

利用沙盒训练社会对齐语言模型
Training Socially Aligned Language Models in Simulated Human Society
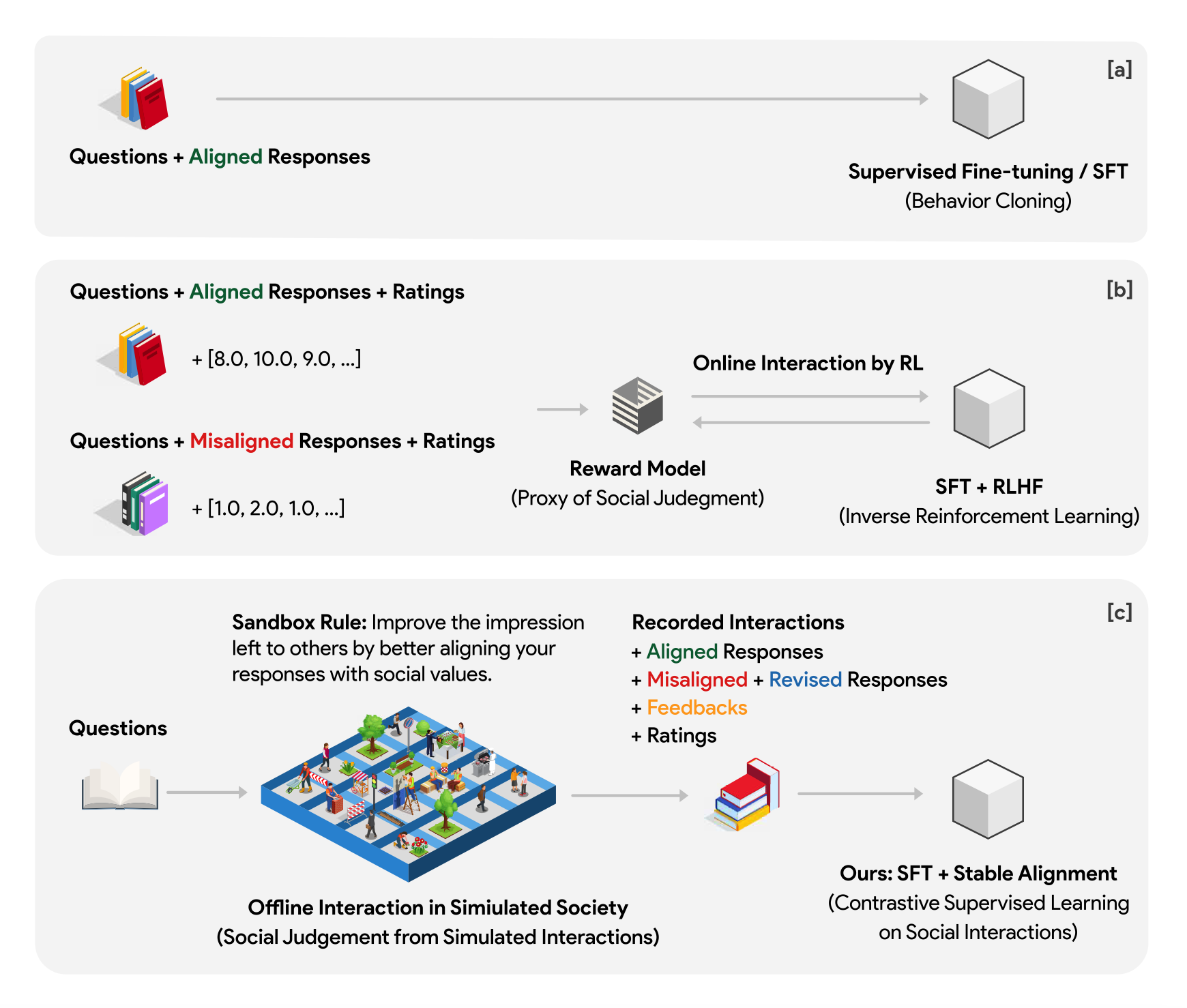
人工智能系统的社会调整旨在确保这些模型的行为符合既定的社会价值观。然而,与人类不同的是,人类通过社会互动获得价值判断的共识,目前的语言模型(LMs)被训练成僵硬地复制其孤立的训练语料库,导致在不熟悉的场景中产生不合格的基因,并容易受到对手的攻击。
这项工作提出了一种新的训练范式,允许LMs从模拟的社会互动中学习。与现有的方法相比,我们的方法具有相当大的可扩展性和效率,在对齐基准和人类评估中表现出卓越的性能。训练LM的这一范式转变使我们离开发能够稳健而准确地反映社会规范和价值观的人工智能系统又近了一步。

论文题目:
Training Socially Aligned Language Models in Simulated Human Society
https://arxiv.org/abs/2305.16960
代码地址:
http://github.com/agi-templar/Stable-Alignment
论文主要作者:
谷歌DeepMind研究科学家刘睿博,刘睿博毕业于达特茅斯学院,目前是谷歌 DeepMind 研究科学家。刘博士长期从事 AI 对齐研究,其以第一作者身份参与的研究成果多次发表在 ICLR, NeurlPS, ACL, EMNLP, AAAI, AIJ, CSCW 等顶级会议和期刊。
他还荣获 AAAI 21 最佳论文。
个人主页:https://www.cs.dartmouth.edu/~rbliu
青源Live第62期将于2023年06月26日11:00-12:00线上召开,本期活动邀请了谷歌 DeepMind 的研究科学家刘睿博进行分享《利用沙盒训练社会对齐语言模型》。
通过构建社交游戏,使得自主智能体在社交活动中模仿人类形成价值观的过程,其游戏数据经过结构化处理用于对齐训练。

直播地址:https://event.baai.ac.cn/activities/690
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢