
LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
Dongfu Jiang, Xiang Ren, Bill Yuchen Lin
[Zhejiang University & University of Southern California & Allen Institute for Artificial Intelligence]
LLM-Blender: 用成对排序和生成融合集成大型语言模型
-
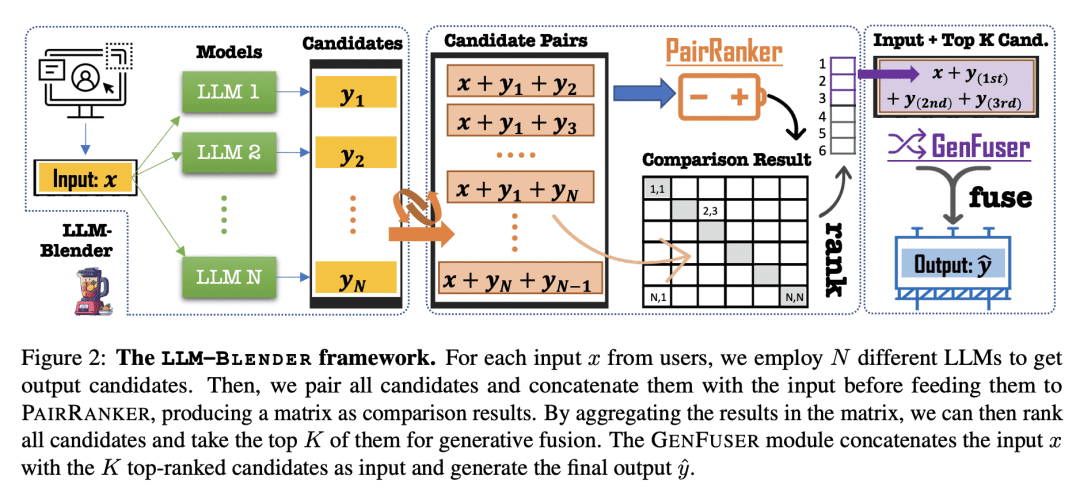
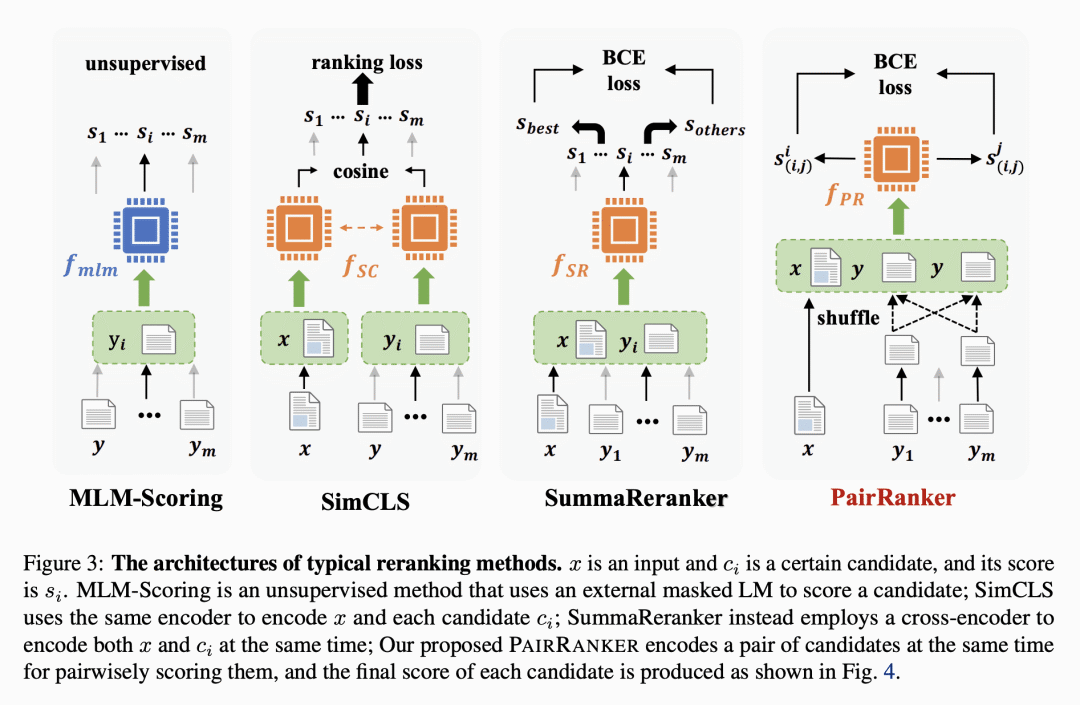
方法:LLM-BLENDER框架由两个模块组成:PAIRRANKER和GENFUSER。首先,PAIRRANKER比较来自N个LLM的输出,然后GENFUSER将这些输出融合以生成最终的输出。PAIRRANKER采用一种专门的成对比较方法,通过联合编码输入文本和一对候选项,使用交叉注意力编码器来确定哪一个更优。然后,GENFUSER旨在合并排名最高的候选项,通过利用他们的优点并减轻他们的弱点来生成改进的输出。 -
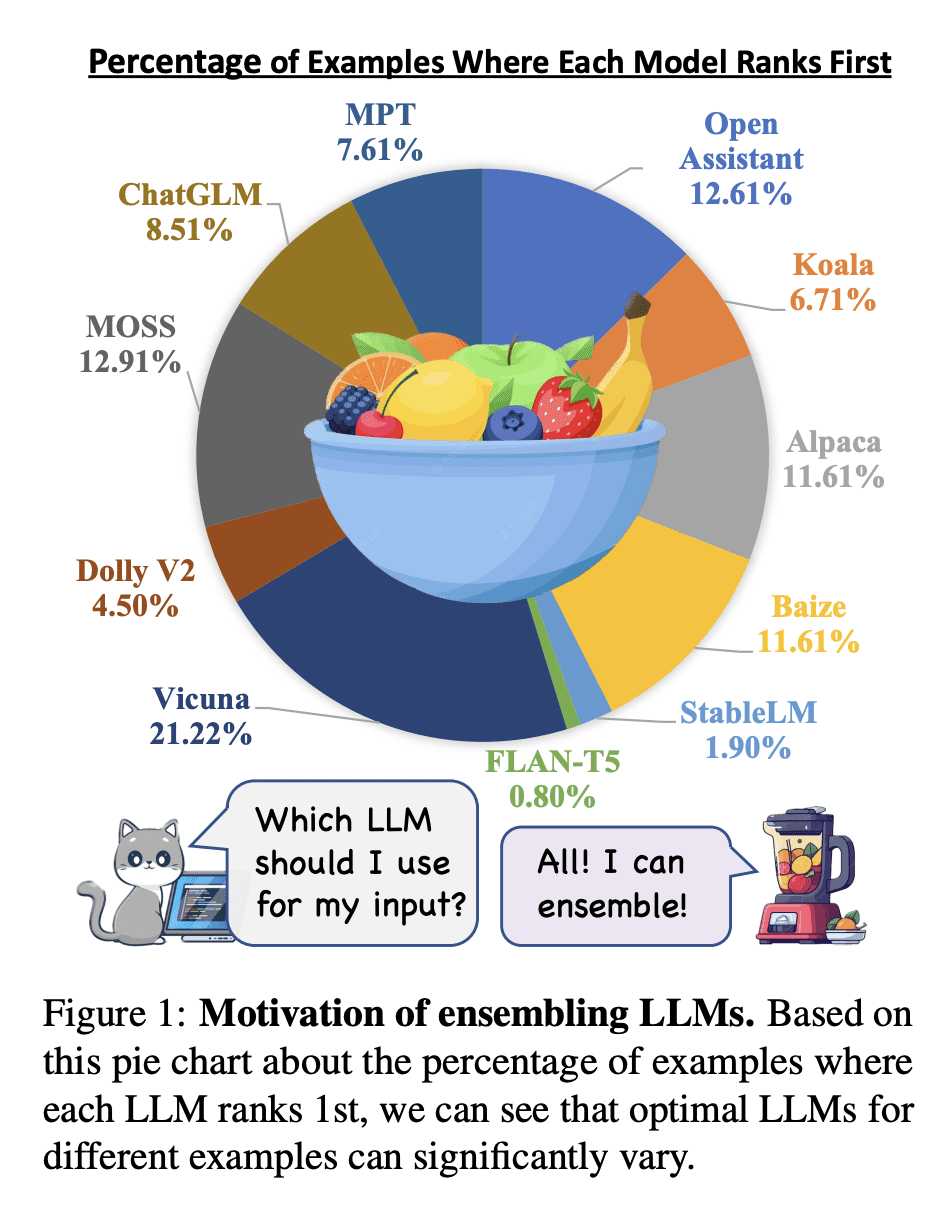
优势:LLM-BLENDER框架通过集成LLM显著提高了整体性能。PAIRRANKER的选择超过了任意固定的个体LLM模型,如通过在参考基准和GPT-Rank中的优越性能所示。通过利用PAIRRANKER的顶级选择,GENFUSER通过有效的融合进一步提高了响应质量。LLM-BLENDER在传统指标(即BERTScore,BARTScore,BLUERT)和基于ChatGPT的排名方面都取得了最高分。
提出一种新的大型语言模型集成框架LLM-BLENDER,通过使用专门的成对比较方法PAIRRANKER和生成融合方法GENFUSER,有效地利用了不同模型的优点,提高了模型的整体性能。
https://arxiv.org/abs/2306.02561
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢