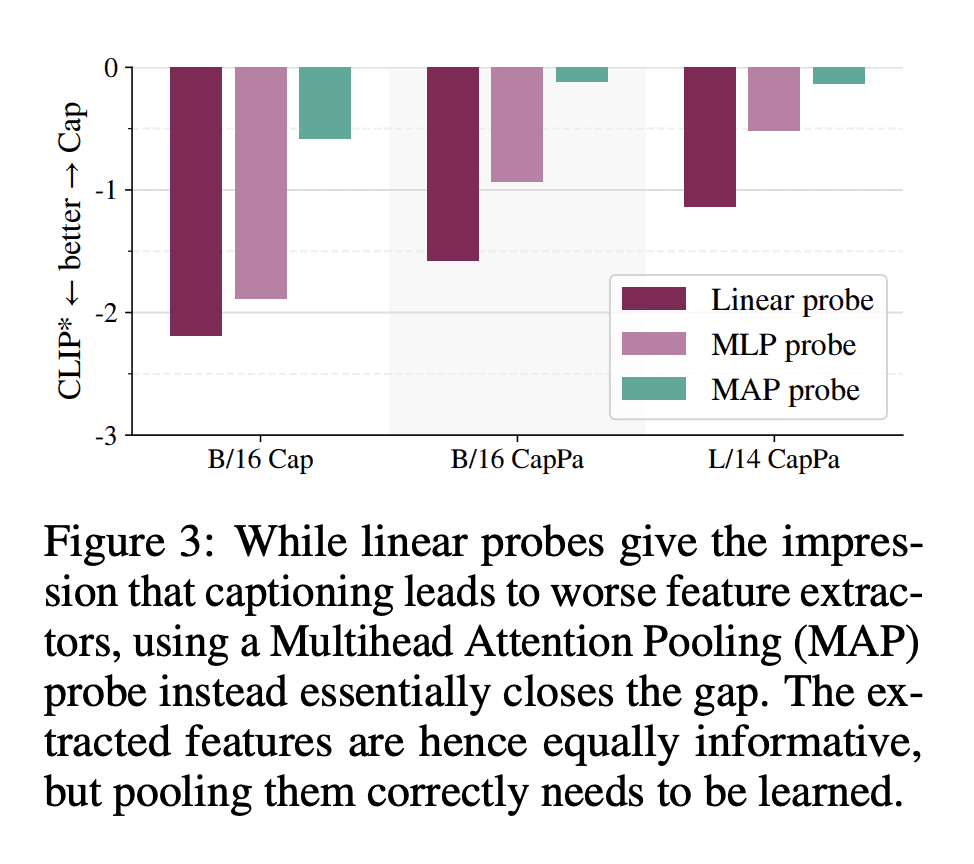
优势:发现纯图像描述作为预训练策略比之前认为的更加强大,在分类任务上产生与对比预训练模型相竞争的视觉编码器,并在视觉-语言任务上超越对比性预训练模型。
一句话总结:
对比了对比式预训练和生成式预训练策略在视觉骨干网络中的效果,发现纯图像描述预训练具有竞争力,并在视觉与语言任务上表现优异。
Contrastive pretraining on image-text pairs from the web is one of the most popular large-scale pretraining strategies for vision backbones, especially in the context of large multimodal models. At the same time, image captioning on this type of data is commonly considered an inferior pretraining strategy. In this paper, we perform a fair comparison of these two pretraining strategies, carefully matching training data, compute, and model capacity. Using a standard encoder-decoder transformer, we find that captioning alone is surprisingly effective: on classification tasks, captioning produces vision encoders competitive with contrastively pretrained encoders, while surpassing them on vision & language tasks. We further analyze the effect of the model architecture and scale, as well as the pretraining data on the representation quality, and find that captioning exhibits the same or better scaling behavior along these axes. Overall our results show that plain image captioning is a more powerful pretraining strategy than was previously believed.
https://arxiv.org/abs/2306.07915 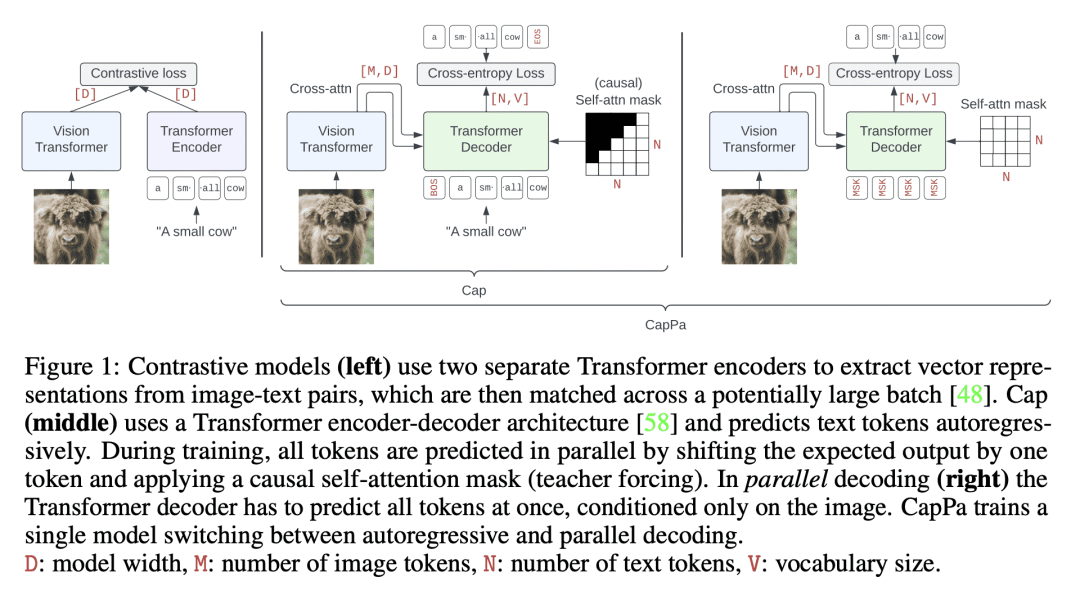
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢