
AudioPaLM: A Large Language Model That Can Speak and Listen
P K. Rubenstein, C Asawaroengchai, D D Nguyen, A Bapna, Z Borsos, F d C Quitry...
[Google]
AudioPaLM:能说能听的大型语言模型
-
动机:大型语言模型(LLM)在生成文本任务中表现出色,例如开放域问答或少样本机器翻译。然而,这些模型主要关注文本,可能会忽视语音中的重要信息。因此,本文提出AudioPaLM,一个大型的语音理解和生成模型,将基于文本的和基于语音的语言模型融合到一个统一的多模态架构中。 -
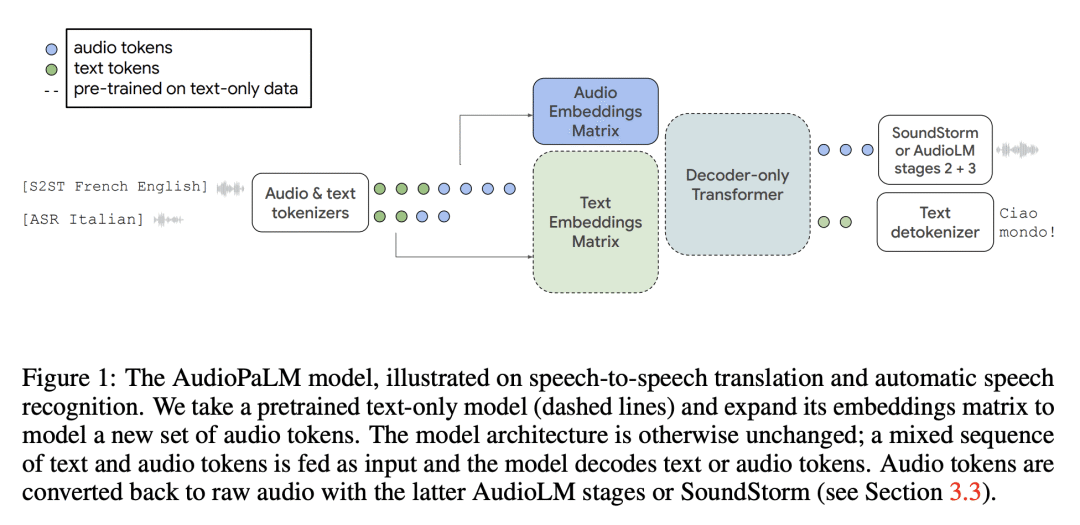
方法:AudioPaLM的核心,是一个可以表示语音和文本的联合词表,可以用有限数量的离散Token来表示,这使得可以在涉及任意交错的语音和文本的任务混合中训练一个单一的解码器模型。这包括语音识别、文本到语音合成和语音到语音翻译,将传统上由异构模型解决的任务统一到一个单一的架构和训练运行中。 -
优势:AudioPaLM在语音翻译任务上显著优于现有系统,并且具有执行许多在训练中未见过的输入/目标语言组合的零样本语音到文本翻译的能力。此外,AudioPaLM还展示了音频语言模型的特性,例如根据短语音提示在语言之间转换声音。
介绍了AudioPaLM,一个大型的语音理解和生成模型,将基于文本的和基于语音的语言模型融合到一个统一的多模态架构中,具有执行许多在训练中未见过的输入/目标语言组合的零样本语音到文本翻译的能力。
https://arxiv.org/abs/2306.12925
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢