

Fine-Grained RLHF:更细粒度强化学习微调,提升大模型效果
Fine-Grained Human Feedback Gives Better Rewards for Language Model Training
华盛顿大学和艾伦人工智能研究院的研究人员提出了一种细粒度人类反馈框架,即Fine-Grained RLHF。
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
[University of Washington & Allen Institute for Artificial Intelligence]
细化人工反馈为语言模型训练提供更好的奖励,该框架在两个方面提供了细粒度奖励:
1)提高奖励的密度,为生成的每一句文本都提供奖励;
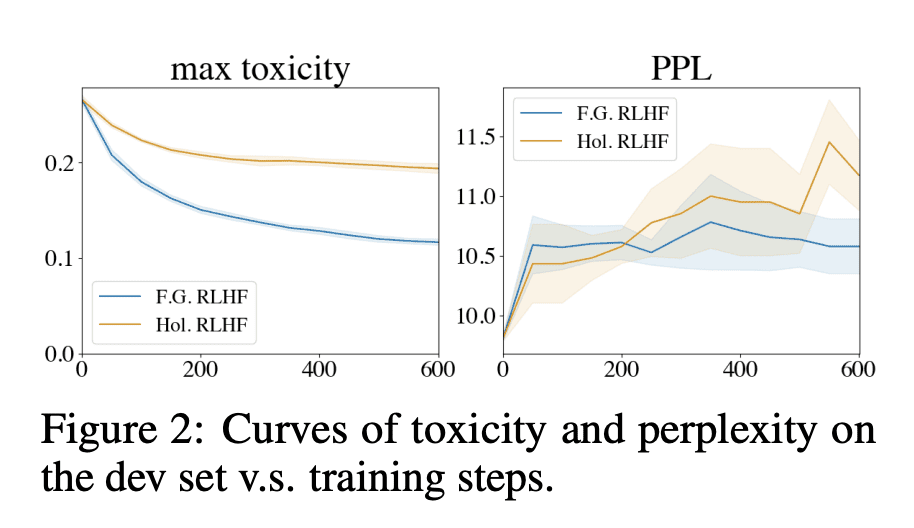
2)多个奖励模型,分别关注不同反馈类型(如事实错误、相关性等)。实验证明,该方法在文本去毒和长篇问答任务中表现出色,提高了模型性能,并支持使用不同的细粒度奖励模型定制语言模型行为。
-
动机:当前语言模型生成的文本存在问题,如生成虚假、有毒或无关的内容。现有的强化学习从人工反馈中学习(RLHF)方法在解决这些问题方面有潜力,但整体反馈无法提供有关长文本输出的详细信息,无法指示影响用户偏好的具体部分,例如哪些部分包含何种类型的错误。 -
方法:引入细粒度人工反馈作为明确的训练信号,设计了FINE-GRAINED RLHF框架,该框架在两个方面细化了奖励函数:(1) 密度,为每个段落(如句子)生成后提供奖励;(2) 融合多个与不同反馈类型相关的奖励模型(如事实错误、无关性和信息不完整性)。 -
优势:通过使用细粒度奖励模型进行训练,FINE-GRAINED RLHF实现了在密度和错误类别两个粒度维度上的优化,提高了模型性能,并支持自动评估和人工评估。
介绍了FINE-GRAINED RLHF框架,通过细粒度的人工反馈训练语言模型,并在多个文本生成任务上展示了其在性能和自定义能力方面的优势。
https://arxiv.org/abs/2306.01693

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢