

Language to Rewards for Robotic Skill Synthesis
Wenhao Yu, Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Jan Humplik, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng, Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan, Yuval Tassa, Fei Xia
[Google DeepMind]
面向机器人技能合成的语言到奖励转换
-
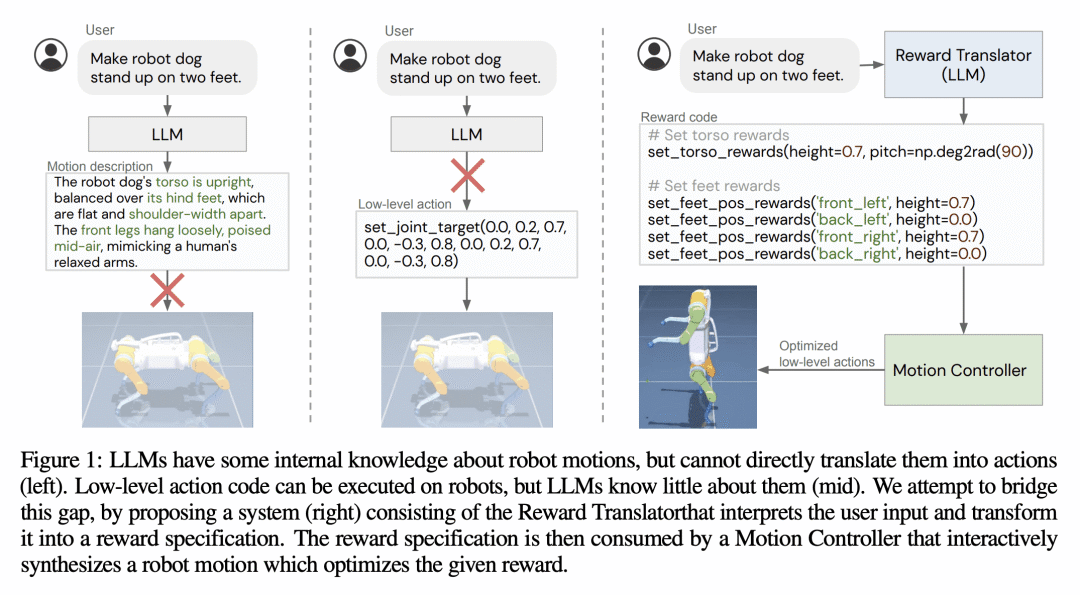
动机:大型语言模型(LLM)在通过上下文学习获取各种新能力方面取得了令人兴奋的进步,从逻辑推理到编写代码。然而,由于低级别的机器人行为是硬件依赖的,并且在LLM训练语料库中代表性不足,因此将LLM应用到机器人技术的现有努力大多将LLM视为语义规划器,或依赖人工设计的控制原语来与机器人进行交互。本文提出一种新的范式,通过利用LLM来定义可以优化的奖励参数,以完成各种机器人任务。 -
方法:引入一种新范式,通过利用LLM来定义可以优化的奖励参数,以完成各种机器人任务。使用LLM生成的奖励作为中间接口,可以有效地将高级语言指令或更正转化为低级机器人行为。同时,将这个方法与实时优化器MuJoCo MPC结合,可以实现交互式行为创建体验,用户可以立即观察结果并向系统提供反馈。 -
优势:该方法可靠地解决了90%的设计任务,而使用原始技能作为接口的基线只能完成50%的任务。此外,该方法还在真实的机器人手臂上进行了验证,通过所提出的交互系统,复杂的操纵技能如非抓取推动等可以自然地出现。
提出了一种新范式,通过利用大型语言模型(LLM)来定义可以优化的奖励参数,以完成各种机器人任务,实现了从高级语言指令到低级机器人行为的有效桥接。
https://arxiv.org/abs/2306.08647

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢