
Knowledge Distillation of Large Language Models
Y Gu, L Dong, F Wei, M Huang
[Microsoft Research & Tsinghua University]
大型语言模型知识蒸馏
要点:
-
动机:解决大型语言模型(LLM)的高计算需求问题,通过知识蒸馏(KD)技术减小模型规模。现有的KD方法主要适用于白盒分类模型或训练小模型模仿黑盒模型API(如ChatGPT),如何有效地从白盒生成LLM中蒸馏知识仍然不够充分。
-
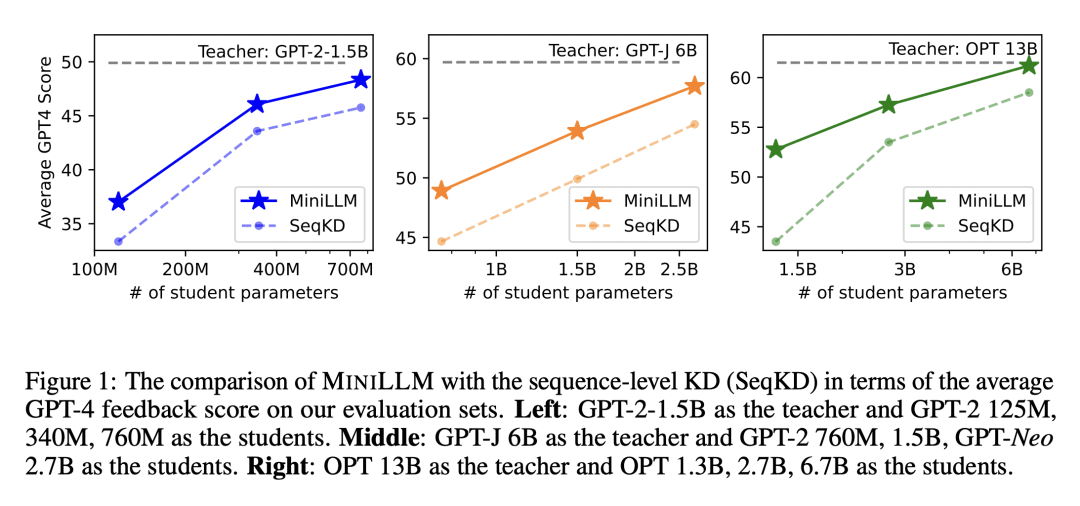
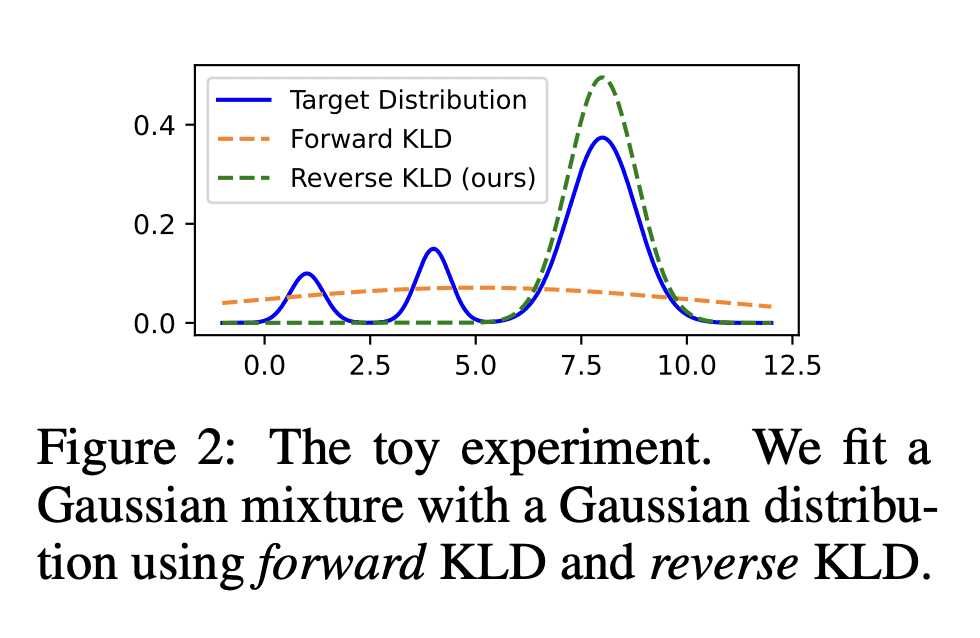
方法:提出名为MINILLM的新方法,能从生成式大型语言模型中蒸馏出较小的语言模型。首先将标准KD方法中的前向Kullback-Leibler散度(KLD)目标替换为更适合在生成语言模型上进行KD的反向KLD,以防止学生模型高估教师分布的低概率区域。然后,推导出一种有效的优化方法来学习此目标。
-
优势:提出一种从生成式LLM中蒸馏较小语言模型的方法,通过改进KD方法,实现了更高的生成质量、更低的暴露偏差、更好的校准性和更高的长文本生成性能。该方法具有可扩展性,适用于不同规模的模型。
提出了一种MINILLM方法,通过改进知识蒸馏方法,实现了从大型语言模型到小型模型的知识传递,提升了生成质量和性能。
https://arxiv.org/abs/2306.08543
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢