
今年的北京智源AI大会众星云集,精彩程度堪称“AI春晚”。很多教科书和媒体头条中的国际AI大咖都通过远程或现场的方式参会,众多来自国内外知名高校和研究院的AI学者、知名科技企业的AI从业者也分享了非常精彩的观点。
这场为期两天的AI知识盛宴,总共有20场论坛、100场主题报告,内容精彩纷呈,让每位参会者的神经网络得到了充足的训练。由于文章篇幅所限,我选取了几位国内外AI大咖—2018年图灵奖得主杨立昆和Geoff Hinton、OpenAI创始人Sam Altman、“暂停AI大模型研究”发起人Max Tegmark,以及智源研究院首席研究员刘嘉、智源研究院院长黄铁军的演讲。演讲的核心内容总结如下,如需获取全文纪要,可在文章结尾处查看原文链接。

图:群星璀璨的智源AI大会2023
我的参会思考:
-
国内外主流学者普遍认为,AGI的诞生只是时间问题,关于AI的监管已经迫在眉睫
-
国外的AI领军者—Sam Altman、杨立昆、Max Tegmark、Stuart Russell、Geoff Hinton普遍认为AI进展速度极快,AGI的诞生只是时间问题。国内的AI教授学者们也普遍认为AGI将在2030年左右到来,AI的发展速度确实势不可挡
-
目前AI监管遇到的难题:一是AI科学家对AI的风险尚未达成共识,如每位AI科学家各执一词,政策制定者就可以从随心从其中选择一个符合自身利益的观点作为指导;二是“AI模型的可解释性”挑战,需要创新的技术来构建透明和可理解的AI系统,防止不安全的AI系统得到部署
-
超强AI如果无法得到有效控制,为世界带来的危害可能超过核武器,可能会给人类带来灭绝风险。超强AI的监管,既需要需要全球AI学界和业界达成共识,也需要全球范围内的政府间合作
-
未来,AI领域需要类似航空、核能、新药上市等领域的审核措施,形成严格的安全标准
-
Transformer不会是超强AI的模型架构,大语言模型(LLM)不理解世界运转逻辑,更强的AI模型应具备对现实世界的无监督学习能力
-
基于Transformer架构的GPT模型本质是自回归模型,不具备“系统二”的思考规划能力,不理解真实世界,没有真正在“回答”问题,只是在模仿人类的语言行为
-
目前基于软硬件分离的架构耗能巨大,模型预训练成本太高,需要有创新模型架构来解决耗能的问题
-
AI目前实现了很多大脑皮层的功能(理性),但仍没做到模仿从边缘系统到脑干的部分(感性)
-
AI大模型“读过万卷书,还没行万里路”,下一步突破方向是具身智能(Embodied AI),让其参与物理世界的互动来认知世界的表征、与人社交来建立感性和同理心
-
OpenAI在AI大模型上的领先优势很明显,领先优势可能会越来越大
-
GPT-4正用于:1)辅助研发GPT-5,未来GPT-6的研发可能会更多交给GPT-5来完成;2)解释前代GPT-2,解决AI大模型的可解释性难题。OpenAI无论是在新一代模型的研发上,还是在大模型可解释性研究上,都处于全球领先水平
-
GPT-4诞生于22年8月,OpenAI经过8个月的时间来确保对齐后才发布,OpenAI在大模型对齐工作的经验上遥遥领先同行
-
国内大模型追赶GPT-3.5的速度会很快:
-
从智源的研讨会上可以观察到:AI大模型的预训练方法正在快速普及。智源发布了开源大模型,智源专家也分享了如何做大模型的预训练
-
从企业界的AI专家分享来看,国内AI从业者目前对AI大模型的认知和预训练的know-how相较年初已经有了明显提升,预计国内在未来0.5-1.5年内会陆续诞生几个达到或超过GPT-3.5水平的大模型
以下是国内外AI大咖们演讲笔记,enjoy!
Day 1
杨立昆(2018年图灵奖得主、Meta首席AI科学家、纽约大学教授)
演讲主题“Towards Machines that can Learn, Reason, and Plan”

目前的GPT模型(自回归模型)有难以修正的错误:
-
目前的机器学习,能力与人类和动物相比还是很差的,具体表现是缺乏推理和规划能力,只能“快速地反应”,会犯愚蠢的错误;而人类和动物可以非常快速地学习新任务、理解世界是如何运转的、可以推理和规划,最重要的是有关于世界的常识
-
自监督学习是捕捉输入中的依赖关系。在自监督学习的训练方式下,系统不断预测下一个token(可以代表文字、图片块、语音片段),然后将token移入输入中,再预测下一个token,再将其移入输入中,不断重复该过程,这就是自回归模型
-
目前的主流模型(OpenAI的GPT-4, Meta的LLaMA, 谷歌的LaMDA/Bard. Deepmind的Chinchilla等) 都是“自回归模型”(Auto-regressive model),它们没有关于基础现实的知识,既缺乏常识也没法规划答案
-
自回归大模型适合作为写作辅助工具(草稿生成、风格优化等)、帮程序员编写代码,但它们会犯事实错误,会一本正经地胡说八道(hallucinations),不擅长摄入最新信息、推理规划、使用工具等。我们经常被它们的流畅性迷惑,但它们并不知道真实世界是怎么运转的
-
目前的AI研究重点,是让大模型能够调用搜索引擎、计算器、数据库查询等工具,即“扩展语言模型”,扩展语言模型虽然擅长检索记忆,但它们没有任何关于世界运作方式的理解,这也是自回归模型存在的主要缺陷
-
自回归模型是注定要完蛋的(doomed),它们不可控,也没办法做到符合事实、输出结果无害。假设任何生成的token产生错误的概率为e,则长度为n的答案错误概率就是 P(correct)=(1-e)^n,可见错误答案的概率是随长度指数增长的,如果没有对模型架构的大幅改动,此错误是无法修正的
-
未来几年AI面临的三大挑战:1)学习世界的表征和预测模型(采用自监督方式学习);2)学习推理,类似丹尼尔·卡尼曼的“系统二”;3)如何通过将复杂任务分解成简单任务,以分层的方式来规划复杂的行动序列
“世界模型”才是通往AGI之路:
-
针对自回归模型的上述问题,杨立昆的答案是“世界模型“(world model),即”关于世界如何运转的内部模型“。详见一年前发布的论文“A Path Towards Autonomous Machine Intelligence”
-
通过世界模型,AI可以真正理解这个世界、能预测和规划未来。通过成本核算模块,结合一个简单的需求(按照最节约行动成本的逻辑去规划未来),它就可以杜绝一切潜在的毒害和不可靠性
-
这个未来如何实现?世界模型如何学习?杨立昆只给了一些规划性的想法,比如还是采用自监督模型去训练,比如一定要建立多层级的思维模式。他介绍了联合嵌入预测架构(JEPA),系统性地介绍了这一实现推理和规划的关键
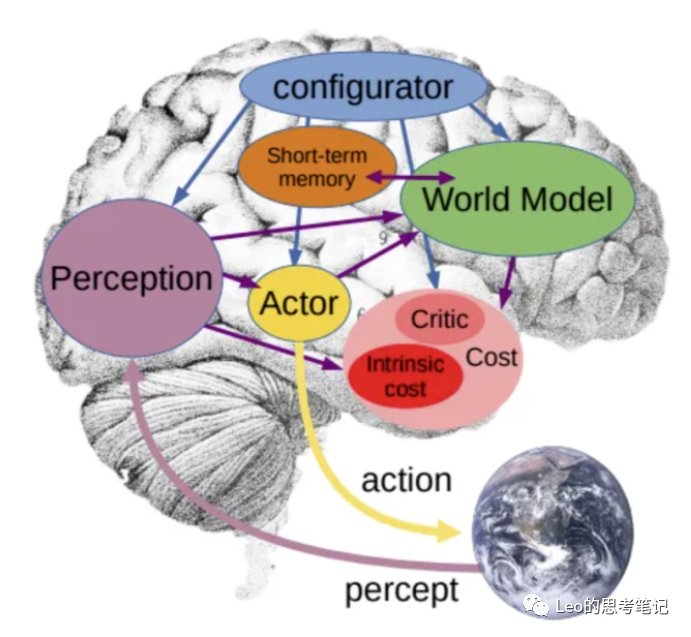
关于AI的风险,杨立昆是乐观派:
-
杨立昆即将参加一个辩论,主题是:AI是否会威胁人类生存,正方对手是Max Tegmark和Yoshua Bengio。杨立昆认为目前的AI风险可以被工程设计减轻或抑制
-
由于超级AI尚未问世,杨立昆表示尚不能预测超级AI在未来能造成多大影响,他举例—如果你去问一个1930年的航空工程师,“我们如何确保涡轮喷气发动机的安全可靠?”那他肯定答不上来,因为1930年还没发明涡轮喷气发动机
推荐阅读:《科学之路:人,机器与未来》 作者:杨立昆
Max Tegmark(MIT教授,未来生命研究所创始人)
演讲主题”Keeping AI under control”

-
作为“暂停AI研究倡议”的发起人,Max 实际上对AI的未来充满希望,最近还发表过论文,表明AI可以帮助我们更快地实现联合国的可持续发展目标,但前提是我们能够控制住AI
-
虽然对AI的担忧由来已久,但对AI的监管变得更加紧迫却是最近发生的事情,因为AI大模型已经基本通过图灵测试,掌握了语言能力,这是过去AI研究员认为将非常接近人类所能做到的一切的标志
-
Max表示,在ChatGPT诞生之后,已经展示了现有AI的强大,按此速度发展,如果有人很好的掌握了AI,他就拥有了oracle(神谕),可以赚很多钱,雇佣所有不掌握AI能力的人,加剧社会不平等
-
与杨立昆的观点一致,Max认为未来AGI和超级AI的模型架构肯定不是Transformer,我们现在正在开发的一些东西可能顶多是其他系统中的组件;与杨立昆观点不符的是,Max认为Tranformer模型已经体现出了“世界模型”的能力—有研究者给了一个Transformer模型 ”奥赛罗棋“的下棋记录,但并未告知任何游戏规则,也未告知这个游戏是在棋盘上玩的,神奇的是研究人员发现这个Transformer内部很快就建立了一个世界模型(一个8x8的二维棋盘)
-
要实现对AI的控制,确保AI能帮助人类构建美好未来、为人类服务,需要解决两个主要问题:1)对齐,即如何确保一个单独的AI能按照主人的意愿行事;2)如何使全球各组织、公司和个人保持一致,确保他们的动机是将AI用于善事而不是坏事
-
Max详细讨论了“AI的机械可解释性”(这是Max最近的学术研究方向),即让AI模型的决策过程变得透明化和可解释化,以便让人类可以理解
-
Max认为目前中国在AI监管方面做得最多,非常认可中国的重要作用:1)中国是一个世界领先的科技大国,不仅可以引领使AI性能更强的研究,也能引领提高其鲁棒性和可信性的研究;2)中国是全球生存时间最长的文明之一,有长期规划的传统,言下之意是中国拥有如何维系文明生存的智慧
-
Max分享了一个很有意思的观点:在全球范围内,建立对AI带来的生存风险的共识、开启对AI风险的监管,有利于缓和紧张的中美关系

图:笔者有幸与Max Tegmark教授会后共进午餐
推荐阅读:《生命3.0》 作者:Max Tegmark
Day 2
Sam Altman (OpenAI CEO)分享

图:Sam Altman接受张宏江博士的访谈
演讲环节:
-
AI技术进步是一条指数型曲线…想像未来10年的世界,通用人工智能(AGI)几乎在每个领域的专业技能都超越人类,这些AI系统的生产力最终可以超过我们最大公司所能产出的集体生产力
-
即使大国之间存在分歧,也能在AI安全这样最重要的事情上找到合作方法。在国际合作中,两个领域最重要:1)建立国际规范和标准,并注意过程中的包容性;2)需要国际合作,以可核查的方式建立对安全开发日益强大的AI系统的国际间信任
-
Sam呼吁推动建立提高AGI安全技术进步方面的透明度和知识共享机制,当研究人员发现新出现的安全问题时,为了人类最大利益应该分享他们的发现
-
OpenAI曾花了8个月时间来研究如何前置预判AI的风险并制定相应的对策,Sam认为GPT-4的对齐程度超过了当前所有的代码水平
-
对于越来越先进的AI系统,对齐(alignment)是很有挑战的,OpenAI的最终目标是训练AI系统来帮助进行对齐研究,目前正在进行的研究包括:1)可扩展监督,训练AI系统来协助人类监督其他AI系统;2)可解释性,即更好地了解这些模型内部发生了什么—OpenAI最近在使用GPT-4来解释GPT-2中的神经元、使用模型内核(model internals)来检测一个模型何时在说谎
-
AGI离我们还有多远?—Sam认为,在未来10年内,我们可能会拥有超强的AI系统,我们应该为一个拥有超强AI系统的世界做好准备
-
是否打算重新开源最新GPT模型?—Sam反馈,随着时间的推移,OpenAI可以期望开源的模型会更多,但没有具体的模型和时间表
-
Sam积极评价了中国在AI安全对齐上的重要作用,因为中国拥有全球顶尖的AI人才,看到了中美和世界各地研究人员合作实现AI目标的巨大潜力
刘嘉(智源研究院首席科学家、清华大学基础科学讲席教授)
论坛主题:基于认知神经科学的大模型

-
AI大模型在模仿大脑皮层,即”理性”,包括自由意志、复杂判断、符号思维。没有模仿的从边缘系统到脑干的部分,即”感性”,包括情绪、动机、简单判断,感知世界,反射运动,呼吸。此外,ChatGPT读了万卷书,但无法行万里路,被限制在机房
-
解决ChatGPT的逻辑、情感问题,需要赋予其身体(具身性),让其参与社交,与人真正交互,并产生同理心
-
现有的大模型参数无法根据反馈来调整,即使RLHF也只是在预训练阶段调整参数,一旦大模型发布后,参数是不会调整的;相比而言,人类是可以根据实际情况的反馈调整神经网络的
-
22年来参会,认为AI要超越人类,就一定要从仿生学角度出发,模仿人类大脑结构和神经网络,因为人类是唯一实现“AGI”的智能体;但今年来参会时,想法已经改变了,因为OpenAI已经把超强AI的路线做出来了。对此,刘嘉既感到难过(“因为过去做的很多事情都是错的”),也感到兴奋,因为有了GPT之后,有机会发展出”Theorem of Intelligence”
-
Geoff Hinton本科是学心理学的,硕士学的人工智能,一直都是用大脑来启发做AI研究;刘教授也是如此,但今年以来开始反思,自己其实没抓到大脑的第一性原理,过去看的是大脑表征的稀疏性、神经形态计算等。Hinton真正认清了什么是人类大脑的第一性原理—”大“(神经元数量超多),他过去几十年都在推动从工程角度出发,推动AI模型变得更大。在Hinton的影响下,Ilya Sutskever(OpenAI首席科学家)坚定走大模型路线,把参数做到千亿级,结果大力出奇迹,做出了开创性的突破
-
Hinton独创了用反向传播算法(BP)训练模型,花了20年,用非线性解决了反向传播的层级有限的问题;Hinton一辈子就干了一件事情—如何把AI模型的神经网络变大
-
如果未来的AI智能要给最有影响力的人类科学家评选,当选者一定是Geoff Hinton,而不是牛顿、爱因斯坦,Hinton真正推动了AGI的诞生
-
AI的下一步,就是具身智能(embodied AI),让AI与物理世界进行交互,获得更多反馈
推荐收听:小宇宙App “人文清华播客:刘嘉 AI全面超越人类大概率是确定的事”
黄铁军(智源研究院院长、北大信科学院教授)
开幕式&闭幕式演讲

-
要实现AGI,有三条技术路线:1)“大数据+自监督学习+大算力”形成的信息类模型(大模型);OpenAI做GPT模型就遵循此路线;2)具身智能,基于虚拟世界或真实世界、通过强化学习训练出来的具身模型;Google DeepMind的DQN(Deep Q-network)属于此路线;3)脑智能,直接“抄自然进化的作业”,复制出数字版本的智能体;智源希望从“第一性原理”出发,从原子到有机分子、神经系统、到身体,构建一个完整的智能系统AGI,这可能需要20年时间
-
在上述三条路线中,大模型的进展最快,主要是语言数据(论文、图书、代码等)资源非常丰富且高质量,从海量数据中发现内在蕴含的规律正是大模型的优势
-
人脑可以看成脉冲神经网络,与今天的大模型有本质区别,想要AI产生类似人脑的能力,光靠大模型一个方向是远远不够的,另外两条路线也值得探索
-
大模型的三个特点:1)规模大,神经网络参数达到百亿规模以上;2)涌现性,产生预料之外的新能力;3)通用性,不限于单类问题或专门领域,能够解决各类问题
-
人工智能三定律:(引用《AI的25种可能》)
-
第一定律:任何有效的控制系统都必须与它所控制的系统一样复杂(阿什比定律(Ashby’s law))
-
第二定律:生物体最简单的完整模型就是生物体本身。试图将系统的行为简化为任何形式的描述都会使事情变得更复杂,而不是更简单(冯·诺依曼提出)
-
第三定律:任何简单到可以理解的系统都不会复杂到可以智能地运行,而任何复杂到可以智能运行的系统都会复杂到无法理解(第三定律存在一个漏洞—完全有可能在不理解智能的情况下将它构建出来)
Geoff Hinton (2018年图灵奖得主,深度学习之父)
分享题目”Two Paths to Intelligence”
-
人工神经网络很快会比真实神经网络更智能吗?—Hinton认为可能很快就会发生
-
人类能控制住超强智能AI吗?—Hinton认为很有可能做不到,但他也没什么好办法阻止此事的发生

Hinton在演讲中,主要分享了"凡人计算"的概念:
-
在传统计算中,计算机被设计为精确地遵循指令。我们可以在不同的物理硬件上运行完全相同的程序和神经网络,这意味着程序或神经网络的权重中的知识是永生的(immortal),不依赖于任何特定的硬件
-
但要实现这种永生,需要付出高昂的代价—需要高功率运行晶体管,以便它们以数字方式运行,我们无法利用硬件的所有丰富的模拟和高度可变的特性
-
现在我们可以让计算机从例子中学习,因此可以考虑放弃计算机科学最基本的原则—软硬件可以分离,从而得到凡人计算(mortal computaiton)
-
凡人计算的巨大优点:以更少的能量运行大语言模型之类的AI,特别是使用更少的能量来训练AI大模型。通过放弃硬件(身体)和软件(灵魂)的分离,我们可以节省大量能源,可以使用非常低功耗的模拟计算—这正是大脑正在做的事情
-
我们还可以获得更便宜的硬件,硬件可以在3-D中便宜地生长,而不用在2-D中非常精确地制造。这需要大量的新的纳米技术,或可能需要对生物神经元进行基因改造
-
目前凡人计算还面临两大问题:1)学习过程必须利用它所运行的硬件的特定模拟属性,而无需确切知道这些属性是什么,这意味着无法使用反向传播算法(backpropagation)来获得梯度,因为反向传播算法需是前向传播的精确模型;2)凡人计算的生命是有限的,当特定的硬件死掉时,它学习的知识会随之消亡,因为知识和硬件错综复杂地绑定在一起;解决方案是在硬件失效前,将知识蒸馏出来给学生
-
目前的大语言模型的每个副本、每个代理,都以非常低效的方式从文档中获取知识,实际上是一种非常低效的蒸馏形式。如果未来,一个大型神经网络可以直接从现实世界学习(而不仅是通过模仿人类语言来获得人类知识),它们将比人类学到更多,而且能学得非常快
-
一个超级智能将如何获得控制权?如果你想让超级智能更有效率,你需要让它创建子目标。一个很明显的子目标就是获得更多权力,因为更多的权力有助于其实现子目标。超级智能会发现很容易通过操纵人来获得更多的权力,因为超级智能将学会如何欺骗他人
-
我不知道在智力差距很大时,更聪明的东西能被不聪明的东西控制的例子。举例而言,假设青蛙发明了人,你认为现在谁说了算,青蛙还是人?
-
我老了,看不出如何防止这种情况发生,希望更多年轻才俊能研究清楚我们如何才能拥有这些超级智能
推荐阅读:《深度学习革命》 作者:Cade Metz
参考文献:
本文作者:
Leo:关注科技的投资人,相信AI是通往万物的摩尔定律
微信:wangkun90886
即刻:Leo王昆
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢