
FasterViT: Fast Vision Transformers with Hierarchical Attention
Ali Hatamizadeh, Greg Heinrich, Hongxu Yin, Andrew Tao, Jose M. Alvarez, Jan Kautz, Pavlo Molchanov
[NVIDIA]
FasterViT:基于分层注意力的快速视觉Transformer
要点:
-
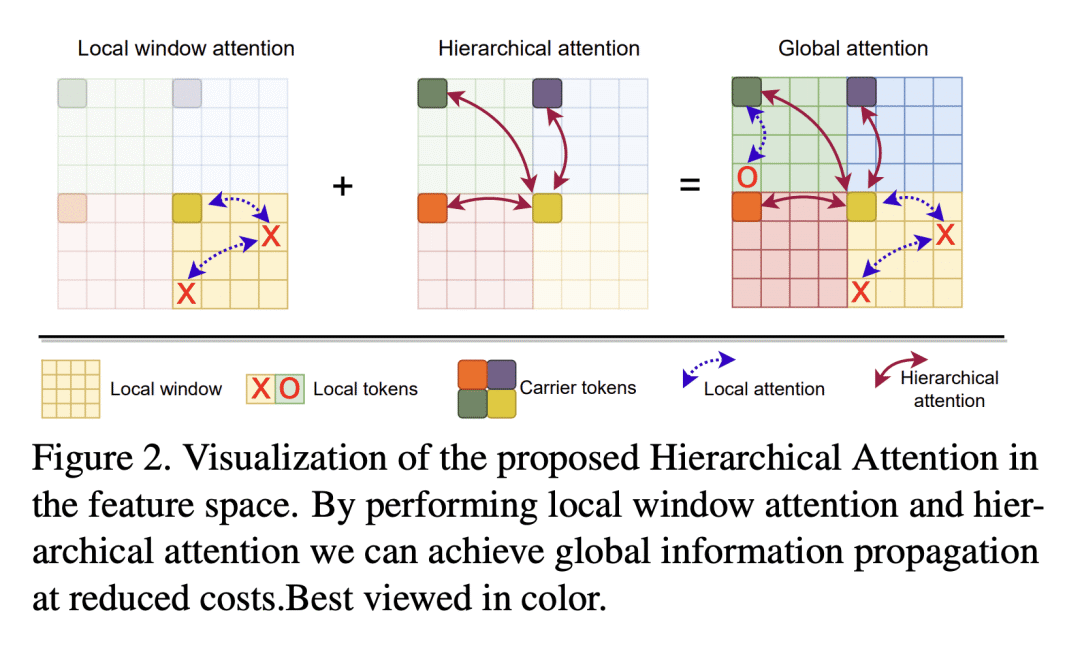
动机:设计一种新的混合CNN-ViT神经网络模型族FasterViT,专注于计算机视觉(CV)应用的高图像吞吐量。FasterViT结合了CNN中快速本地表示学习的优点和ViT中的全局建模属性。新引入的分层注意力(HAT)方法将二次复杂性的全局自注意力分解为具有降低计算成本的多级注意力。 -
方法:FasterViT由四个不同的阶段组成,其中输入图像分辨率通过使用跨步卷积层减小,同时将特征图的数量加倍。所提出在架构的高分辨率阶段(阶段1,2)利用残差卷积块,而在后期阶段(阶段3,4)使用基于Transformer的块。对于每个Transformer块,使用局部和新提出的层次注意力块的交错模式来捕获短距离和长距离的空间依赖性,并有效地建模跨窗口交互。 -
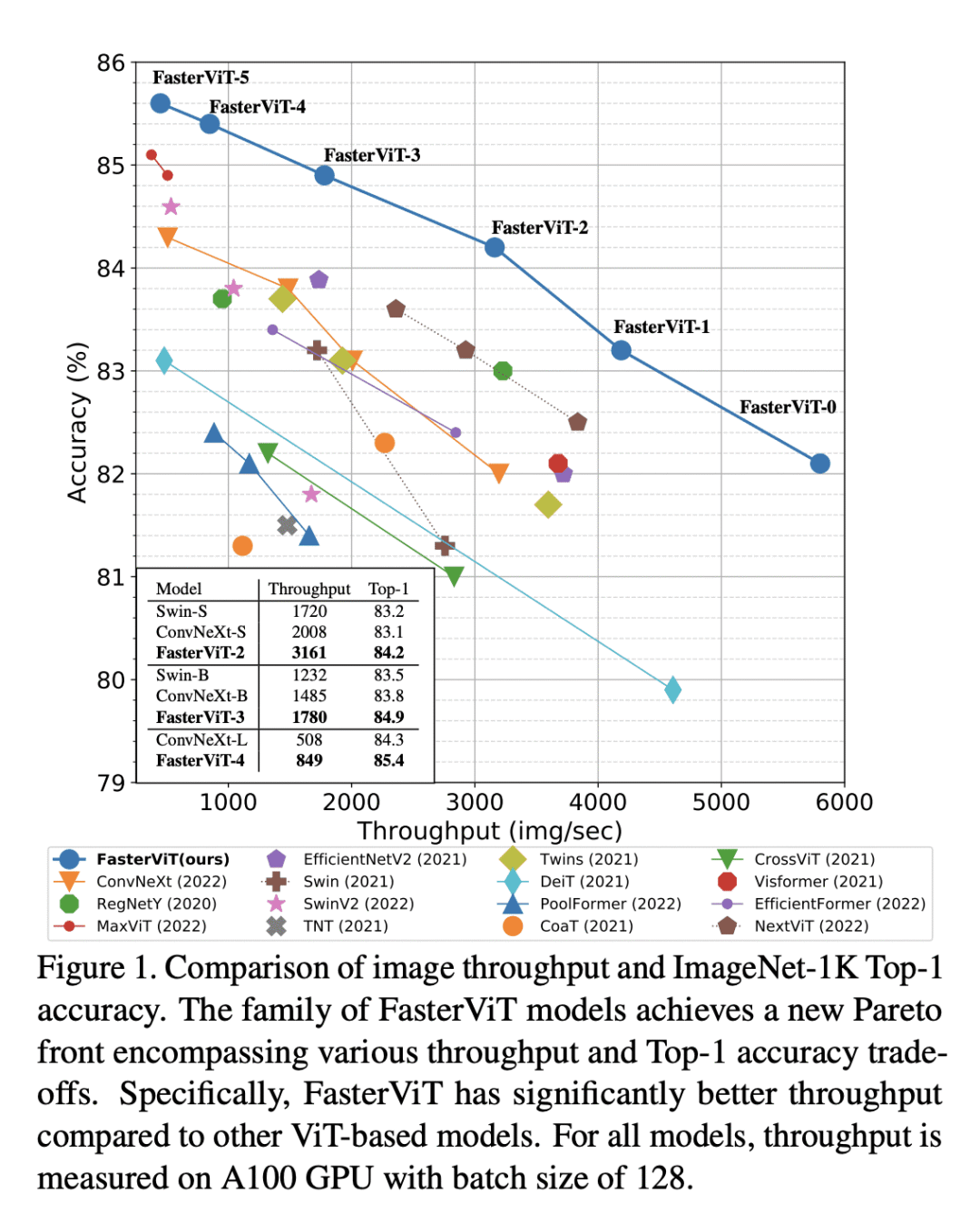
优势:FasterViT在准确性与图像吞吐量方面实现了SOTA的帕累托前沿。已经在各种CV任务(包括分类、目标检测和分割)上广泛验证了其有效性。还展示了HAT可以用作现有网络的即插即用模块并增强它们。展示了比竞争对手更快、更准确的性能,对于高分辨率的图像。
FasterViT是一种新的混合CNN-ViT神经网络,通过引入分层注意力方法,有效地结合了CNN的快速本地表示学习和ViT的全局建模特性,实现了高图像吞吐,提高了计算机视觉任务的效率和准确性。
https://arxiv.org/abs/2306.06189
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢