
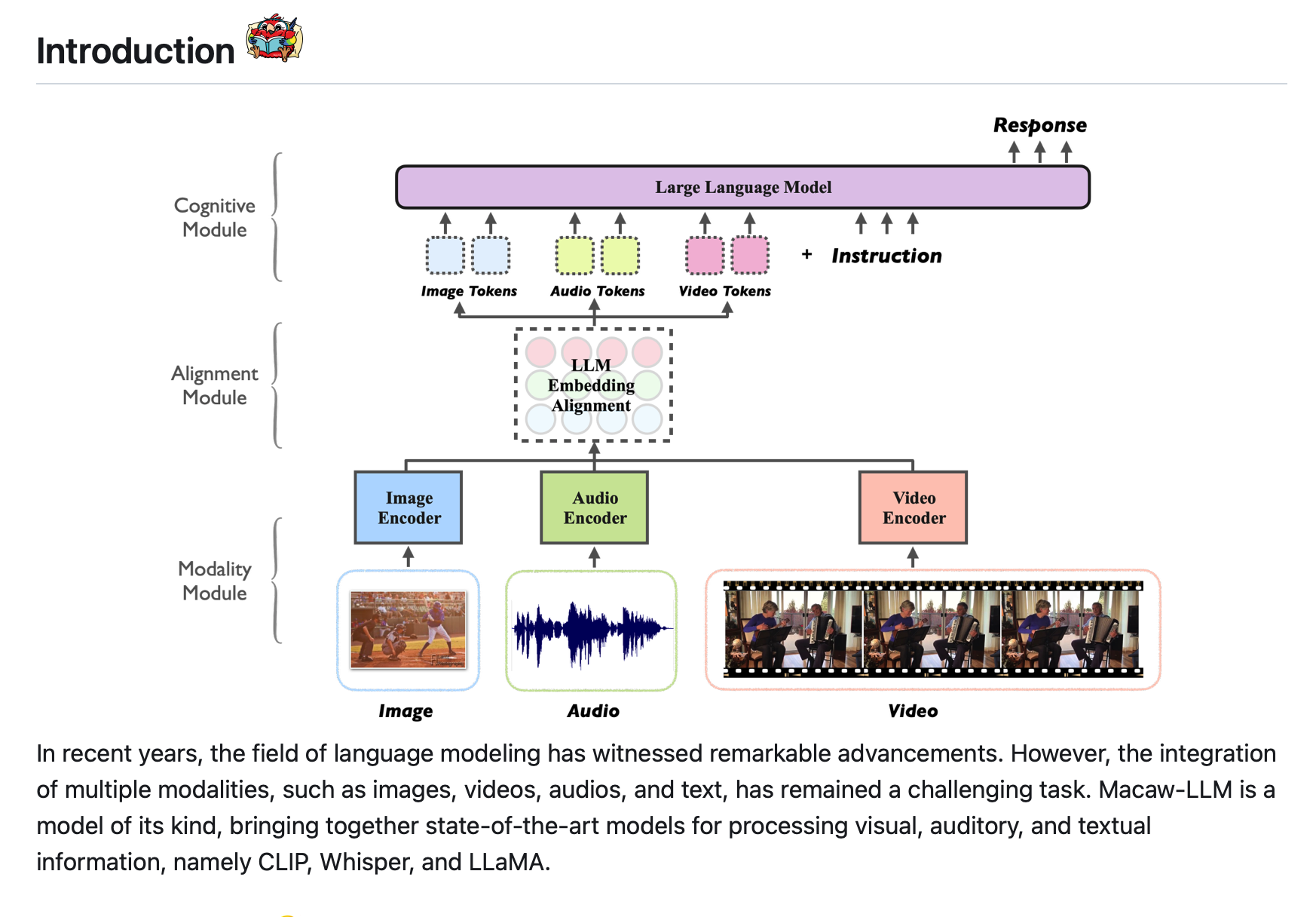
【Macaw-LLM: 一种多模态语言模型,无缝结合图像、视频、音频和文本数据,为语言建模带来突破,集成了CLIP、Whisper和LLaMA等先进模型】
Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration -
Macaw-LLM: Multi-Modal Language Modeling with Image, Video, Audio, and Text Integration' Chenyang Lyu
GitHub: https://github.com/lyuchenyang/Macaw-LLM
论文地址:https://event-cdn.baai.ac.cn/file/file-browser/TTxGEjM5zTJj2aTNDJfWRQ2b6T4NHaFb.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢