
加州大学伯克利分校的研究者开源了一个项目 vLLM,该项目主要用于快速 LLM 推理和服务。vLLM 的核心是 PagedAttention,这是一种新颖的注意力算法,它将在操作系统的虚拟内存中分页的经典思想引入到 LLM 服务中。
配备了 PagedAttention 的 vLLM 将 LLM 服务状态重新定义:它比 HuggingFace Transformers 提供高达 24 倍的吞吐量,而无需任何模型架构更改。

vLLM 具有如下特点:
最先进的服务吞吐量;
PagedAttention 可以有效的管理注意力的键和值;
动态批处理请求;
优化好的 CUDA 内核;
与流行的 HuggingFace 模型无缝集成;
高吞吐量服务与各种解码算法,包括并行采样、beam search 等等;
张量并行以支持分布式推理;
流输出;
兼容 OpenAI 的 API 服务。
vLLM 还可以无缝支持许多 Huggingface 模型,包括以下架构:
-
GPT-2 (gpt2、gpt2-xl 等);
-
GPTNeoX (EleutherAI/gpt-neox-20b、databricks/dolly-v2-12b、stabilityai/stablelm-tuned-alpha-7b 等);
-
LLaMA (lmsys/vicuna-13b-v1.3、young-geng/koala、openlm-research/open_llama_13b 等)
-
OPT (facebook/opt-66b、facebook/opt-iml-max-30b 等)。
值得一提的是,vLLM 已被部署在 Chatbot Arena 和 Vicuna 中。项目作者之一 Zhuohan Li 表示,自发布以来,vLLM 一直是 Chatbot Arena 和 Vicuna Demo 背后的无名英雄,它能处理高峰流量并高效地为流行模型提供服务。它已将 LMSYS(一个开放的研究组织,旨在让每个人都能访问大型模型) 使用的 GPU 数量减少了一半,同时每天平均处理 30K 次对话。
vLLM 性能如何?
该研究将 vLLM 的吞吐量与最流行的 LLM 库 HuggingFace Transformers (HF),以及之前具有 SOTA 吞吐量的 HuggingFace Text Generation Inference(TGI)进行了比较。此外,该研究将实验设置分为两种:LLaMA-7B,硬件为 NVIDIA A10G GPU;另一种为 LLaMA-13B,硬件为 NVIDIA A100 GPU (40GB)。他们从 ShareGPT 数据集中采样输入 / 输出长度。结果表明,vLLM 的吞吐量比 HF 高 24 倍,比 TGI 高 3.5 倍。
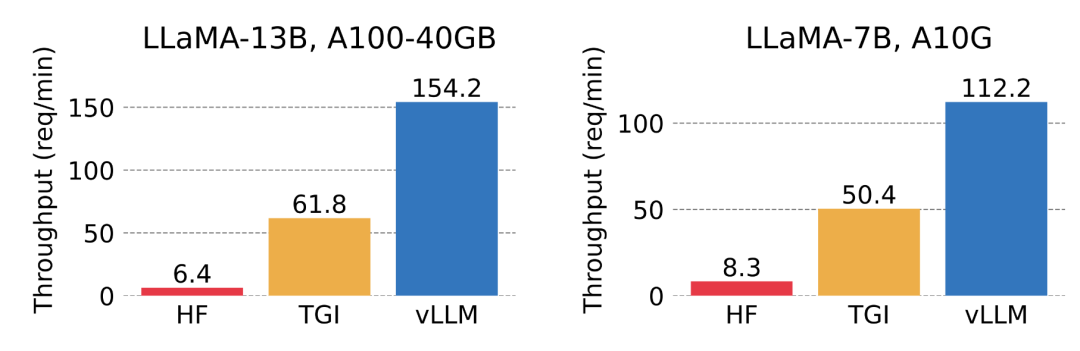
vLLM 的吞吐量比 HF 高 14 倍 - 24 倍,比 TGI 高 2.2 倍 - 2.5 倍。
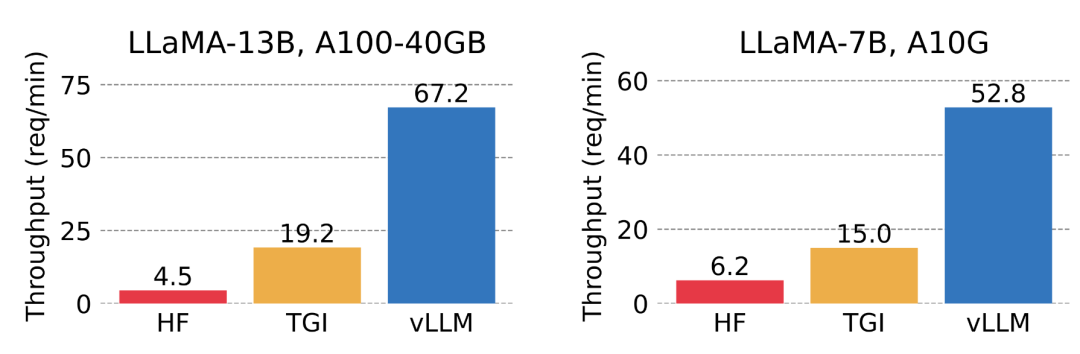
vLLM 的吞吐量比 HF 高 8.5 - 15 倍,比 TGI 高 3.3 - 3.5 倍。
PagedAttention:解决内存瓶颈
该研究发现,在 vLLM 库中 LLM 服务的性能受到内存瓶颈的影响。在自回归解码过程中,所有输入到 LLM 的 token 会产生注意力键和值的张量,这些张量保存在 GPU 内存中以生成下一个 token。这些缓存键和值的张量通常被称为 KV 缓存,其具有:
-
内存占用大:在 LLaMA-13B 中,缓存单个序列最多需要 1.7GB 内存;
-
动态且不可预测:KV 缓存的大小取决于序列长度,这是高度可变和不可预测的。因此,这对有效地管理 KV 缓存挑战较大。该研究发现,由于碎片化和过度保留,现有系统浪费了 60% - 80% 的内存。
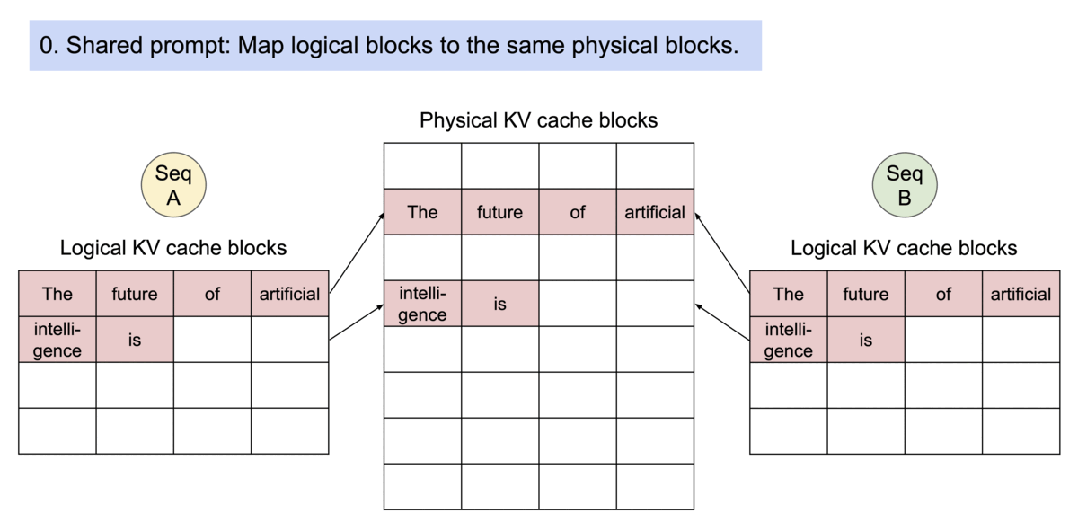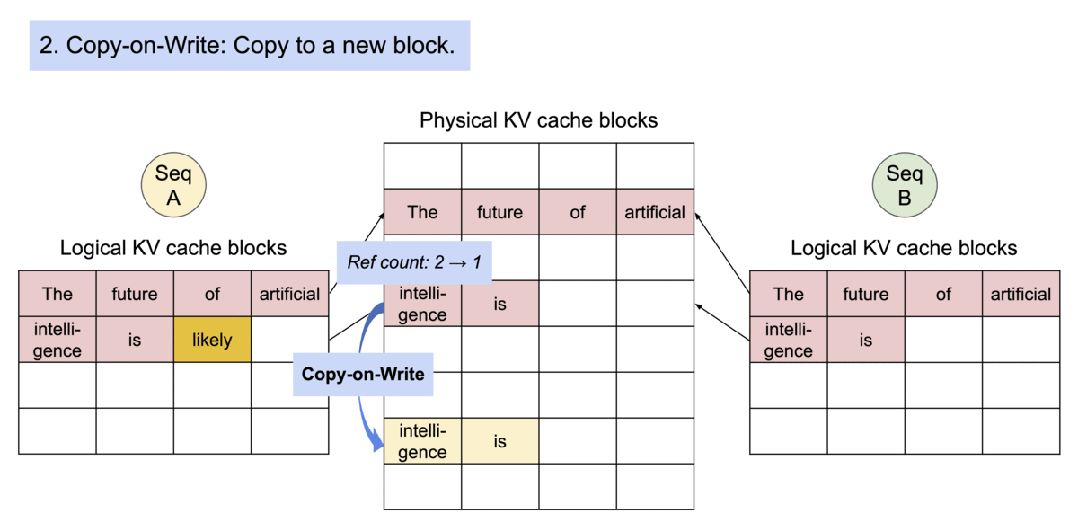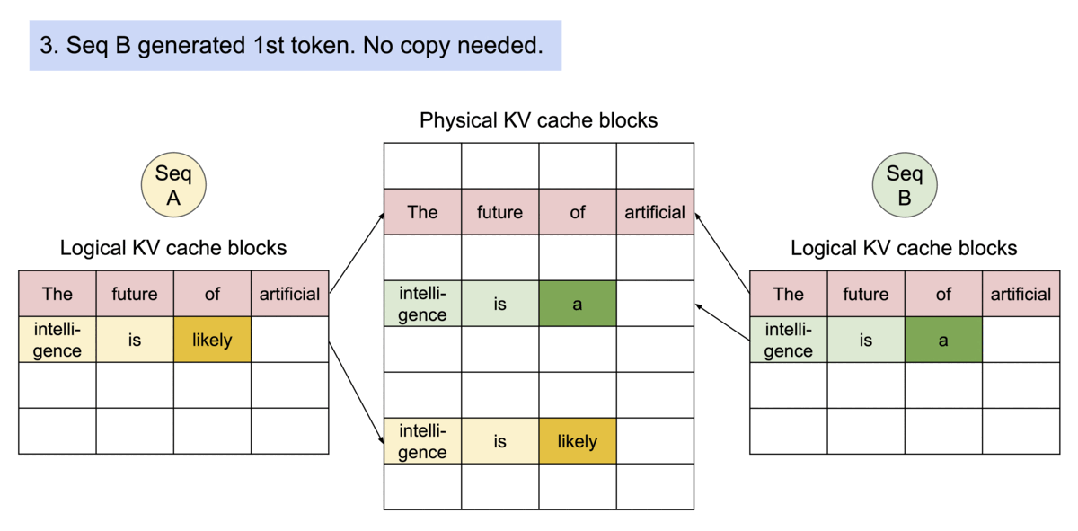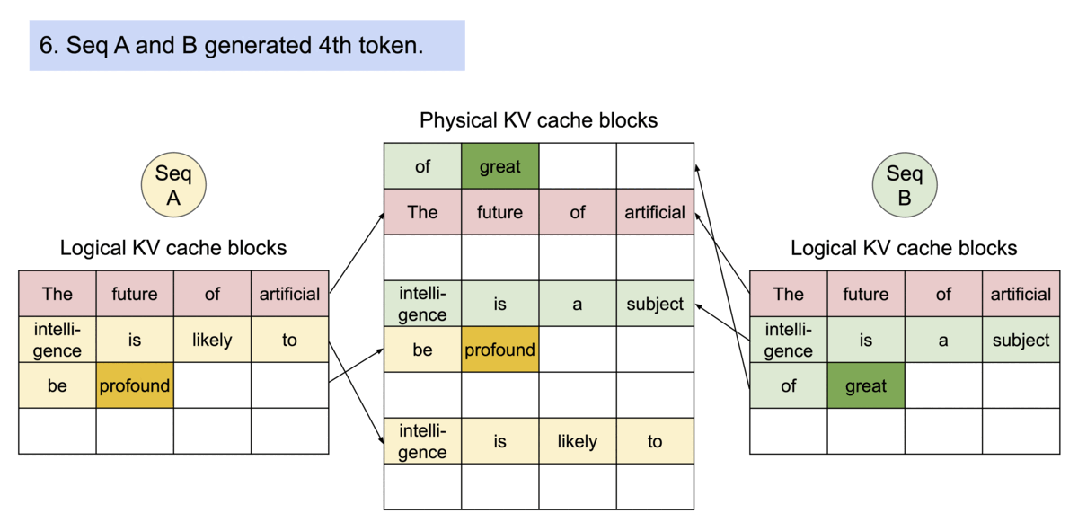
为了解决这个问题,该研究引入了 PagedAttention,这是一种受操作系统中虚拟内存和分页经典思想启发的注意力算法。与传统的注意力算法不同,PagedAttention 允许在非连续的内存空间中存储连续的键和值。具体来说,PagedAttention 将每个序列的 KV 缓存划分为块,每个块包含固定数量 token 的键和值。在注意力计算期间,PagedAttention 内核可以有效地识别和获取这些块。
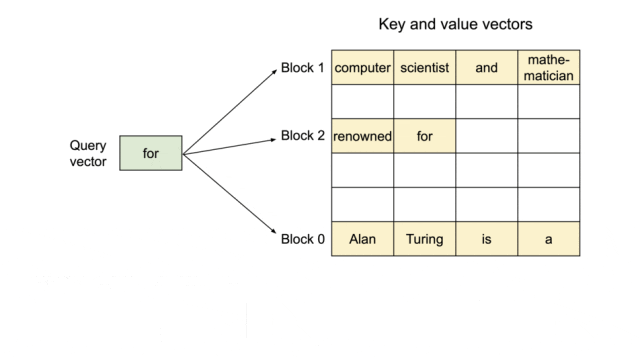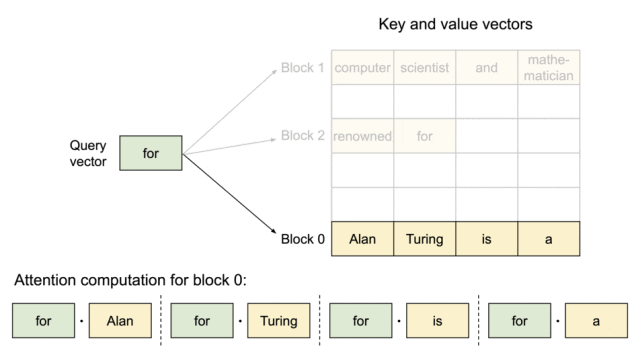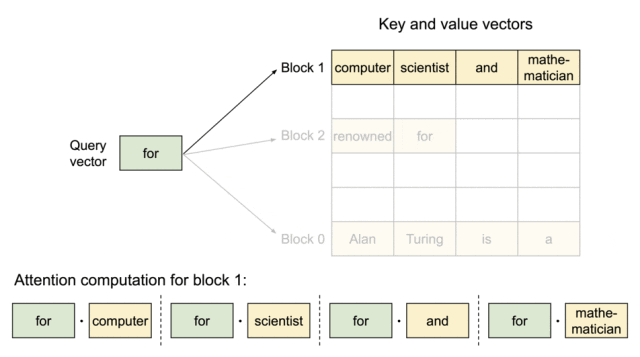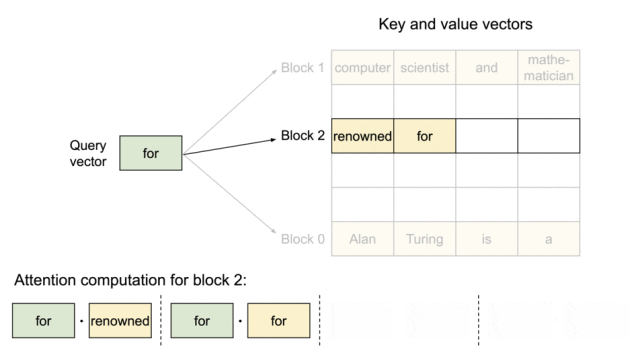
PagedAttention:KV 缓存被划分成块,块不需要在内存空间中连续。
因为块在内存中不需要连续,因而可以用一种更加灵活的方式管理键和值,就像在操作系统的虚拟内存中一样:可以将块视为页面,将 token 视为字节,将序列视为进程。序列的连续逻辑块通过块表映射到非连续物理块中。物理块在生成新 token 时按需分配。
使用 PagedAttention 的请求的示例生成过程。
在 PagedAttention 中,内存浪费只会发生在序列的最后一个块中。这使得在实践中可以实现接近最佳的内存使用,仅浪费不到 4 %。这种内存效率的提升被证明非常有用,允许系统将更多序列进行批处理,提高 GPU 使用率,显著提升吞吐量。
PagedAttention 还有另一个关键优势 —— 高效的内存共享。例如在并行采样中,多个输出序列是由同一个提示(prompt)生成的。在这种情况下,提示的计算和内存可以在输出序列中共享。
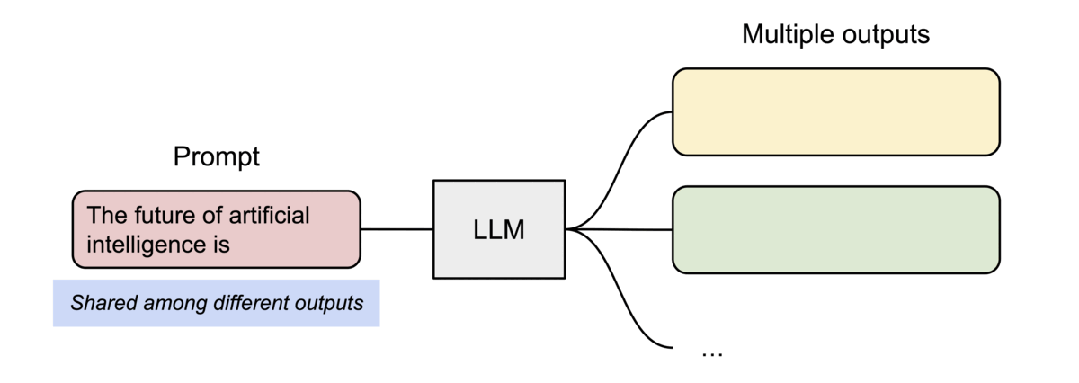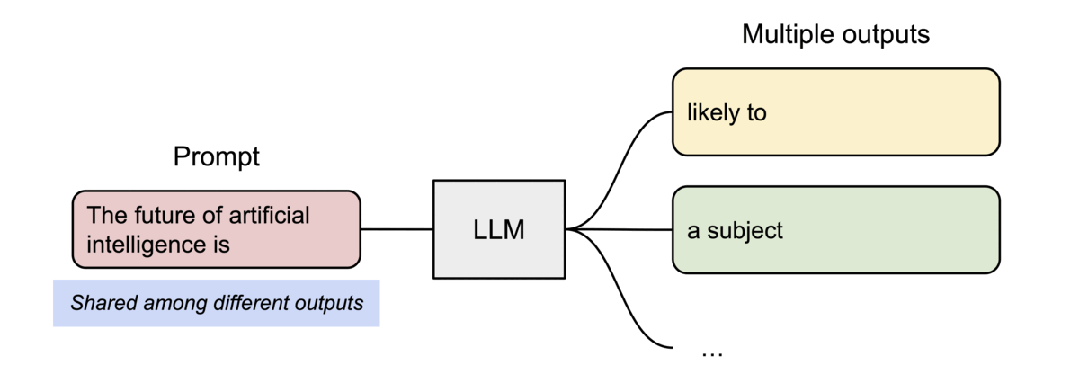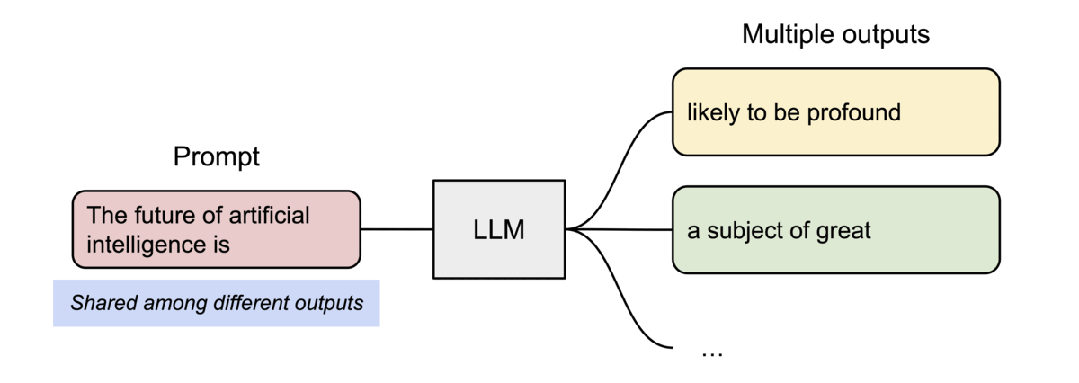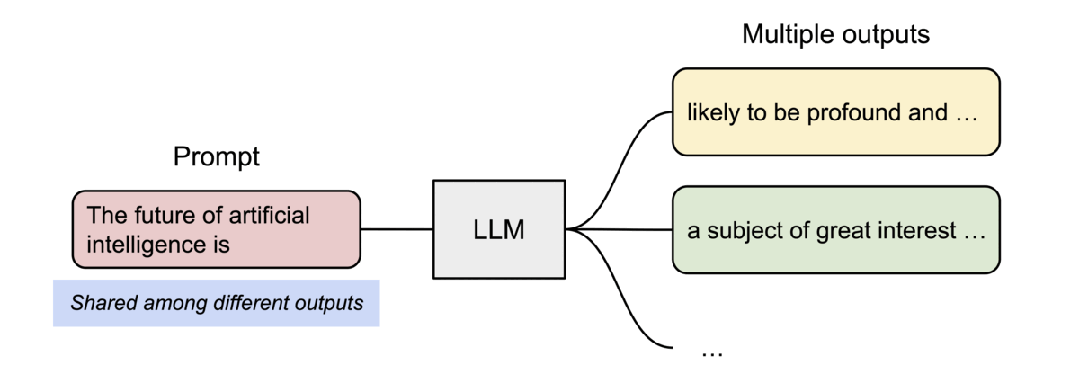
并行采样示例。
PagedAttention 自然地通过其块表格来启动内存共享。与进程共享物理页面的方式类似,PagedAttention 中的不同序列可以通过将它们的逻辑块映射到同一个物理块的方式来共享块。为了确保安全共享,PagedAttention 会对物理块的引用计数进行跟踪,并实现写时复制(Copy-on-Write)机制。
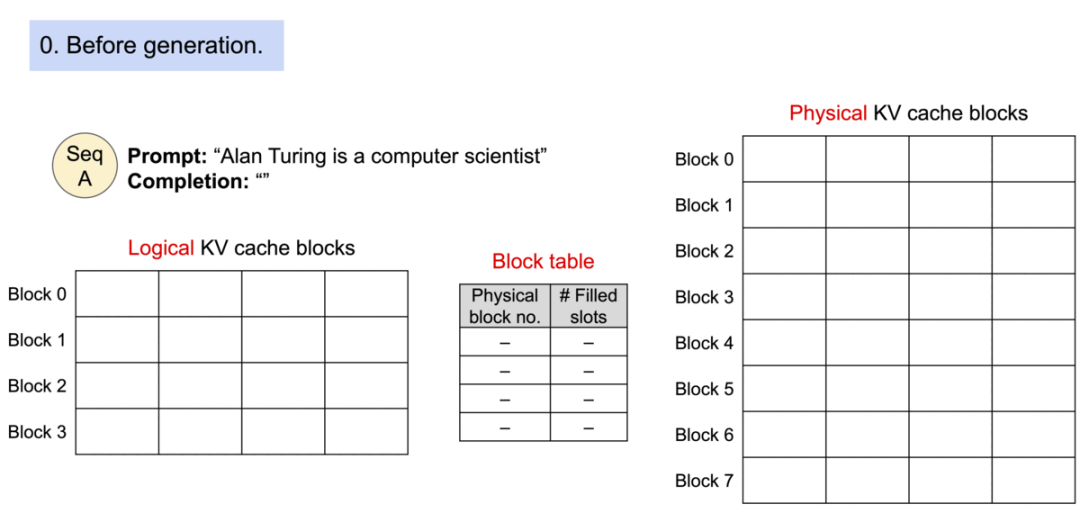
对于对多输出进行采样的请求,它的示例生成过程是这样的。
PageAttention 的内存共享大大减少了复杂采样算法的内存开销,例如并行采样和集束搜索的内存使用量降低了 55%。这可以转化为高达 2.2 倍的吞吐量提升。这种采样方法也在 LLM 服务中变得实用起来。
PageAttention 成为了 vLLM 背后的核心技术。vLLM 是 LLM 推理和服务引擎,为各种具有高性能和易用界面的模型提供支持。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢