
Scaling Open-Vocabulary Object Detection
Matthias Minderer, Alexey Gritsenko, Neil Houlsby
[Google DeepMind]
扩展开放词目标检测
-
动机:开放词表目标检测已经从预训练的视觉-语言模型中受益良多,但仍受限于可用的检测训练数据的数量。虽然可以通过使用网络图像-文本对作为弱监督来扩展检测训练数据,但这还没有在与图像级预训练相当的规模上进行。因此,本文提出一种扩大检测数据的方法,即自训练,使用现有的检测器在图像-文本对上生成伪框标注。 -
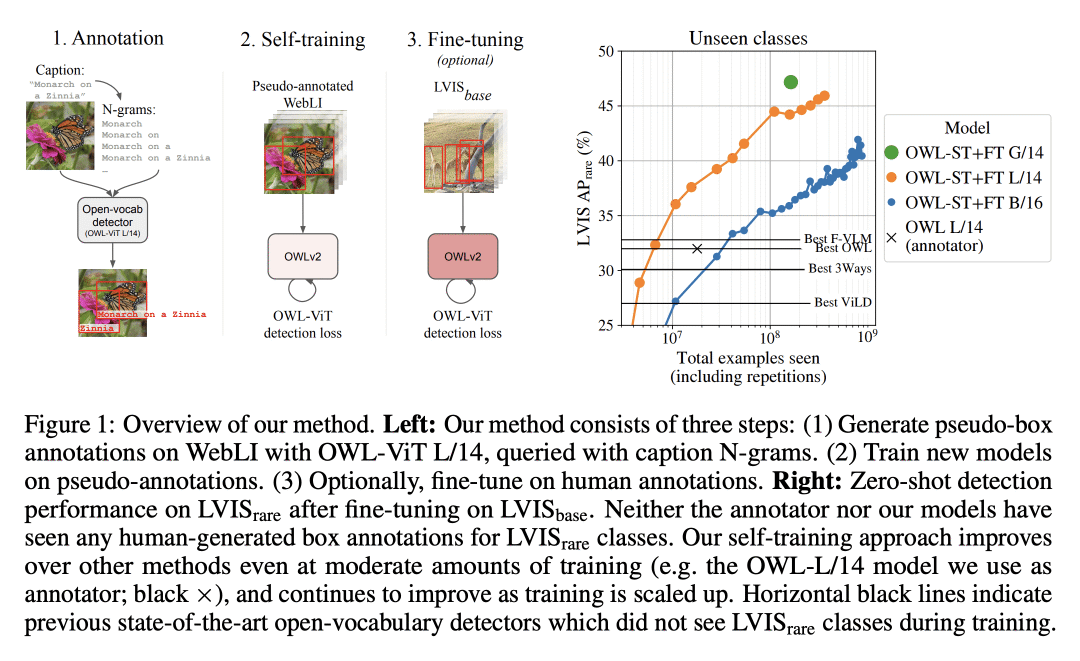
方法:提出OWLv2模型和OWL-ST自训练方案,以解决自训练中的主要挑战,包括标签空间的选择、伪标注过滤和训练效率。OWLv2在相当的训练规模(≈10M示例)上就已经超越了之前的最先进的开放词表检测器的性能。然而,通过OWL-ST,可以扩展到超过10亿个示例,从而进一步大幅提高性能。 -
优势:使用OWL-ST,可以扩展到超过10亿个示例,从而进一步大幅提高性能。例如,使用L/14架构的OWL-ST,可以将LVIS稀有类别的AP从31.2%提高到44.6%(相对提高43%),而这些模型没有看到过人工的框标注。OWL-ST为开放世界定位解锁了Web规模的训练,类似于图像分类和语言建模所见。
提出一种新的自训练方法OWL-ST和模型OWLv2,通过扩大检测数据,提高了开放词表目标检测的性能,并解锁了Web规模的训练。
https://arxiv.org/abs/2306.09683
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢